










文章目录
概率图模型
code
4.HMM–>CRF
4.1 HMM–是个序列

- x-观测到的
- 条件独立
- 给定yt
- y t − 1 和 y t + 1 ( 所 有 的 过 去 和 未 来 也 都 独 立 ) y_{t-1}和y_{t+1}(所有的过去和未来也都独立) yt−1和yt+1(所有的过去和未来也都独立)独立
- x u 和 x s x_{u}和x_{s} xu和xs独立
- 给定yt
- 表示
- 状态分布: π i = p ( y 1 i = 1 ) \pi_i=p(y_1^i=1) πi=p(y1i=1)
- 状态转移矩阵A,aij为转移概率
- P ( y t + 1 j ∣ y t i = 1 ) P(y_{t+1}^j|y_t^i=1) P(yt+1j∣yti=1)
- 发射概率 P ( x ∣ y ) P(x|y) P(x∣y)
- 则联合概率
P
(
x
,
y
)
=
p
(
y
1
)
Π
t
=
1
T
−
1
P
(
y
t
+
1
j
∣
y
t
i
)
Π
t
=
1
T
P
(
x
t
∣
y
t
)
P(x,y)=p(y_1)\Pi_{t=1}^{T-1}P(y_{t+1}^j|y_t^i)\Pi_{t=1}^{T}P(x_t|y_t)
P(x,y)=p(y1)Πt=1T−1P(yt+1j∣yti)Πt=1TP(xt∣yt)
- 参数化 P ( x , y ) = π y 1 Π t = 1 T − 1 a y t + 1 , y t Π t = 1 T P ( x t ∣ y t ) P(x,y)=\pi_{y_1}\Pi_{t=1}^{T-1}a_{y_{t+1},y_t}\Pi_{t=1}^{T}P(x_t|y_t) P(x,y)=πy1Πt=1T−1ayt+1,ytΠt=1TP(xt∣yt)
- 三个基础问题
- 状态序列解码(推断)问题:
- 给定 x , θ − − > y : p ( y ∣ x , θ ) x,\theta-->y:p(y|x,\theta) x,θ−−>y:p(y∣x,θ)
- 似然评估问题evaluate
- 给定 x , θ − − > 似 然 函 数 P ( x ∣ θ ) x,\theta --> 似然函数P(x|\theta) x,θ−−>似然函数P(x∣θ)
- 参数估计问题(学习
- 给定 x − − > θ = a r g m a x P ( x ∣ θ ) x --> \theta=argmax P(x|\theta) x−−>θ=argmaxP(x∣θ)
- 状态序列解码(推断)问题:
4.1.1 推断问题(evaluate)


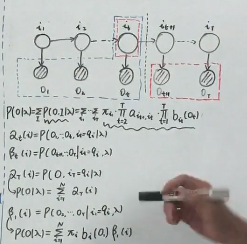
-
P
(
x
)
=
Σ
y
1
,
y
2
,
.
.
.
,
y
T
P
(
x
,
y
)
=
Σ
y
1
,
y
2
,
.
.
.
,
y
T
π
y
1
Π
t
=
1
T
−
1
a
y
t
+
1
,
y
t
Π
t
=
1
T
P
(
x
t
∣
y
t
)
=
Σ
y
P
(
x
∣
y
)
p
(
y
)
=
Σ
y
1
Σ
y
2
.
.
.
Σ
y
T
π
y
1
Π
t
=
1
T
−
1
a
y
t
+
1
,
y
t
Π
t
=
1
T
P
(
x
t
∣
y
t
)
P(x)=\Sigma_{y_1,y_2,...,y_T} P(x,y)=\Sigma_{y_1,y_2,...,y_T}\pi_{y_1}\Pi_{t=1}^{T-1}a_{y_{t+1},y_t}\Pi_{t=1}^{T}P(x_t|y_t)\\=\Sigma_y P(x|y)p(y)\\=\Sigma_{y_1}\Sigma_{y_2}...\Sigma_{y_T}\pi_{y_1}\Pi_{t=1}^{T-1}a_{y_{t+1},y_t}\Pi_{t=1}^{T}P(x_t|y_t)
P(x)=Σy1,y2,...,yTP(x,y)=Σy1,y2,...,yTπy1Πt=1T−1ayt+1,ytΠt=1TP(xt∣yt)=ΣyP(x∣y)p(y)=Σy1Σy2...ΣyTπy1Πt=1T−1ayt+1,ytΠt=1TP(xt∣yt)
- y i = { q 1 , q 2 , . . . , q N } − − − O ( N T ) 太 y_i=\{q_1,q_2,...,q_N\}---O(N^T)太 yi={q1,q2,...,qN}−−−O(NT)太
- 很多连乘,但是并不是跟所有的都有关,就可以往后推求和
-
P
(
y
t
∣
x
)
=
P
(
x
∣
y
t
)
P
(
y
t
)
P
(
x
)
=
P
(
x
1
,
.
