







文章目录
-
监督学习
- 监督学习需要标注数据,学习一个可靠的模型需要大量标注数据
- 但是标注数据费时费力!
-
无标注数据可以做什么?–>可以给出更有意义的分类边界
- 同一类样本服从一致的分布
-
半监督学习:让学习器不依赖外界交互、自动地利用无标注数据提升学习性能
- 半监督分类/回归
- 给定: 标注数据 𝐷 = { 𝑥1, 𝑦1 , 𝑥2, 𝑦2 … (𝑥l, 𝑦l)},无标注数据 𝐷𝑢 = {𝑥l+1, 𝑥l+2, … 𝑥l+𝑢}(通常 𝑢 ≫ l)
- 目标: 学习一个分类器 f ,比只用标注数据学的更好
- 半监督聚类/降维
- 给定: 标注数据 {𝑥𝑖}𝑚, 目的是聚类或者降维。另外给出: 对数据的一些限制
- 例如, 对于聚类: 两个点必须在一个簇, 或两个点一定不能在一个簇; 对于降维:两个点降维后必须接近
- 归纳学习 (Inductive learning):开放世界
- 给训练数据𝐷 = { 𝑥1, 𝑦1 , 𝑥2, 𝑦2 … (𝑥𝑙, 𝑦𝑙)}, 无标注数据 𝐷𝑢 = 𝑥𝑙+1, 𝑥𝑙+2, … 𝑥𝑙+𝑢 通常𝑢 ≫ 𝑙
- 学习函数f用于预测新来的测试数据的标签
- 学习一个函数能够被应用到测试数据上
- 直推学习(Transductive learning):封闭世界
- 给定训练数据 𝐷 = { 𝑥1, 𝑦1 , 𝑥2, 𝑦2 … (𝑥𝑙, 𝑦𝑙)}, 无标注数据𝐷𝑢 = 𝑥𝑙+1, 𝑥𝑙+2, … 𝑥𝑙+𝑢
- 可以没有显式地学习函数,我们所关心的就是在𝐷𝑢上的预测
- 𝐷𝑢是测试集,并且在训练时可以使用
- 半监督分类/回归
-
图方法
| 目标函数 | 备注 | |
|---|---|---|
| 最小割 | m i n f ∞ Σ i = 1 l ( y i − Y l i ) 2 + Σ i j w i j ( y i − y j ) 2 min_f\infty\Sigma_{i=1}^l(y_i-Y_{li})^2+\Sigma_{ij}w_{ij}(y_i-y_j)^2 minf∞Σi=1l(yi−Yli)2+Σijwij(yi−yj)2 | — |
| 调和函数之自我训练 | E ( f ) = Σ i − j w i j ( y i − y j ) 2 f ( x i ) = Σ j − i w i j f ( x j ) Σ j − i w i j , 任 意 x i ∈ X u E(f)=\Sigma_{i-j}w_{ij}(y_i-y_j)^2\\f(x_i)=\frac{\Sigma_{j-i}w_{ij}f(x_j)}{\Sigma_{j-i}w_{ij}},任意x_i\in X_u E(f)=Σi−jwij(yi−yj)2f(xi)=Σj−iwijΣj−iwijf(xj),任意xi∈Xu,迭代至收敛 | 固定已有标注,如果标注存在错误怎么办?想要更灵活,希望偶尔不服从给定的标注 |
| 调和函数之拉普拉斯 | m i n f ∞ Σ i = 1 l ( y i − f ( x i ) ) 2 + f T L f min_f\infty\Sigma_{i=1}^l(y_i-f(x_i))^2+f^TLf minf∞Σi=1l(yi−f(xi))2+fTLf,迭代至收敛 | 他不能够处理新的测试数据,仅在Xu上,来新的了要重新算 |
| 局部和全局一致性的方法 | S = − D − 1 / 2 W D − 1 / 2 , 其 中 D − 1 / 2 = d i a g ( 1 d 1 , 1 d 2 , . . . , 1 d l + u ) 迭 代 计 算 公 式 : F ( t + 1 ) = α S F ( t ) + ( 1 − α ) Y 收 敛 后 F ∗ = l i m t → ∞ F ( t ) = ( 1 − α ) ( I − α S ) − 1 Y S=-D^{-1/2}WD^{-1/2},其中D^{-1/2}=diag(\frac{1}{\sqrt{d_1}},\frac{1}{\sqrt{d_2}},...,\frac{1}{\sqrt{d_{l+u}}})\\迭代计算公式:F(t+1)=\alpha SF(t)+(1-\alpha)Y\\收敛后F^*=lim_{t\rightarrow \infty}F(t)=(1-\alpha)(I-\alpha S)^{-1}Y S=−D−1/2WD−1/2,其中D−1/2=diag(d11,d21,...,dl+u1)迭代计算公式:F(t+1)=αSF(t)+(1−α)Y收敛后F∗=limt→∞F(t)=(1−α)(I−αS)−1Y | 引入标注数据(全局)和图能量(局部)之间的平衡;允许Yl不同于Fl,但施加惩罚 |
1.假设
- 平滑假设:(生成式的)
- 半监督学习能有效,必须满足一些假设
- 半监督平滑假设:
- 如果高密度空间中两个点 𝑥(1), 𝑥(2) 距离较近, 那么对应的输出𝑦(1), 𝑦(2)也应该接近
- 监督学习的平滑假设 (用于对比):
- 如果空间中两个点𝑥(1), 𝑥(2)距离较近, 那么对用的输出𝑦(1), 𝑦(2)也应该接近
- 聚类假设( (S3VM)
- 如果点在同一个簇,那么它们很有可能属于同一个类
- 聚类假设的等价公式:
- 低密度分隔:决策边界应该在低密度区域.
- 聚类假设可以被看作半监督平滑假设的一种特殊情形
- 流形假设(基于图)
- 高维数据大致会分布在一个低维的流形上
- 邻近的样本拥有相似的输出
- 邻近的程度常用“相似”程度来刻画
- 主要的半监督模型
- 自我训练
- 多视角学习
- eg. 联合学习 [BM98]
- 生成模型
- 数据采样自相同的生成模型.
- eg. 混合高斯
- 低密度分割模型
- 例如. Transductive SVM [Joa99]
- 基于图的算法
- 数据被表示成图中的节点,边代表节点对的距离
- 这些方法基于流形假设.
- 例如. 标签传播
- 半监督聚类
- ◼ 通用想法: 从有标注和无标注数据学习
- ◼ 假设:
- ⚫ 平滑假设 (生成式)
- ⚫ 聚类假设 (S3VM)
- ⚫ 流形假设 (基于图)
- ⚫ 独立假设 (联合训练)
- ◼ 挑战:
- ⚫ 其他假设?
- ⚫ 效率
- 总结
- ◼ 使用无标注数据的两种方式:
- ⚫ 在损失函数中 (S3VM, 联合训练)
- 非凸 – 优化方法很重要!
- ⚫ 正则化 (图方法
- 凸问题, 但是图的构建很关键
- ⚫ 在损失函数中 (S3VM, 联合训练)
- ◼ 使用无标注数据的两种方式:
| 自学习算法 | 多视角学习-协同训练 | 多视角学习 | 生成模型GMM | 聚类标签法 | S3VMs(非凸) | 基于图的算法(凸) | 半监督聚类 | |
|---|---|---|---|---|---|---|---|---|
| 假设 | 输出的高度置信的预测是正确的 | 分裂出来的特征充分且条件独立 | 条件独立 | max 𝑃(𝑋, 𝑌|𝜃) 平滑假设 | 流形假设 | 聚类假设:来自不同类别的无标记数据之间会被较大的间隔隔开 | 流形假设 :假定在有标注和无标注数据上存在一个图. 被“紧密”连接的点趋向于有相同的标签 | - |
| 算法 | 从(𝑋𝑙, 𝑌𝑙)学习𝑓 ; 对𝑥𝜖𝑋𝑢预测结果;把(𝑥, 𝑓(𝑥)) 加入到标注数据;重复(置信度log P(y|x)) | f1和f2分别对x训练,每轮f1的结果给f2当做标注数据,f2的给f1 | m i n f Σ v = 1 M ( Σ i = 1 l c ( y i , f v ( x i ) ) + λ 1 ∥ f ∥ K 2 ) + λ 2 Σ u , v = 1 M Σ i = l + 1 n ( f u ( x i ) − f v ( x i ) ) 2 min_f\Sigma_{v=1}^M(\Sigma_{i=1}^lc(y_i,f_v(x_i))+\lambda_1\|f\|^2_K)+\lambda2\Sigma_{u,v=1}^M\Sigma_{i=l+1}^n(f_u(x_i)-f_v(x_i))^2 minfΣv=1M(Σi=1lc(yi,fv(xi))+λ1∥f∥K2)+λ2Σu,v=1MΣi=l+1n(fu(xi)−fv(xi))2鼓励多个学习器达成一致 | log 𝑝( 𝑋𝑙, 𝑌𝑙, 𝑋𝑢 |𝜃 ),EM解MLE | 使用任意聚类算法,通过计算簇内占多数的类别,将簇内所有的点标记为该类别 | m i n w 1 2 ∥ w ∥ 2 + C 1 Σ i = 1 l ( 1 − y i f ( x i ) ) + + C 2 Σ i = 1 + l n ( 1 − ∥ f ( x i ) ∥ ) + min_w \frac{1}{2}\|w\|^2+C_1\Sigma_{i=1}^l(1-y_if(x_i))_++C_2\Sigma_{i=1+l}^n(1-\|f(x_i)\|)_+ minw21∥w∥2+C1Σi=1l(1−yif(xi))++C2Σi=1+ln(1−∥f(xi)∥)+->svmlight/分支定界 | 局部和全局一致性方法;调和函数法;最小割 | 已知所属类别或约束,以此为基础聚类 |
| 优势 | 简单,wrapper;实用 | wrapper;对错误不那么敏感 | 弱学习器结合得到强学习器 | 清晰,基于良好理论基础的概率框架;如果模型接近真实的分布,将会非常有效 | 利用现有算法的一种简单方法 | 可以被用在任何SVMs 可以被应用的地方;清晰的数学框架 | 清晰的数学框架;当图恰好拟合该任务时,性能强大;能够被扩展到有向图 | - |
| 缺点 | 早期错误会累积,不保证收敛(特例EM)(部分存在封闭解 | 自然的特征分裂不一定存在;使用全部特征可能效果更好 | - | EM局部极小;验证模型正确性困难;模型可辨识问题;模型错误,无监督数据加重错误 | 很难去分析它的好坏. 如果簇假设不正确,结果会很差 | 优化困难;局部最优;,假设弱收益小 | 图质量差的时候性能差;对图的结构和权重敏感 | - |
| 思想 | 自己教自己 | 互相教对方 | 搜索最好的分类器 | - | - | 遍历所有 2𝑢 种可能的标注𝑋𝑢 ;为每一种标注构建一个标准的SVM (包含𝑋𝑙) ;选择间隔最大的SVM | 标签传播 | - |





