







Attention
Attention是一种机制,可以应用到许多不同的模型中,像CNN、RNN、seq2seq等。Attention通过权重给模型赋予了区分辨别的能力,从而抽取出更加关键及重要的信息,使模型做出更加准确的判断,同时不会对模型的计算和存储带来更大的开销。
基本的Attention原理
下面通过seq2seq模型中的Attention介绍Attention的原理。
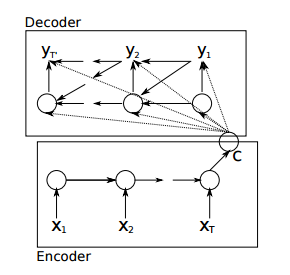
seq2seq是RNN的一种变体,其不限制输入和输出的长度,是一种Encoder-Decoder的结构。未引入attention机制的seq2seq的结构如图
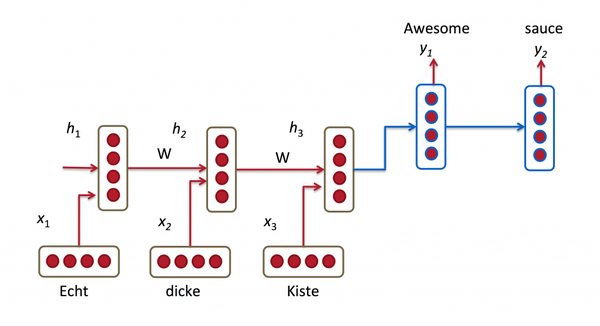
简化图如下
上图展示了将德语翻译成英语时的模型结构。encoder RNN(红色) 将输入语句信息编码到最后一个hidden vector中,并将其作为decoder(蓝色)初始的hidden vector,利用decoder解码成对应的其他语言中的文字。
但对于较长的序列输入,由于长程梯度问题,最后的hidden vector不能保持所有的有效信息。通过引入attention机制,解决了长序列到定长向量转化时信息损失的瓶颈。引入attention机制后的动态图如下

下面给出数学上的运算过程
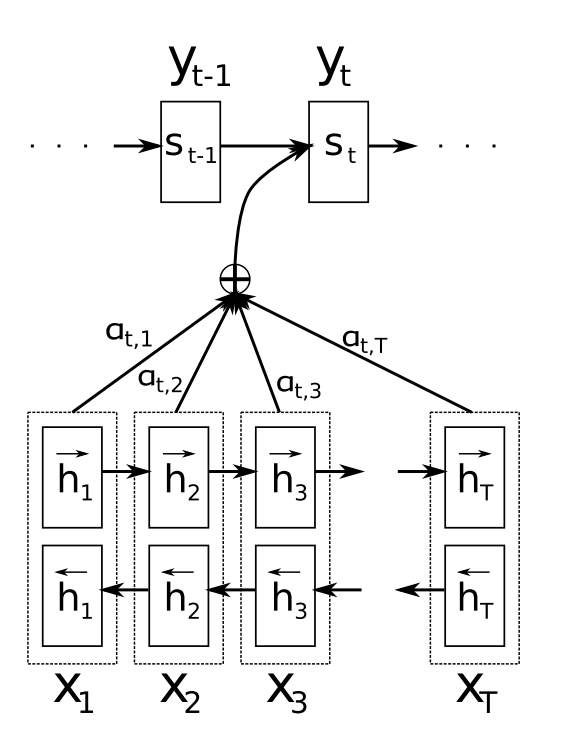
首先通过输入获得encoder中的隐状态
接着计算每一个encoder的隐状态与decoder中各个时刻的隐状态的关联性。现考虑decoder中t-1时刻的隐状态与encoder中每一个隐状态j的关联性。
即,写成相应的向量形式
。其中a是一种相关性的算符,例如常见的有点乘形式
,加权点乘
,加和
等等。
然后对 进行softmax操作将其normalize得到attention的分布,即
,展开形式为
再然后利用求得的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