.
.
,
x
t
∣
y
t
)
P
(
x
t
+
1
,
.
.
.
,
x
n
∣
y
t
)
P
(
y
t
)
P
(
x
)
P(y_t|x)=\frac{P(x|y_t)P(y_t)}{P(x)}=\frac{P(x1,...,x_t|y_t)P(x_{t+1},...,x_n|y_t)P(y_t)}{P(x)}
P(yt∣x)=P(x)P(x∣yt)P(yt)=P(x)P(x1,...,xt∣yt)P(xt+1,...,xn∣yt)P(yt)
-
P
(
y
t
∣
x
)
=
γ
(
y
t
)
=
P
(
x
1
,
.
.
.
,
x
t
,
y
t
)
P
(
x
t
+
1
,
.
.
.
,
x
n
∣
y
t
)
P
(
x
)
=
α
(
y
t
)
β
(
y
t
)
P
(
x
)
P(y_t|x)=\gamma(y_t)=\frac{P(x1,...,x_t,y_t)P(x_{t+1},...,x_n|y_t)}{P(x)}=\frac{\alpha(y_t)\beta(y_t)}{P(x)}
P(yt∣x)=γ(yt)=P(x)P(x1,...,xt,yt)P(xt+1,...,xn∣yt)=P(x)α(yt)β(yt)
- p ( x ) = Σ y t α ( y t ) β ( y t ) p(x)=\Sigma_{y_t}\alpha(y_t)\beta(y_t) p(x)=Σytα(yt)β(yt)
- 其中𝛼(𝑦𝑡)是产生部分输出序列 𝑥1, ⋯ , 𝑥𝑡并结束于𝑦𝑡的概率
- 其中β(𝑦𝑡)是从𝑦𝑡状态开始产生输出序列𝑥𝑡+1, ⋯ , 𝑥𝑇的概率
-
P
(
y
t
∣
x
)
=
γ
(
y
t
)
=
P
(
x
1
,
.
.
.
,
x
t
,
y
t
)
P
(
x
t
+
1
,
.
.
.
,
x
n
∣
y
t
)
P
(
x
)
=
α
(
y
t
)
β
(
y
t
)
P
(
x
)
P(y_t|x)=\gamma(y_t)=\frac{P(x1,...,x_t,y_t)P(x_{t+1},...,x_n|y_t)}{P(x)}=\frac{\alpha(y_t)\beta(y_t)}{P(x)}
P(yt∣x)=γ(yt)=P(x)P(x1,...,xt,yt)P(xt+1,...,xn∣yt)=P(x)α(yt)β(yt)
- 递归的计算
-
α
(
y
t
+
1
)
=
Σ
y
t
α
(
y
t
)
a
y
t
+
1
,
y
t
P
(
x
t
+
1
∣
y
t
+
1
)
\alpha(y_{t+1})=\Sigma_{y_t}\alpha(y_t)a_{y_{t+1},y_t}P(x_{t+1}|y_{t+1})
α(yt+1)=Σytα(yt)ayt+1,ytP(xt+1∣yt+1)
- 初始化 α ( y 0 ) = P ( x 0 , y 0 ) = p ( x 0 ∣ y 0 ) P ( y 0 ) = P ( x 0 ∣ y 0 ) π y 0 \alpha(y_0)=P(x_0,y_0)=p(x_0|y_0)P(y_0)=P(x_0|y_0)\pi_{y_0} α(y0)=P(x0,y0)=p(x0∣y0)P(y0)=P(x0∣y0)πy0
-
β
(
y
t
)
=
Σ
y
t
+
1
β
(
y
t
+
1
)
a
y
t
+
1
,
y
t
P
(
x
t
+
1
∣
y
t
+
1
)
\beta(y_{t})=\Sigma_{y_{t+1}}\beta(y_{t+1})a_{y_{t+1},y_t}P(x_{t+1}|y_{t+1})
β(yt)=Σyt+1β(yt+1)ayt+1,ytP(xt+1∣yt+1)
- 初始化
β
(
y
T
)
=
1
就
行
了
\beta(y_T)=1就行了
β(yT)=1就行了
-
假
定
β
(
y
T
)
为
单
位
向
量
,
我
们
可
以
准
确
计
算
出
β
y
T
−
1
假定\beta(y_T)为单位向量,我们可以准确计算出\beta_{y_{T-1}}
假定β(yT)为单位向量,我们可以准确计算出βyT−1
- P ( x ) = Σ i α ( y T i ) β ( y T i ) = Σ i α ( y T i ) = P ( x ) P(x)=\Sigma_i\alpha(y_T^i)\beta(y_T^i)=\Sigma_i \alpha(y_T^i)=P(x) P(x)=Σiα(yTi)β(yTi)=Σiα(yTi)=P(x)
-
假
定
β
(
y
T
)
为
单
位
向
量
,
我
们
可
以
准
确
计
算
出
β
y
T
−
1