2. 自学习算法
- 假设
- 输出的高度置信的预测是正确的
- 自学习算法
- 从(𝑋𝑙, 𝑌𝑙)学习𝑓
- 对𝑥𝜖𝑋𝑢预测结果
- 把(𝑥, 𝑓(𝑥)) 加入到标注数据
- 重复上述过程
- 变体
- 加入一些最置信的 (𝑥, 𝑓(𝑥))到标注数据集
- 提升慢
- 把所有 (𝑥, 𝑓(𝑥)) 加到标注数据
- 加的多,数据提升快,但是noise大
- 把所有(𝑥, 𝑓(𝑥)) 加到标注数据, 为每条数据按置信度赋予权重
- 加入一些最置信的 (𝑥, 𝑓(𝑥))到标注数据集
- 应用
- 图像分类:置信度log P(y|x)
- alphago zero
- 优势
- 最简单的半监督学习方法
- 这是一种wrapper方法,可以应用到已有的(复杂)分类器上
- 经常被用到实际任务中,例如自然语言处理任务中
- 缺点
- 早期错误会累积,
- 不保证收敛(
- 特例EM)(部分存在封闭解

- 特例EM)(部分存在封闭解
3.多视角学习
3.1 协同训练(co-training)
- 视角:一个对象的两个视角:图和html
- 视角的获取:特征分裂
- 分裂的要求:独立且充分
- ◼ 每个实例由两个特征集合𝑥 = [𝑥 1 ; 𝑥(2)]表示
- ⚫ 𝑥 1 = 图像特征
- ⚫ 𝑥 2 = web页面文本
- ⚫ 这是一个自然的特征分裂 (或者称为多视角)
- 视角的获取:特征分裂
- 协同训练的基本思想:
- 训练一个图像分类器和一个文本分类器
- 两个分类器互相教对方
- ◼ 假设
- ⚫ 特征集合可分裂𝑥 =[ 𝑥 1 ; 𝑥 2 ]
- ⚫ 𝑥 1 或 𝑥2单独对于训练一个好的分类器是充分的
- ⚫ 𝑥 1 和 𝑥2 在给定类别后是条件独立的
- 协同训练
- ⚫ 训练两个分类器: 从 𝑋𝑙 1 , 𝑌𝑙 学习𝑓(1) , 从(𝑋𝑙 2 , 𝑌𝑙)学习𝑓(2).
- ⚫用𝑓(1) and 𝑓(2)分别对𝑋𝑢分类.
- ⚫ 把𝑓(1) 的𝑘个最置信的预测结果 (𝑥, 𝑓 1 (𝑥)) 当做𝑓(2) 的标注数据
- ⚫ 把𝑓(2) 的𝑘个最置信的预测结果 (𝑥, 𝑓 2 (𝑥)) 当做 𝑓(1) 的标注数据
- ⚫ 重复上述过程
- ◼ 优点
- ⚫ 简单的wrapper方法. 可以被用到已有的各种分类器
- ⚫ 相比较于自我训练,对于错误不那么敏感
- ◼ 缺点
- ⚫ 自然的特征分裂可能不存在
⚫ 使用全部特征的模型可能效果更好(原来数据就少)
- ⚫ 自然的特征分裂可能不存在
- ◼ Co-EM: 不止是top 𝑘, 全部预测数据当做标注数据
- ⚫ 每个分类器有一个概率标签𝑋𝑢
- ⚫ 每个(𝑥, 𝑦) 加上权重𝑃( 𝑦| 𝑥)
- ◼ 假的特征集分裂
- ⚫ 构造随机的、人工的特征分裂 (没有天然的就自己构造)
- ⚫ 再应用协同训练