假定\beta(y_T)为单位向量,我们可以准确计算出\beta_{y_{T-1}}
假定β(yT)为单位向量,我们可以准确计算出βyT−1
- 初始化
β
(
y
T
)
=
1
就
行
了
\beta(y_T)=1就行了
β(yT)=1就行了
- 为了计算所有的yt的后验概率,需要为每一步计算alpha/beta—一次前向一次后向
- ξ ( y t , y t + 1 ) = P ( y t , y t + 1 ∣ x ) = P ( x ∣ y t , y t + 1 ) P ( y t + 1 ∣ y t ) P ( y t ) p ( x ) = P ( x 1 , . . . x t ∣ y t ) P ( x t + 1 ∣ y t + 1 ) P ( x t + 2 , . . . x n ∣ y t + 1 ) P ( y t + 1 ∣ y t ) P ( y t ) p ( x ) = α ( y t ) P ( x t + 1 ∣ y t + 1 ) β ( y t + 1 ) a y t + 1 , y t p ( x ) \xi(y_t,y_{t+1})=P(y_t,y_{t+1}|x)\\=\frac{P(x|y_t,y_{t+1})P(y_{t+1}|y_t)P(y_t)}{p(x)}\\=\frac{P(x1,...x_t|y_t)P(x_{t+1}|y_{t+1})P(x_{t+2},...x_n|y_{t+1})P(y_{t+1}|y_t)P(y_t)}{p(x)}\\=\frac{\alpha(y_t)P(x_{t+1}|y_{t+1})\beta(y_{t+1})a_{y_{t+1},y_t}}{p(x)} ξ(yt,yt+1)=P(yt,yt+1∣x)=p(x)P(x∣yt,yt+1)P(yt+1∣yt)P(yt)=p(x)P(x1,...xt∣yt)P(xt+1∣yt+1)P(xt+2,...xn∣yt+1)P(yt+1∣yt)P(yt)=p(x)α(yt)P(xt+1∣yt+1)β(yt+1)ayt+1,yt
- 似然函数–简单求和最终步的 α \alpha α可得到
- 状态的后验概率– 再 使 用 β 递 归 再使用\beta递归 再使用β递归
- –> P ( y t k = 1 ∣ x ) = α ( y t ) β ( y t ) P ( x ) P(y_t^k=1|x)=\frac{\alpha(y_t)\beta(y_t)}{P(x)} P(ytk=1∣x)=P(x)α(yt)β(yt)
- –>如何得到整个序列的最大后验证概率
-
α
(
y
t
+
1
)
=
Σ
y
t
α
(
y
t
)
a
y
t
+
1
,
y
t
P
(
x
t
+
1
∣
y
t
+
1
)
\alpha(y_{t+1})=\Sigma_{y_t}\alpha(y_t)a_{y_{t+1},y_t}P(x_{t+1}|y_{t+1})
α(yt+1)=Σytα(yt)ayt+1,ytP(xt+1∣yt+1)
4.1.2 viterbi decoding解码
- y ∗ = a r g m a x y P ( y ∣ x ) = a r g m a x y P ( x , y ) y*=argmax_y P(y|x)=argmax_y P(x,y) y∗=argmaxyP(y∣x)=argmaxyP(x,y)
-
V
t
k
=
m
a
x
y
1
,
.
.
.
,
y
t
−
1
P
(
x
1
,
.
.
.
,
x
t
−
1
,
y
1
,
.
.
.
,
y
t
−
1
,
x
t
,
y
t
k
=
1
)
V_t^k=max_{y_1,...,y_{t-1}} P(x_1,...,x_{t-1},y_1,...,y_{t-1},x_t,y_t^k=1)
Vtk=maxy1,...,yt−1P(x1,...,xt−1,y1,...,yt−1,xt,ytk=1)
- 结尾为 y t = k y_t=k yt=k时,最可能状态序列的概率
- 递归形式 V t k = p ( x t ∣ y t k = 1 ) m a x i V t − 1 i a i , k a i , k = p ( y i k ∣ y i ) : i − > k V_t^k=p(x_t|y_t^k=1)max_i V_{t-1}^ia_{i,k}\\a_{i,k}=p(y_ik|y_i):i->k Vtk=p(xt∣ytk=1)maxiVt−1iai,kai,k=p(yik∣yi):i−>k
- 动态规划(路径规划)问题:距离=1/p,使得cost最小
-
V
t
k
:
t
时
刻
,
y
t
=
k
−
−
到
达
q
k
状
态
m
a
x
y
1
,
.
.
.