3.2 多视角学习
- 半监督学习中一类通用的算法
- ◼ 基于数据的多个视角(特征表示)
- • 协同训练是多视角学习中一个特例
- ◼ 通用的想法:
- • 训练多个分类器,每个分类器使用不同的视角
- • 多个分类器在无标签数据上应该达成一致
- 多视角学习(Multi-view Learning)
- 一个正则化风险最小化框架,鼓励多个学习器的一致性: m i n f Σ v = 1 M ( Σ i = 1 l c ( y i , f v ( x i ) ) + λ 1 ∥ f ∥ K 2 ) + λ 2 Σ u , v = 1 M Σ i = l + 1 n ( f u ( x i ) − f v ( x i ) ) 2 M 个 学 习 器 , C ( ) 是 原 来 的 l o s s ( 可 以 铰 链 损 失 / 平 方 损 失 ) min_f\Sigma_{v=1}^M(\Sigma_{i=1}^lc(y_i,f_v(x_i))+\lambda_1\|f\|^2_K)+\lambda2\Sigma_{u,v=1}^M\Sigma_{i=l+1}^n(f_u(x_i)-f_v(x_i))^2\\M个学习器,C()是原来的loss(可以铰链损失/平方损失) minfΣv=1M(Σi=1lc(yi,fv(xi))+λ1∥f∥K2)+λ2Σu,v=1MΣi=l+1n(fu(xi)−fv(xi))2M个学习器,C()是原来的loss(可以铰链损失/平方损失)
- ◼ 为什么多视角学习能学得更好?
- • 学习过程实质上搜索最好的分类器
- • 通过强迫多个分类器的预测一致性, 我们减少了搜索空间
- • 希望在较少的训练数据能够找到最好的分类器
- ◼ 对于测试数据,多个分类器被结合
- • 例如, 投票, 共识等.
- ◼ 得到了一些理论结果的支持
- ◼ 基于多视角的半监督学习是半监督学习和集成学习的自然过渡
- • 一些集成学习者观点:只要能够使用多个学习器,即可将弱学习器性能提升到极高 ,无需使用未标记样本
- • 一些半监督学习者观点:只要能使用未标记样本,即可将弱学习器性能提升到极高 ,无需使用多学习器
4. 生成模型
- ◼ 生成模型假设
- ⚫ 完全的生成模型(只考虑有标注数据) 𝑃(𝑋, 𝑌|𝜃)
- ◼ 半监督学习生成模型:
- ⚫ 所有数据(无论标注与否)都是由同一个潜在的模型“生成”的
- ⚫ 我们所感兴趣的量: 𝑝 (𝑋𝑙, 𝑌𝑙, 𝑋𝑢 |𝜃 )= ∑ Y u ∑_{Y_u } ∑Yu𝑝 (𝑋𝑙, 𝑌𝑙, 𝑋𝑢, 𝑌𝑢 |𝜃)
- ⚫ 寻找𝜃的极大似然估计,或者最大后验估计(贝叶斯估计)
- 在半监督学习中经常使用:
- ◼ 高斯混合模型 (GMM)
- ⚫图像分类
- ⚫ EM算法
- ◼ 混合多项式分布 (朴素贝叶斯)
- ⚫文本归类
- ⚫ EM算法
- ◼ 隐马尔科夫模型 (HMM)
- ⚫语音识别
- ⚫ Baum-Velch 算法
- ◼ 高斯混合模型 (GMM)
生成模型的例子


- 有无标注数据导致分界面不同,是因为优化目标不同导致的

4.2 GMM高斯混合模型
- 为简单起见, 考虑GMM用在二分类任务,利用MLE计算参数
- 只使用标注数据
- ⚫log 𝑝 (𝑋𝑙, 𝑌𝑙 |𝜃 )= Σ i = 1 l \Sigma_{i=1}^l Σi=1l log 𝑝( 𝑦𝑖 |𝜃) 𝑝(𝑥𝑖|𝑦𝑖, 𝜃)
- ⚫利用MLE 计算 𝜃 (频率, 采样均值, 采样协方差)
- ◼ 同时考虑有标注和无标注数据
log 𝑝( 𝑋𝑙, 𝑌𝑙, 𝑋𝑢 |𝜃 )= Σ i = 1 l \Sigma_{i=1}^l Σi=1l log 𝑝( 𝑦𝑖 |𝜃) 𝑝(𝑥𝑖|𝑦𝑖, 𝜃) + Σ i = l + 1 l + u l o g Σ y = 1 2 \Sigma_{i=l+1}^{l+u}log \Sigma_{y=1}^{2} Σi=l+1l+ulogΣy=12 𝑝( 𝑦𝑖 |𝜃) 𝑝(𝑥𝑖|𝑦, 𝜃)- ⚫MLE 计算困难(包含隐变量)
- ⚫EM算法是寻找局部最优解的一个方法
- ◼ 核心是最大化𝑝(𝑋𝑙, 𝑌𝑙, 𝑋𝑢|𝜃)
- ◼ EM 只是最大化该概率的一种方式
- ◼ 其他能计算出使其最大化参数的方法也是可行的,如,变分近似,或者直接优化
- 优点
- ◼ 清晰,基于良好理论基础的概率框架
- ◼ 如果模型接近真实的分布,将会非常有效
- 缺点
- ◼ 验证模型的正确性比较困难
- ◼ 模型可辨识问题(Model identifiability)
- ◼ EM局部最优
- ◼ 如果生成模型是错误,无监督数据会加重错误