,
y
t
−
1
终
点
已
经
确
定
,
路
径
没
有
确
定
,
找
概
率
最
大
的
路
径
V_t^k:t时刻,y_t=k--到达q_k状态\\max_{y_1,...,y_{t-1}} 终点已经确定,路径没有确定,找概率最大的路径
Vtk:t时刻,yt=k−−到达qk状态maxy1,...,yt−1终点已经确定,路径没有确定,找概率最大的路径
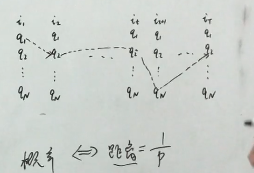
4.1.3 学习,参数估计
-
极大似然估计:EM算法
- 最大化 P ( x ∣ θ ) P(x|\theta) P(x∣θ)
- 参数 A 、 π , 输 出 分 布 的 参 数 A、\pi,输出分布的参数 A、π,输出分布的参数
-
P ( x ∣ θ ) = Σ y 1 , y 2 , . . . , y T P ( x , y ) = Σ y 1 , y 2 , . . . , y T π y 1 Π t = 1 T − 1 a y t + 1 , y t Π t = 1 T P ( x t ∣ y t , η ) P(x|\theta)=\Sigma_{y_1,y_2,...,y_T} P(x,y)=\Sigma_{y_1,y_2,...,y_T}\pi_{y_1}\Pi_{t=1}^{T-1}a_{y_{t+1},y_t}\Pi_{t=1}^{T}P(x_t|y_t,\eta) P(x∣θ)=Σy1,y2,...,yTP(x,y)=Σy1,y2,...,yTπy1Πt=1T−1ayt+1,ytΠt=1TP(xt∣yt,η)
-
假 设 P ( x t ∣ y t , η ) = Π i = 1 M Π j = 1 L [ η i j ] y t i x t j 假设P(x_t|y_t,\eta)=\Pi_{i=1}^M \Pi_{j=1}^L[\eta_{ij}]^{y_t^ix_t^j} 假设P(xt∣yt,η)=Πi=1MΠj=1L[ηij]ytixtj
-
M

-
α ^ i j = m i j Σ k = 1 N m i k η ^ i j = n i j Σ k = 1 N n i k π ^ i = y 1 i \hat{\alpha}_{ij}=\frac{m_{ij}}{\Sigma_{k=1}^N m_{ik}}\\ \hat{\eta}_{ij}=\frac{n_{ij}}{\Sigma_{k=1}^N n_{ik}}\\ \hat{\pi}_i=y_1^i α^ij=Σk=1Nmikmijη^ij=Σk=1Nniknijπ^i=y1i
-
E步



-
缺点
- 仅捕捉了状态之间和状态及其对应输出之间的关系(上下文)
- 学习目标和预测目标不匹配
- 我们只要p(y|x),但只知道p(x,y)—产生式模型
4.1.4计算实例
 * A:aij:i->j
* A:aij:i->j
- 前向计算
- 时间1:
- α ( y 1 = 1 ) = P ( x 1 ∣ y 1 = 1 ) π y 1 = 1 = 0.5 ∗ 0.2 = 0.1 ( x 1 = 红 ) α ( y 1 = 2 ) = P ( x 1 ∣ y 1 = 2 ) π y 1 = 2 = 0.4 ∗ 0.4 = 0.16 α ( y 1 = 3 ) = P ( x 1 ∣ y 1 = 3 ) π y 1 = 3 = 0.7 ∗ 0.4 = 0.28 \alpha(y_1=1)=P(x_1|y_1=1)\pi_{y_1=1}=0.5*0.2=0.1\\(x1=红) \alpha(y_1=2)=P(x_1|y_1=2)\pi_{y_1=2}=0.4*0.4=0.16 \alpha(y_1=3)=P(x_1|y_1=3)\pi_{y_1=3}=0.7*0.4=0.28 α(y1=1)=P(x1∣y1=1)πy1=1=0.5∗0.2=0.1(x1=红)α(y1=2)=P(x1∣y1=2)πy1=2=0.4∗0.4=0.16α(y1=3)=P(x1∣y1=3)πy1=3=0.7∗0.4=0.28
- 时间2:x2=白
- α ( y 2 = 1 ) = ( Σ y 1 α ( y 1 ) P ( y 2 = 1 ∣ y 1 ) ) P ( x 2 ∣ y 2 ) = ( 0.1 ∗ 0.5 + 0.16 ∗ 0.3 + 0.28 ∗ 0.2 ) ∗ 0.5 = 0.077 α ( y 2 = 2 ) = ( α ( y 1 = 1 ) P ( y 2 = 2 ∣ y 1 = 1 ) + α ( y 1 = 2 ) P ( y 2 = 2 ∣ y 1 = 2 ) + α ( y 1 = 3 ) P ( y 2 = 2 ∣ y 1 = 3 ) ) ∗ P ( x 2 ∣ y 2 = 2 ) = ( 0.1 ∗ 0.2 + 0.16 ∗ 0.5 + 0.28 ∗ 0.3 ) ∗ 0.6 = 0.1104 α ( y 2 = 3 ) = ( 0.1 ∗ 0.3 + 0.16 ∗ 0.2 + 0.28 ∗ 0.5 ) ∗ 0.3 = 0.0606 \alpha(y_2=1)=(\Sigma_{y_1}\alpha(y_1)P(y_2=1|y_1))P(x_2|y_2)=(0.1*0.5+0.16*0.3+0.28*0.2)*0.5=0.077\\ \alpha(y_2=2)=(\alpha(y_1=1)P(y_2=2|y_1=1)+\alpha(y_1=2)P(y_2=2|y_1=2)+\alpha(y_1=3)P(y_2=2|y_1=3))*P(x_2|y_2=2)=(0.1*0.2+0.16*0.5+0.28*0.3)*0.6=0.1104\\ \alpha(y_2=3)=(0.1*0.3+0.16*0.2+0.28*0.5)*0.3=0.0606 α(y2=1)=(Σy1α(y1)P(y2=1∣y1))P(x2∣y2)=(0.1∗0.5+0.16∗0.3+0.28∗0.2)∗0.5=0.077α(y2=2)=(α(y1=1)P(y2=2∣y1=1)+α(y1=2)P(y2=2∣y1=2)+α(y1=3)P(y2=2∣y1=3))∗P(x2∣y2=2)=(0.1∗0.2+0.16∗0.5+0.28∗0.3)∗0.6=0.1104α(y2=3)=(0.1∗0.3+0.16∗0.2+0.28∗0.5)∗0.3=0.0606
- 时间3:x3=红
- α ( y 3 = 1 ) = ( 0.077 ∗ 0.5 + 0.1104 ∗ 0.3 + 0.0606 ∗ 0.2 ) ∗ 0.5 = 0.4187 α ( y 3 = 2 ) = ( 0.077 ∗ 0.2 + 0.1104 ∗ 0.5 + 0.0606 ∗ 0.3 ) ∗ 0.4 = 0.03551 α ( y 3 = 3 ) = ( 0.077 ∗ 0.3 + 0.1104 ∗ 0.2 + 0.0606 ∗ 0.5 ) ∗ 0.7 = 0.05284 p ( x ) = Σ i α ( y T i ) = α ( y 3 = 1 ) + α ( y 3 = 2 ) + α ( y 3 = 3 ) = 0.13022 \alpha(y_3=1)=(0.077*0.5+0.1104*0.3+0.0606*0.2)*0.5=0.4187\\ \alpha(y_3=2)=(0.077*0.2+0.1104*0.5+0.0606*0.3)*0.4=0.03551\\ \alpha(y_3=3)=(0.077*0.3+0.1104*0.2+0.0606*0.5)*0.7=0.05284\\ p(x)=\Sigma_i \alpha(y_T^i)=\alpha(y_3=1)+\alpha(y_3=2)+\alpha(y_3=3)=0.13022 α(y3=1)=(0.077∗0.5+0.1104∗0.3+0.0606∗0.2)∗0.5=0.4187α(y3=2)=(0.077∗0.2+0.1104∗0.5+0.0606∗0.3)∗0.4=0.03551α(y3=3)=(0.077∗0.3+0.1104∗0.2+0.0606∗0.5)∗0.7=0.05284p(x)=Σiα(yTi)=α(y3=1)+α(y3=2)+α(y3=3)=0.13022
- 时间1:
- 后向计算:
- β ( y 3 = 1 ) = 1 , β ( y 3 = 2 ) = 1 , β ( y 3 = 3 ) = 1 \beta(y_3=1)=1,\beta(y_3=2)=1,\beta(y_3=3)=1 β(y3=1)=1,β(y3=2)=1,β(y3=3)=1
- 时间2
- β ( y 2 ) = Σ y 3 β ( y 3 ) a y 3 , y 2 P ( x 3 ∣ y 3 ) = β ( y 3 = 1 ) a y 3 = 1 , y 2 P ( x 3 ∣ y 3 = 1 ) + β ( y 3 = 2 ) a y 3 = 2 , y 2 P ( x 3 ∣ y 3 = 2 ) + β ( y 3 = 3 ) a y 3 , y 2 P ( x 3 ∣ y 3 = 3 ) \beta(y_2)=\Sigma_{y_3}\beta(y_3)a_{y_3,y_2}P(x_3|y_3)\\ =\beta(y_3=1)a_{y_3=1,y_2}P(x_3|y_3=1)+\beta(y_3=2)a_{y_3=2,y_2}P(x_3|y_3=2)+\beta(y_3=3)a_{y_3,y_2}P(x_3|y_3=3) β(y2)=Σy3β(y3)ay3,y2P(x3∣y3)=β(y3=1)ay3=1,y2P(x3∣y3=1)+β(y3=2)ay3=2,y2P(x3∣y3=2)+β(y3=3)ay3,y2P(x3∣y3=3)
- β ( y 2 = 1 ) = 1 ∗ 0.5 ∗ 0.5 + 1 ∗ 0.2 ∗ 0.4 + 1 ∗ 0.2 ∗ 0.7 = 0.47 \beta(y_2=1)=1*0.5*0.5+1*0.2*0.4+1*0.2*0.7=0.47 β(y2=1)=1∗0.5∗0.5+1∗0.2∗0.4+1∗0.2∗0.7=0.47
- β ( y 2 = 2 ) = 1 ∗ 0.3 ∗ 0.5 + 1 ∗ 0.5 ∗ 0.4 + 1 ∗ 0.2 ∗ 0.7 = 0.49 \beta(y_2=2)=1*0.3*0.5+1*0.5*0.4+1*0.2*0.7=0.49 β(y2=2)=1∗0.3∗0.5+1∗0.5∗0.4+1∗0.2∗0.7=0.49