4.2.1 EM算法用于GMM
- 在(𝑋𝑙, 𝑌𝑙)上用𝑀𝐿𝐸估计 𝜃 = {𝜔, 𝜇, ∑}1:2
- ⚫ 𝑤𝑐=类别 c的比例
- ⚫ 𝜇𝑐=类别c采样的均值
- ⚫ ∑𝑐=类别c采样的协方差
- 重复:
- E步:对所有𝑥𝜖𝑋𝑢,计算类别的期望 𝑝( 𝑦 x|𝜃 )
- ⚫ 将x以𝑝(𝑦 = 1|𝑥, 𝜃) 的比例标记为类别1
- ⚫ 将x以𝑝(𝑦 = 2|𝑥, 𝜃) 的比例标记为类别2
- M步: 用有标签数据𝑋𝑙和预测标签的数据𝑋𝑢 MLE估计𝜃
- E步:对所有𝑥𝜖𝑋𝑢,计算类别的期望 𝑝( 𝑦 x|𝜃 )
- 可以被看作自训练的一种特殊形式
- 初始化: 𝜃 = {𝜔, 𝜇, ∑}1:2
- E: γ j i = p ( y i k = 1 ∣ x i ) = p ( y ∣ θ ) p ( x i ∣ y , θ ) Σ y ′ p ( y ′ ∣ θ ) p ( x i ∣ y ′ , θ ) = ω i p ( x j ∣ μ k , Σ k ) Σ k = 1 K ω k p ( x j ∣ μ k , Σ k ) \gamma_{ji}\\=p(y_{ik=1}|x_i)\\=\frac{p(y|\theta)p(x_i|y,\theta)}{\Sigma_{y'}p(y'|\theta)p(x_i|y',\theta)}\\=\frac{\omega_ip(x_j|\mu_k,\Sigma_k)}{\Sigma_{k=1}^K\omega_kp(x_j|\mu_k,\Sigma_k)} γji=p(yik=1∣xi)=Σy′p(y′∣θ)p(xi∣y′,θ)p(y∣θ)p(xi∣y,θ)=Σk=1Kωkp(xj∣μk,Σk)ωip(xj∣μk,Σk)
- M: μ i = 1 Σ x j ∈ D u γ j i + l i ( Σ x j ∈ D u γ j i x j + Σ ( x j , y j ) ∈ D l a n d y j = i x j ) Σ i = 1 Σ x j ∈ D u γ j i + l i Σ x j ∈ D u γ j i ( x j − μ i ) ( x j − μ i ) T + 1 Σ x j ∈ D u γ j i + l i Σ ( x j , y j ) ∈ D l a n d y j = i ( x j − μ i ) ( x j − μ i ) T α i = Σ x j ∈ D u γ j i + l i m − − ω ? \mu_i=\frac{1}{\Sigma_{x_j\in D_u}\gamma_{ji}+l_i}(\Sigma_{x_j\in D_u}\gamma_{ji}x_j+\Sigma_{(x_j,y_j)\in D_l and y_j=i }x_j)\\ \Sigma_i=\frac{1}{\Sigma_{x_j\in D_u}\gamma_{ji}+l_i}\Sigma_{x_j\in D_u}\gamma_{ji}(x_j-\mu_i)(x_j-\mu_i)^T+\frac{1}{\Sigma_{x_j\in D_u}\gamma_{ji}+l_i}\Sigma_{(x_j,y_j)\in D_l and y_j=i }(x_j-\mu_i)(x_j-\mu_i)^T\\ \alpha_i=\frac{\Sigma_{x_j\in D_u}\gamma_{ji}+l_i}{m}--\omega? μi=Σxj∈Duγji+li1(Σxj∈Duγjixj+Σ(xj,yj)∈Dlandyj=ixj)Σi=Σxj∈Duγji+li1Σxj∈Duγji(xj−μi)(xj−μi)T+Σxj∈Duγji+li1Σ(xj,yj)∈Dlandyj=i(xj−μi)(xj−μi)Tαi=mΣxj∈Duγji+li−−ω?

4.2.2减小风险的启发式
- 模型错误–》务监督数据家中错误
- ◼ 需要我们更加仔细地构建生成模型,能正确建模目标任务
- 例如:每个类别用多个高斯分布,而不是单个高斯分布
- ◼ 降低无标注数据的权重
- log 𝑝( 𝑋𝑙, 𝑌𝑙, 𝑋𝑢 |𝜃 )= Σ i = 1 l \Sigma_{i=1}^l Σi=1l log 𝑝( 𝑦𝑖 |𝜃) 𝑝(𝑥𝑖|𝑦𝑖, 𝜃) + λ Σ i = l + 1 l + u l o g Σ y = 1 2 \lambda\Sigma_{i=l+1}^{l+u}log \Sigma_{y=1}^{2} λΣi=l+1l+ulogΣy=12 𝑝( 𝑦𝑖 |𝜃) 𝑝(𝑥𝑖|𝑦|𝜃)
4.3 聚类标签法(cluster-and-label)
- 除了使用概率生成模型,任何聚类算法都可以被用于半监督学习:
- ⚫ 在𝑋1 … 𝑋𝑢运行某种你挑选的聚类算法
- ⚫ 通过计算簇内占多数的类别,将簇内所有的点标记为该类别
- ⚫ 优点: 利用现有算法的一种简单方法
- ⚫ 缺点: 很难去分析它的好坏. 如果簇假设不正确,结果会很差

5. S3VMs=TSVM
-
◼ 半监督支持向量机(Semi-supervised SVMs, 简称S3VMs) = 直推
- SVM(Transductive SVMs,简称TSVMs)
-
◼ 最大化“所有数据的间隔(margin)”

-
标准SVM回忆
-
m
i
n
w
1
2
∣
∣
w
∣
∣
2
+
C
Σ
i
=
1
n
ξ
i
min_w \frac{1}{2}||w||^2+C\Sigma_{i=1}^n\xi_i
minw21∣∣w∣∣2+CΣi=1nξi
- 约束 y i ( w T x i ) > = 1 − ξ i , ξ i ≥ 0 , 对 任 意 i y^i(w^Tx^i)>=1-\xi_i,\xi_i \geq 0,对任意i yi(wTxi)>=1−ξi,ξi≥0,对任意i
- Hinge函数
- m i n ξ ξ s . t . ξ ≥ z ξ ≥ 0 i f z ≤ 0 , m i n ξ = 0 i f z > 0 , m i n ξ = z < = = > ( z ) + = m a x ( z , 0 ) min_\xi \xi\\s.t.\xi \geq z\\\xi\geq 0\\if z \leq 0 ,min \xi=0\\if z> 0 ,min \xi=z\\<==>\\(z)_+=max(z,0) minξξs.t.ξ≥zξ≥0ifz≤0,minξ=0ifz>0,minξ=z<==>(z)+=max(z,0)
- 使用Hinge函数的SVM
- m i n w 1 2 ∣ ∣ w ∣ ∣ 2 + C Σ i = 1 n ( 1 − y i f ( x i ) ) + min_w \frac{1}{2}||w||^2+C\Sigma_{i=1}^n(1-y_if(x_i))_+ minw21∣∣w∣∣2+CΣi=1n(1−yif(xi))+
- 倾向于让有标注的点在正确的一方