- β ( y 2 = 3 ) = 1 ∗ 0.2 ∗ 0.5 + 1 ∗ 0.3 ∗ 0.4 + 1 ∗ 0.5 ∗ 0.7 = 0.57 \beta(y_2=3)=1*0.2*0.5+1*0.3*0.4+1*0.5*0.7=0.57 β(y2=3)=1∗0.2∗0.5+1∗0.3∗0.4+1∗0.5∗0.7=0.57
- 时间1
- β ( y 2 = 1 ) = 0.47 ∗ 0.5 ∗ 0.5 + 0.49 ∗ 0.2 ∗ 0.6 + 0.57 ∗ 0.2 ∗ 0.3 = 0.2105 \beta(y_2=1)=0.47*0.5*0.5+0.49*0.2*0.6+0.57*0.2*0.3=0.2105 β(y2=1)=0.47∗0.5∗0.5+0.49∗0.2∗0.6+0.57∗0.2∗0.3=0.2105
- β ( y 2 = 2 ) = 0.47 ∗ 0.3 ∗ 0.5 + 0.49 ∗ 0.5 ∗ 0.6 + 0.57 ∗ 0.2 ∗ 0.3 = 0.2517 \beta(y_2=2)=0.47*0.3*0.5+0.49*0.5*0.6+0.57*0.2*0.3=0.2517 β(y2=2)=0.47∗0.3∗0.5+0.49∗0.5∗0.6+0.57∗0.2∗0.3=0.2517
- β ( y 2 = 3 ) = 0.47 ∗ 0.2 ∗ 0.5 + 0.49 ∗ 0.3 ∗ 0.6 + 0.57 ∗ 0.5 ∗ 0.3 = 0.2207 \beta(y_2=3)=0.47*0.2*0.5+0.49*0.3*0.6+0.57*0.5*0.3=0.2207 β(y2=3)=0.47∗0.2∗0.5+0.49∗0.3∗0.6+0.57∗0.5∗0.3=0.2207
import torch
import torch.nn as nn
import torch.optim as optim
y_size=3;
x_size=2;
transition=torch.tensor([[0.5,0.2,0.3],[0.3,0.5,0.2],[0.2,0.3,0.5]])
b=torch.tensor([[0.5,0.5],[0.4,0.6],[0.7,0.3]])
pi=torch.tensor([[0.2],[0.4],[0.4]])
x=[0,1,0]
def alpha(x):#前向算法p(x1,x2,x3,...,xt,yt)
alpha=(b[:,x[0]]*pi[:].reshape(y_size)).reshape(1,y_size)
# print(alpha)
for i in range(1,len(x)):
alpha=torch.cat((alpha,(torch.matmul(alpha[i-1],transition)*b[:,x[i]]).reshape(1,y_size)),0)
return alpha
alpha=alpha(x)
print(alpha)
"""
tensor([[0.1000, 0.1600, 0.2800],
[0.0770, 0.1104, 0.0606],
[0.0419, 0.0355, 0.0528]])
"""
def p(x,alpha):#p(x)
# alpha=alpha(x);
return torch.sum(alpha[len(x)-1])
p(x,alpha)
#tensor(0.1302)
def beta(x):
beta=torch.ones(1,y_size)
for i in range(len(x)-2,-1,-1):
beta=torch.cat((torch.sum(beta[0]*transition*b[:,x[i+1]],axis=1).reshape(1,y_size),beta))
return beta
beta=beta(x)
tensor([[0.2451, 0.2622, 0.2277],
[0.5400, 0.4900, 0.5700],
[1.0000, 1.0000, 1.0000]])
def gamma(alpha,beta,p_x):
return alpha*beta/p_x
def xi(x,alpha,beta,p_x):
# print(alpha_yt,b[y_t1,x_t1],beta_yt1,transition[y_t,y_t1])
# return alpha_yt*b[y_t1,x_t1]*beta_yt1*transition[y_t,y_t1]/p_x
xi=[]
for t in range(0,len(x)-1):
xi.append((alpha[t].reshape(y_size,1)*transition*b[:,x[t+1]]*beta[t+1]))
# print(xi[t])
return torch.cat(xi).reshape(len(xi),y_size,y_size)


- 求最优路径(维特比,贪心)