-
m
i
n
w
1
2
∣
∣
w
∣
∣
2
+
C
Σ
i
=
1
n
ξ
i
min_w \frac{1}{2}||w||^2+C\Sigma_{i=1}^n\xi_i
minw21∣∣w∣∣2+CΣi=1nξi
-
◼ 基本假设
- ⚫ 来自不同类别的无标记数据之间会被较大的间隔隔开
-
◼ S3VMs 基本思想:
- ⚫ 遍历所有 2𝑢 种可能的标注𝑋𝑢
- ⚫ 为每一种标注构建一个标准的SVM (包含𝑋𝑙)
- ⚫ 选择间隔最大的SVM
-
◼优点:
- • 可以被用在任何SVMs 可以被应用的地方
- • 清晰的数学框架
-
◼缺点:
- • 优化困难
- • 可能陷入局部最优
- • 相比于生成模型和基于图的方法使用更弱的假设, 收益可能较小
-
◼ 如何利用没有标注的点?
- ⚫ 分配标签sign(𝑓 𝑥 )给 𝑥 ∈ 𝑋𝑢
- ⚫ sign(𝑓(𝑥)) 𝑓(𝑥)=|𝑓(𝑥)|
- ⚫ 无标注上的hinge损失为
- (1 − 𝑦𝑖𝑓(𝑥𝑖))+= (1 − |𝑓(𝑥𝑖)|)+
-
◼ S3VM 目标函数:
m i n w 1 2 ∣ ∣ w ∣ ∣ 2 + C 1 Σ i = 1 l ( 1 − y i f ( x i ) ) + + C 2 Σ i = 1 + l n ( 1 − ∣ f ( x i ) ∣ ) + min_w \frac{1}{2}||w||^2+C_1\Sigma_{i=1}^l(1-y_if(x_i))_++C_2\Sigma_{i=1+l}^n(1-|f(x_i)|)_+ minw21∣∣w∣∣2+C1Σi=1l(1−yif(xi))++C2Σi=1+ln(1−∣f(xi)∣)+- 第三项:无标注数据的损失,倾向于f(x)>=1or f(x)<=1让无标注数据远离决策边界f(x)=0
- 等价地,要选择远离标注数据的f=0
- 类别平衡限制
- 直接优化S3VM目标函数常常会产生一些不均衡的分类—大多数点落在一个累内
- 启发式的类别平衡方法: 1 n − 1 Σ i = l + 1 n y i = 1 l Σ i = 1 l y i \frac{1}{n-1}\Sigma_{i=l+1}^ny_i=\frac{1}{l}\Sigma_{i=1}^ly_i n−11Σi=l+1nyi=l1Σi=1lyi
- 放松的类别均衡限制
1
n
−
1
Σ
i
=
l
+
1
n
f
(
x
i
)
=
1
l
Σ
i
=
1
l
y
i
\frac{1}{n-1}\Sigma_{i=l+1}^nf(x_i)=\frac{1}{l}\Sigma_{i=1}^ly_i
n−11Σi=l+1nf(xi)=l1Σi=1lyi
m i n w 1 2 ∣ ∣ w ∣ ∣ 2 + C 1 Σ i = 1 l ( 1 − y i f ( x i ) ) + + C 2 Σ i = 1 + l n ( 1 − ∣ f ( x i ) ∣ ) + s . t . 1 n − 1 Σ i = l + 1 n f ( x i ) = 1 l Σ i = 1 l y i min_w \frac{1}{2}||w||^2+C_1\Sigma_{i=1}^l(1-y_if(x_i))_++C_2\Sigma_{i=1+l}^n(1-|f(x_i)|)_+\\ s.t. \frac{1}{n-1}\Sigma_{i=l+1}^nf(x_i)=\frac{1}{l}\Sigma_{i=1}^ly_i minw21∣∣w∣∣2+C1Σi=1l(1−yif(xi))++C2Σi=1+ln(1−∣f(xi)∣)+s.t.n−11Σi=l+1nf(xi)=l1Σi=1lyi


- 分类sgn(f(x))
- 挑战:目标函数非凸,求解困难
- 学习方法
- ◼ 精确方法:
- • 混合整数规划(Mixed Integer Programming )[Bennett, Demiriz; NIPS 1998]
- • 分支定界(Branch & Bound) [Chapelle, Sindhwani, Keerthi; NIPS 2006]
- ◼ 近似方法:
- • 自标注启发式S3VMlight (self-labeling heuristic S3VMlight )[T. Joachims; ICML 1999]
- • 梯度下降(gradient descent )[Chapelle, Zien; AISTATS 2005]
- • CCCP-S3VM [R. Collobert et al.; ICML 2006]
- • contS3VM [Chapelle et al.; ICML 2006]
- ◼ 精确方法:
5.2 学习算法 S V M l i g h t SVM^{light} SVMlight
-
思想
- ◼ 局部组合搜索策略(Local combinatorial search)
- ◼ 分配一个“硬”标签到无标注数据
- ◼ 外层循环: 𝐶2从0开始向上“退火”
- ◼ 内层循环: 成对标签切换
-
算法
- ◼ 用(𝑋𝑙, 𝑌𝑙)训练一个SVM.
- ◼ 根据𝑓(𝑋𝑢)排序𝑋𝑢 . 以合适的比例标注𝑦 = 1, −1
- ◼ FOR 𝐶2 ← 10−5𝐶2⋯𝐶2
- ⚫ REPEAT:
m i n w 1 2 ∣ ∣ w ∣ ∣ 2 + C 1 Σ i = 1 l ( 1 − y i f ( x i ) ) + + C 2 Σ i = 1 + l n ( 1 − ∣ f ( x i ) ∣ ) + min_w \frac{1}{2}||w||^2+C_1\Sigma_{i=1}^l(1-y_if(x_i))_++C_2\Sigma_{i=1+l}^n(1-|f(x_i)|)_+ minw21∣∣w∣∣2+C1Σi=1l(1−yif(xi))++C2Σi=1+ln(1−∣f(xi)∣)+ - ⚫ IF ∃ 𝑖,𝑗 可交换 THEN 交换 𝑦𝑖, 𝑦𝑗
- ⚫ UNTIL 没有标签可交换
- ⚫ REPEAT:
-
ij可交换<===>
-
l
o
s
s
(
y
i
=
1
,
f
(
x
i
)
)
+
l
o
s
s
(
y
j
=
−
1
,
f
(
x
j
)
)
>
l
o
s
s
(
y
i
=
−
1
,
f
(
x
i
)
)
+
l
o
s
s
(
y
j
=
1
,
f
(
x
j
)
)
h
i
n
g
e
损
失
l
o
s
s
=
(
1
−
y
f
)
+
loss(y_i=1,f(x_i))+loss(y_j=-1,f(x_j))>loss(y_i=-1,f(x_i))+loss(y_j=1,f(x_j))\\hinge 损失loss=(1-yf)_+
loss(yi=1,f(xi))+loss(yj=−1,f(xj))>loss(yi=−1,f(xi))+loss(yj=1,f(xj))hinge损失loss=(1−yf)+

-
l
o
s
s
(
y
i
=
1
,
f
(
x
i
)
)
+
l
o
s
s
(
y
j
=
−
1
,
f
(
x
j
)
)
>
l
o
s
s
(
y
i
=
−
1
,
f
(
x
i
)
)
+
l
o
s
s
(
y
j
=
1
,
f
(
x
j
)
)
h
i
n
g
e
损
失
l
o
s
s
=
(
1
−
y
f
)
+
loss(y_i=1,f(x_i))+loss(y_j=-1,f(x_j))>loss(y_i=-1,f(x_i))+loss(y_j=1,f(x_j))\\hinge 损失loss=(1-yf)_+
loss(yi=1,f(xi))+loss(yj=−1,f(xj))>loss(yi=−1,f(xi))+loss(yj=1,f(xj))hinge损失loss=(1−yf)+
5.3 分支定界
- ◼ 组合优化问题.
- ◼ 在𝑋𝑢上构建一棵部分标注的树.
- ⚫ 根节点: 𝑋𝑢 没有标注
- ⚫ 子节点: 比父节点多一个数据𝑥 ∈ 𝑋𝑢被标注
- ⚫ 叶子节点: 所有𝑥 ∈ 𝑋𝑢 被标注
- ◼ 部分标注有一个非减(non-decreasing)的S3VM目标函数
m i n w 1 2 ∣ ∣ w ∣ ∣ 2 + C 1 Σ i = 1 l ( 1 − y i f ( x i ) ) + + C 2 Σ i ∈ l a b e l e d s o f a r ( 1 − ∣ f ( x i ) ∣ ) + min_w \frac{1}{2}||w||^2+C_1\Sigma_{i=1}^l(1-y_if(x_i))_++C_2\Sigma_{i\in labeled so far}(1-|f(x_i)|)_+ minw21∣∣w∣∣2+C1Σi=1l(1−yif(xi))++C2Σi∈labeledsofar(1−∣f(xi)∣)+
- ◼ 在𝑋𝑢上构建一棵部分标注的树.
- 算法
- ◼ 在树上进行深度优先搜索
- ◼ 记录一个到当前为止的完整目标函数值
- ◼ 如果它比最好的目标函数差,就进行剪枝(包括它的子树)

6. 基于图的算法
- 文本分类
- 相似性是通过文档中词的重叠度度量的
- 标签以相似的无标注文章传播





- 图的算法
- ◼ 假设
- ⚫ 假定在有标注和无标注数据上存在一个图. 被“紧密”连接的点趋向于有相同的标签.
- ◼ 标签传播:在图上标签的变化应该是平滑的
- ⚫ 临近节点应该有相似的标签
- 图
- ◼ 节点: 𝑋𝑙 ∪ 𝑋𝑢
- ◼ 边:权重是基于特征来计算相邻节点之间的相似度, 例如,
- ⚫ 𝑘最近邻图, 无权重(0, 1 权重)
- ⚫ 全连接图, 权重随距离衰减𝑤 = e x p ( − ∣ ∣ x i − x j ∣ ∣ 2 / σ 2 ) exp(-||x_i-x_j||^2/\sigma^2) exp(−∣∣xi−xj∣∣2/σ2)
- ⚫ 𝜀−半径(𝜀-radius) 图
- ◼ 想要的结果: 通过所有的路径来推导相似度
- 一些图的算法
- ◼ 最小割(Mincut)
- ◼ 调和函数法(Harmonic)
- ◼ 局部和全局一致性法(Local and global consistency)
- ◼ 流形正则化方法(Manifold regularization)
- ◼ 优点:
- • 清晰的数学框架
- • 当图恰好拟合该任务时,性能强大
- • 能够被扩展到有向图
- ◼ 缺点:
- • 图质量差的时候性能差
- • 对图的结构和权重敏感
| 目标函数 | 备注 | |
|---|---|---|
| 最小割 | m i n f ∞ Σ i = 1 l ( y i − Y l i ) 2 + Σ i j w i j ( y i − y j ) 2 min_f\infty\Sigma_{i=1}^l(y_i-Y_{li})^2+\Sigma_{ij}w_{ij}(y_i-y_j)^2 minf∞Σi=1l(yi−Yli)2+Σijwij(yi−yj)2 | — |
| 调和函数之自我训练 | E ( f ) = Σ i − j w i j ( y i − y j ) 2 f ( x i ) = Σ j − i w i j f ( x j ) Σ j − i w i j , 任 意 x i ∈ X u E(f)=\Sigma_{i-j}w_{ij}(y_i-y_j)^2\\f(x_i)=\frac{\Sigma_{j-i}w_{ij}f(x_j)}{\Sigma_{j-i}w_{ij}},任意x_i\in X_u E(f)=Σi−jwij(yi−yj)2f(xi)=Σj−iwijΣj−iwijf(xj),任意xi∈Xu,迭代至收敛 | 固定已有标注,如果标注存在错误怎么办?想要更灵活,希望偶尔不服从给定的标注 |
| 调和函数之拉普拉斯 | m i n f ∞ Σ i = 1 l ( y i − f ( x i ) ) 2 + f T L f min_f\infty\Sigma_{i=1}^l(y_i-f(x_i))^2+f^TLf minf∞Σi=1l(yi−f(xi))2+fTLf,迭代至收敛 | 他不能够处理新的测试数据,仅在Xu上,来新的了要重新算 |
| 局部和全局一致性的方法 | S = − D − 1 / 2 W D − 1 / 2 , 其 中 D − 1 / 2 = d i a g ( 1 d 1 , 1 d 2 , . . . , 1 d l + u ) 迭 代 计 算 公 式 : F ( t + 1 ) = α S F ( t ) + ( 1 − α ) Y 收 敛 后 F ∗ = l i m t → ∞ F ( t ) = ( 1 − α ) ( I − α S ) − 1 Y S=-D^{-1/2}WD^{-1/2},其中D^{-1/2}=diag(\frac{1}{\sqrt{d_1}},\frac{1}{\sqrt{d_2}},...,\frac{1}{\sqrt{d_{l+u}}})\\迭代计算公式:F(t+1)=\alpha SF(t)+(1-\alpha)Y\\收敛后F^*=lim_{t\rightarrow \infty}F(t)=(1-\alpha)(I-\alpha S)^{-1}Y S=−D−1/2WD−1/2,其中D−1/2=diag(d11,d21,...,dl+u1)迭代计算公式:F(t+1)=αSF(t)+(1−α)Y收敛后F∗=limt→∞F(t)=(1−α)(I−αS)−1Y | 引入标注数据(全局)和图能量(局部)之间的平衡;允许Yl不同于Fl,但施加惩罚 |
6.1 最小割mincut