- δ ( y 1 ) = α ( y 1 ) = P ( x 1 ∣ y 1 ) π y 1 \delta(y_1)=\alpha(y_1)=P(x_1|y_1)\pi_{y_1} δ(y1)=α(y1)=P(x1∣y1)πy1
- δ ( y t + 1 ) = m a x y 1 δ ( y 1 ) P ( y 2 = 1 ∣ y 1 ) ) P ( x 2 ∣ y 2 ) = m a x ( δ ( y 1 = 1 ) P ( y 2 = 2 ∣ y 1 = 1 ) , δ ( y 1 = 2 ) P ( y 2 = 2 ∣ y 1 = 2 ) , δ ( y 1 = 3 ) P ( y 2 = 2 ∣ y 1 = 3 ) ) ∗ P ( x 2 ∣ y 2 = 1 ) \delta(y_{t+1})=max_{y_1}\delta(y_1)P(y_2=1|y_1))P(x_2|y_2)=max(\delta(y_1=1)P(y_2=2|y_1=1),\delta(y_1=2)P(y_2=2|y_1=2),\delta(y_1=3)P(y_2=2|y_1=3))*P(x_2|y_2=1) δ(yt+1)=maxy1δ(y1)P(y2=1∣y1))P(x2∣y2)=max(δ(y1=1)P(y2=2∣y1=1),δ(y1=2)P(y2=2∣y1=2),δ(y1=3)P(y2=2∣y1=3))∗P(x2∣y2=1)
- HMM(x–O)
- 则联合概率
P
(
x
,
y
)
=
p
(
y
1
)
Π
t
=
1
T
−
1
P
(
y
t
+
1
j
∣
y
t
i
)
Π
t
=
1
T
P
(
x
t
∣
y
t
)
P(x,y)=p(y_1)\Pi_{t=1}^{T-1}P(y_{t+1}^j|y_t^i)\Pi_{t=1}^{T}P(x_t|y_t)
P(x,y)=p(y1)Πt=1T−1P(yt+1j∣yti)Πt=1TP(xt∣yt)
- 参数化 P ( x , y ) = π y 1 Π t = 1 T − 1 a y t + 1 , y t Π t = 1 T P ( x t ∣ y t ) P(x,y)=\pi_{y_1}\Pi_{t=1}^{T-1}a_{y_{t+1},y_t}\Pi_{t=1}^{T}P(x_t|y_t) P(x,y)=πy1Πt=1T−1ayt+1,ytΠt=1TP(xt∣yt)
- P ( x ) = Σ y 1 , y 2 , . . . , y T P ( x , y ) = Σ y 1 , y 2 , . . . , y T π y 1 Π t = 1 T − 1 a y t + 1 , y t Π t = 1 T P ( x t ∣ y t ) = Σ y P ( x ∣ y ) p ( y ) = Σ y 1 Σ y 2 . . . Σ y T π y 1 Π t = 1 T − 1 a y t + 1 , y t Π t = 1 T P ( x t ∣ y t ) P(x)=\Sigma_{y_1,y_2,...,y_T} P(x,y)=\Sigma_{y_1,y_2,...,y_T}\pi_{y_1}\Pi_{t=1}^{T-1}a_{y_{t+1},y_t}\Pi_{t=1}^{T}P(x_t|y_t)\\=\Sigma_y P(x|y)p(y)\\=\Sigma_{y_1}\Sigma_{y_2}...\Sigma_{y_T}\pi_{y_1}\Pi_{t=1}^{T-1}a_{y_{t+1},y_t}\Pi_{t=1}^{T}P(x_t|y_t) P(x)=Σy1,y2,...,yTP(x,y)=Σy1,y2,...,yTπy1Πt=1T−1ayt+1,ytΠt=1TP(xt∣yt)=ΣyP(x∣y)p(y)=Σy1Σy2...ΣyTπy1Πt=1T−1ayt+1,ytΠt=1TP(xt∣yt)
- P ( y t ∣ x ) = γ ( y t ) = P ( x 1 , . . . , x t , y t ) P ( x t + 1 , . . . , x n ∣ y t ) P ( x ) = α ( y t ) β ( y t ) P ( x ) P(y_t|x)=\gamma(y_t)=\frac{P(x1,...,x_t,y_t)P(x_{t+1},...,x_n|y_t)}{P(x)}=\frac{\alpha(y_t)\beta(y_t)}{P(x)} P(yt∣x)=γ(yt)=P(x)P(x1,...,xt,yt)P(xt+1,...,xn∣yt)=P(x)α(yt)β(yt)
- 递归的计算
-
α
(
y
t
+
1
)
=
Σ
y
t
α
(
y
t
)
a
y
t
+
1
,
y
t
P
(
x
t
+
1
∣
y
t
+
1
)
\alpha(y_{t+1})=\Sigma_{y_t}\alpha(y_t)a_{y_{t+1},y_t}P(x_{t+1}|y_{t+1})
α(yt+1)=Σytα(yt)ayt+1,ytP(xt+1∣yt+1)