- 固定Yl,去最小化
Σ
i
j
w
i
j
∣
(
y
i
−
y
j
)
∣
,
以
寻
找
Y
u
∈
{
0
,
1
}
\Sigma_{ij}w_{ij}|(y_i-y_j)|,以寻找Y_u\in\{0,1\}
Σijwij∣(yi−yj)∣,以寻找Yu∈{0,1}
- <==>
m
i
n
f
∞
Σ
i
=
1
l
(
y
i
−
Y
l
i
)
2
+
Σ
i
j
w
i
j
(
y
i
−
y
j
)
2
min_f\infty\Sigma_{i=1}^l(y_i-Y_{li})^2+\Sigma_{ij}w_{ij}(y_i-y_j)^2
minf∞Σi=1l(yi−Yli)2+Σijwij(yi−yj)2
- 组合问题,但是又多项式时间的解
- 最小化两方的权值差
- <==>
m
i
n
f
∞
Σ
i
=
1
l
(
y
i
−
Y
l
i
)
2
+
Σ
i
j
w
i
j
(
y
i
−
y
j
)
2
min_f\infty\Sigma_{i=1}^l(y_i-Y_{li})^2+\Sigma_{ij}w_{ij}(y_i-y_j)^2
minf∞Σi=1l(yi−Yli)2+Σijwij(yi−yj)2
- 最小割计算了玻尔兹曼机的modes(峰值)
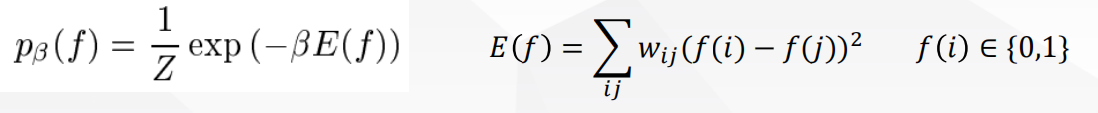
- ◼ 可能存在多种模式
- ◼ 一个方法是随机打乱权重,平均结果

Karger‘s algorithm(随机算法)
While there are more than 2 vertices:
• Pick a remaining edge (𝑢, 𝑣) uniformly at random
• Merge (or “contract”) 𝑢 and 𝑣 into a single vertex
• Remove self-loops
Return cut represented by final 2 vertices
Stoer–Wagner algorithm(确定性算法)
function: MinCutPhase(Graph G, Weights W, Vertex a):
A <- {a}
while A != V:
add tightly connected vertex to A
store cut_of_the_phase and shrink G by merging the two vertices added last
minimum = INF
function: MinCut(Graph G, Weights W, Vertex a):
while |V| > 1:
MinCutPhase(G,W,a)
if cut_of_the_phase < minimum:
minimum = cut_of_the_phase
return minimum
随机最小割
- ◼ 构建一个图G
- ◼ 随机给边加上一些噪声,然后求解最小割
- ◼ 移除那些极度不平衡的解(小于5%的解在一边的)
- ◼ 用多数投票获得最后的分割
6.2 调和函数法(迭代、拉普拉斯方法)
-
放松离散的标签值到连续值
- f(xi)=yi连续
- 最小化能量 E ( f ) = Σ i − j w i j ( y i − y j ) 2 E(f)=\Sigma_{i-j}w_{ij}(y_i-y_j)^2 E(f)=Σi−jwij(yi−yj)2
- 高斯随机场的均值
- 邻居的均值 f ( x i ) = Σ j − i w i j f ( x j ) Σ j − i w i j , 任 意 x i ∈ X u f(x_i)=\frac{\Sigma_{j-i}w_{ij}f(x_j)}{\Sigma_{j-i}w_{ij}},任意x_i\in X_u f(xi)=Σj−iwijΣj−iwijf(xj),任意xi∈Xu
-
计算调和函数的方法
- 自我训练
- ◼ 计算调和函数的一种方式是:
- ⚫ 初始, 设置 𝑓( 𝑥𝑖) = 𝑦𝑖 对于 𝑖 = 1 ⋯ 𝑙, 对于𝑥𝑗 ∈ 𝑋𝑢 ,𝑓(𝑥𝑗) 设为任意值 (例如, 0)
- ⚫ 重复这个步骤直到收敛: Set f ( x i ) = Σ j − i w i j f ( x j ) Σ j − i w i j , 任 意 x i ∈ X u f(x_i)=\frac{\Sigma_{j-i}w_{ij}f(x_j)}{\Sigma_{j-i}w_{ij}},任意x_i\in X_u f(xi)=Σj−iwijΣj−iwijf(xj),任意xi∈Xu, 即邻接点的加权平均值. 注意 𝑓(𝑋𝑙) 是固定的
- ◼ 这也可以看成是自我训练的一种特殊形式
- 图拉普拉斯的方法
- 权重矩阵W
- D i i = Σ j = 1 n W i j D_{ii}=\Sigma_{j=1}^nW_{ij} Dii=Σj=1nWij
- 拉普拉斯:L=D-W
- 能量函数: E ( f ) = 1 2 Σ i − j w i j ( y i − y j ) 2 = f T L f E(f)=\frac{1}{2}\Sigma_{i-j}w_{ij}(y_i-y_j)^2=f^TLf E(f)=21Σi−jwij(yi−yj)2=fTLf
- 所以调和函数给定标注下的能量: m i n f ∞ Σ i = 1 l ( y i − f ( x i ) ) 2 + f T L f min_f\infty\Sigma_{i=1}^l(y_i-f(x_i))^2+f^TLf minf∞Σi=1l(yi−f(xi))2+fTLf
- L = [ L l l L l u L u l L u u ] 调 和 解 L f = 0 f u = ( D u u − W u u ) − 1 W u l Y l = ( I − P u u ) − 1 P u l Y l , 其 中 P = D − 1 W 归 一 化 L ′ = D − 1 / 2 L D − 1 / 2 = I − D − 1 / 2 W D − 1 / 2 L=\left[\begin{matrix} L_{ll} &L_{lu}\\L_{ul}&L_{uu}\end{matrix}\right]\\调和解Lf=0\\f_u=(D_{uu}-W_{uu})^{-1}W_{ul}Y_l=(I-P_{uu})^{-1}P_{ul}Y_l,其中P=D^{-1}W\\归一化L'=D^{-1/2}LD^{-1/2}=I-D^{-1/2}WD^{-1/2} L=[LllLulLluLuu]调和解Lf=0fu=(Duu−Wuu)−1WulYl=(I−Puu)−1PulYl,其中P=D−1W归一化L′=D−1/2LD−1/2=I−D−1/2WD−1/2
- 自我训练
-
电子网络的解释
-

-
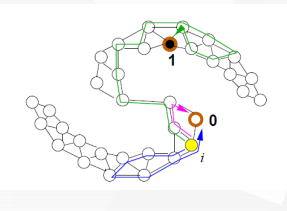
随机游走的解释
-
从节点i,以概率 w i j Σ k w i k \frac{w_{ij}}{\Sigma_kw_{ik}} Σkwikwij随即游走到j
-
如果遇到有标注的节点就停止
-
调和函数是f=P(遇到标签1|从i出发)
-
标签传播