- 初始化 α ( y 0 ) = P ( x 0 , y 0 ) = p ( x 0 ∣ y 0 ) P ( y 0 ) = P ( x 0 ∣ y 0 ) π y 0 \alpha(y_0)=P(x_0,y_0)=p(x_0|y_0)P(y_0)=P(x_0|y_0)\pi_{y_0} α(y0)=P(x0,y0)=p(x0∣y0)P(y0)=P(x0∣y0)πy0
-
β
(
y
t
)
=
Σ
y
t
+
1
β
(
y
t
+
1
)
a
y
t
+
1
,
y
t
P
(
x
t
+
1
∣
y
t
+
1
)
\beta(y_{t})=\Sigma_{y_{t+1}}\beta(y_{t+1})a_{y_{t+1},y_t}P(x_{t+1}|y_{t+1})
β(yt)=Σyt+1β(yt+1)ayt+1,ytP(xt+1∣yt+1)
- 初始化
β
(
y
T
)
=
1
就
行
了
\beta(y_T)=1就行了
β(yT)=1就行了
-
假
定
β
(
y
T
)
为
单
位
向
量
,
我
们
可
以
准
确
计
算
出
β
y
T
−
1
假定\beta(y_T)为单位向量,我们可以准确计算出\beta_{y_{T-1}}
假定β(yT)为单位向量,我们可以准确计算出βyT−1
- P ( x ) = Σ i α ( y T i ) β ( y T i ) = Σ i α ( y T i ) = P ( x ) P(x)=\Sigma_i\alpha(y_T^i)\beta(y_T^i)=\Sigma_i \alpha(y_T^i)=P(x) P(x)=Σiα(yTi)β(yTi)=Σiα(yTi)=P(x)
-
假
定
β
(
y
T
)
为
单
位
向
量
,
我
们
可
以
准
确
计
算
出
β
y
T
−
1
假定\beta(y_T)为单位向量,我们可以准确计算出\beta_{y_{T-1}}
假定β(yT)为单位向量,我们可以准确计算出βyT−1
- 初始化
β
(
y
T
)
=
1
就
行
了
\beta(y_T)=1就行了
β(yT)=1就行了
-
α
(
y
t
+
1
)
=
Σ
y
t
α
(
y
t
)
a
y
t
+
1
,
y
t
P
(
x
t
+
1
∣
y
t
+
1
)
\alpha(y_{t+1})=\Sigma_{y_t}\alpha(y_t)a_{y_{t+1},y_t}P(x_{t+1}|y_{t+1})
α(yt+1)=Σytα(yt)ayt+1,ytP(xt+1∣yt+1)
- 则联合概率
P
(
x
,
y
)
=
p
(
y
1
)
Π
t
=
1
T
−
1
P
(
y
t
+
1
j
∣
y
t
i
)
Π
t
=
1
T
P
(
x
t
∣
y
t
)
P(x,y)=p(y_1)\Pi_{t=1}^{T-1}P(y_{t+1}^j|y_t^i)\Pi_{t=1}^{T}P(x_t|y_t)
P(x,y)=p(y1)Πt=1T−1P(yt+1j∣yti)Πt=1TP(xt∣yt)
def Viterbi(x):#贪婪
V=b[:,x[0]]*pi[:].reshape(y_size);
list=[]
print("V0:",V)
# 前向计算各部分概率
for t in range(1,len(x)):
# max,indices=torch.max(V[t - 1].reshape(y_size, 1) * transition, axis=0)
# list.append(indices)
# V=torch.cat((V,(b[:,x[t]]*max).reshape(1,y_size)),axis=0)
max, indices = torch.max(V.reshape(y_size,1) * transition, axis=0)
list.append(indices)
V=b[:,x[t]]*max
print("V",t,V)
#后向寻找路径
print("max-pathchoice",list)
max,indices=torch.max(V,axis=0)
path=indices.reshape(1)
print(indices)
for i in range(len(list)-1,-1,-1):
path=torch.cat((list[0][path[0]].reshape(1),path))
return path;#y1=path0,y2=path1
print("path",Viterbi(x))
V0: tensor([0.1000, 0.1600, 0.2800])
V 1 tensor([0.0280, 0.0504, 0.0420])
V 2 tensor([0.0076, 0.0101, 0.0147])
max-pathchoice [tensor([2, 2, 2]), tensor([1, 1, 2])]
tensor(2)
path tensor([2, 2, 2])
4.1.5 EM(baum-welch算法)的上溢出和下溢出
通过放缩
α
,
β
\alpha,\beta
α,β解决
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