6.3局部和全局一致性的方法
- (1) 邻近的点有可能有相同的标签;
- (2) 在相同结构(簇或者流形)上的点可能有相同的标签;
- 算法
- 将标签拓展到多分类任务,假定 𝑦𝑖∈ 𝒴,定义非负的(𝑙 + 𝑢) × 𝒴 的标记矩阵𝐹 = (𝐹1𝑇, 𝐹2𝑇, … , 𝐹𝑙+𝑢 𝑇 )𝑇,其中第𝑖行的元素𝐹𝑖 = ( 𝐹 𝑖1, 𝐹 𝑖2, … , (𝐹)𝑖 |𝒴| )为示例𝑥𝑖的标记向量,相应的分类规则为
y i = a r g m a x 1 ≤ j ≤ ∣ y ∣ ( F ) i j y_i=argmax_{1\leq j\leq |y|}(F)_{ij} yi=argmax1≤j≤∣y∣(F)ij - 标记矩阵初始化为 F ( 0 ) = ( Y ) i j = { 1 i f ( 1 ≤ i ≤ l ) a n d ( y i = j ) 0 o t h e r w i s e F(0)=(Y)_{ij}=\begin{cases}1& if(1\leq i\leq l)and(y_i=j)\\ 0&otherwise\end{cases} F(0)=(Y)ij={10if(1≤i≤l)and(yi=j)otherwise
- 构造一个基于W的标记传播矩阵 S = − D − 1 / 2 W D − 1 / 2 , 其 中 D − 1 / 2 = d i a g ( 1 d 1 , 1 d 2 , . . . , 1 d l + u ) 迭 代 计 算 公 式 : F ( t + 1 ) = α S F ( t ) + ( 1 − α ) Y 收 敛 后 F ∗ = l i m t → ∞ F ( t ) = ( 1 − α ) ( I − α S ) − 1 Y S=-D^{-1/2}WD^{-1/2},其中D^{-1/2}=diag(\frac{1}{\sqrt{d_1}},\frac{1}{\sqrt{d_2}},...,\frac{1}{\sqrt{d_{l+u}}})\\迭代计算公式:F(t+1)=\alpha SF(t)+(1-\alpha)Y\\收敛后F^*=lim_{t\rightarrow \infty}F(t)=(1-\alpha)(I-\alpha S)^{-1}Y S=−D−1/2WD−1/2,其中D−1/2=diag(d11,d21,...,dl+u1)迭代计算公式:F(t+1)=αSF(t)+(1−α)Y收敛后F∗=limt→∞F(t)=(1−α)(I−αS)−1Y
- 将标签拓展到多分类任务,假定 𝑦𝑖∈ 𝒴,定义非负的(𝑙 + 𝑢) × 𝒴 的标记矩阵𝐹 = (𝐹1𝑇, 𝐹2𝑇, … , 𝐹𝑙+𝑢 𝑇 )𝑇,其中第𝑖行的元素𝐹𝑖 = ( 𝐹 𝑖1, 𝐹 𝑖2, … , (𝐹)𝑖 |𝒴| )为示例𝑥𝑖的标记向量,相应的分类规则为
- 该算法对应于正则化框架
- m i n F 1 2 ( Σ i , j = 1 ( W ) i j ∣ ∣ F i d i − F j d j ∣ ∣ 2 ) + μ Σ i = 1 l ∣ ∣ F i − Y i ∣ ∣ 2 min_F\frac{1}{2}(\Sigma_{i,j=1}(W)_{ij}||\frac{F_i}{\sqrt{d_i}}-\frac{F_j}{\sqrt{d_j}}||^2)+\mu\Sigma_{i=1}^l||F_i-Y_i||^2 minF21(Σi,j=1(W)ij∣∣diFi−djFj∣∣2)+μΣi=1l∣∣Fi−Yi∣∣2
- ◼ 允许𝑓(𝑋𝑙) 不同于𝑌𝑙, 但是加以惩罚(第二项)
- ◼ 引入标注数据(全局)和图能量(局部)之间的平衡



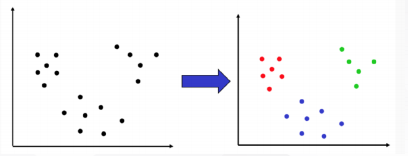
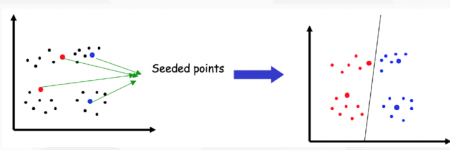
7. 半监督聚类
-
聚类是无监督学习的一种算法
-
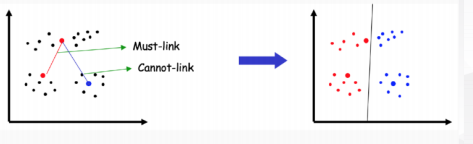
半监督聚类: 聚类并加入一系列领知识
- ◼ 根据给定的不同的领域知识:
- 用户预先提供一些种子文档的类别标签
- 用户知道其中一些文档是相关 (must-link)的还是不相关(cannot-link)
- ◼ 根据给定的不同的领域知识:
-
用户预先提供一些种子文档的类别标签

-
用户知道其中一些文档是相关 (must-link)的还是不相关(cannot-link)

8. 前沿
8.1深度学习中的半监督学习


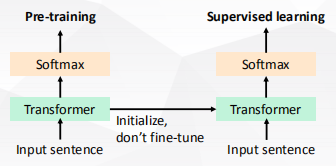
- ◼ 自然语言处理中的预训练(右)
- ◼ 在无标注数据上训练模型
- ◼ 学习到的权重放到监督任务的模型中
- ◼ Word2vec(左)
- ◼ 共享词向量部分
- ◼ 无监督学习: skip-gram/cbow/glove
- ◼ 有监督学习:一些NLP任务


- ◼ ELMo(中)
- ◼ 在双向语言模型任务上预训练模型
- ◼ 共享词向量和上下文编码部分(LSTM)
- ◼ BERT(右)(transformer)
- ◼ 共享全部的编码部分
- ◼ 预训练的任务是屏蔽(mask)语言模型和上下句关系预测
- ◼ 随机屏蔽一些词,无监督模型根据上下文预测该词
- ◼ 判断两句话是不是连续的两句话,例如,随机将部分下一句换成其他句子
- ◼ 监督模型只保留最后的任务特定的输出层不预训练,例如,分类任务非预训练参数仅一层softmax
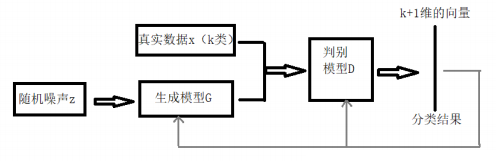
- 半监督GAN
- ◼ 将GAN用在半监督学习领域的时候需要做一些改变
- ◼ 生成器不做改变,仍然负责从输入噪声数据中生成图像
- ◼ 判别器D不再是一个简单的真假分类(二分类)器,假设输入数据有K类,D就是K+1的分类器,多出的那一类是判别输入是否是生成器G生成的图像
















 1451
1451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









