







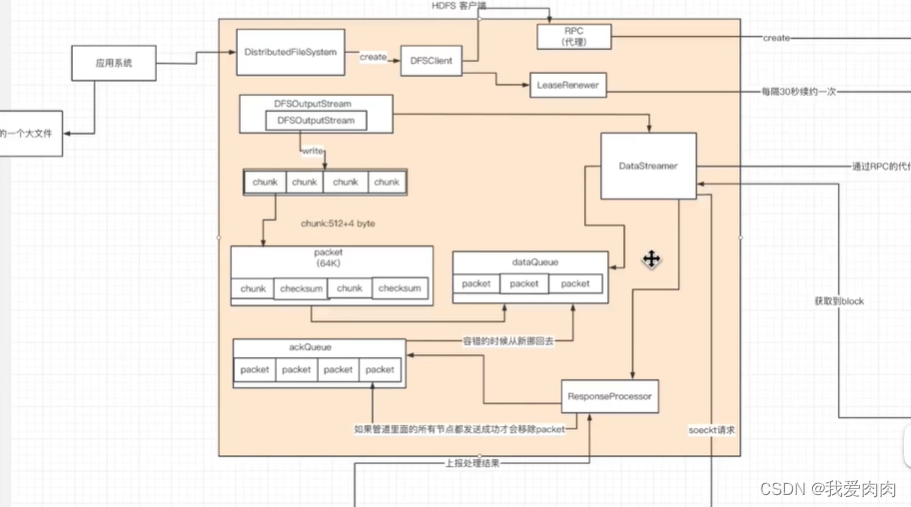
整体流程图
左 HDFS客户端
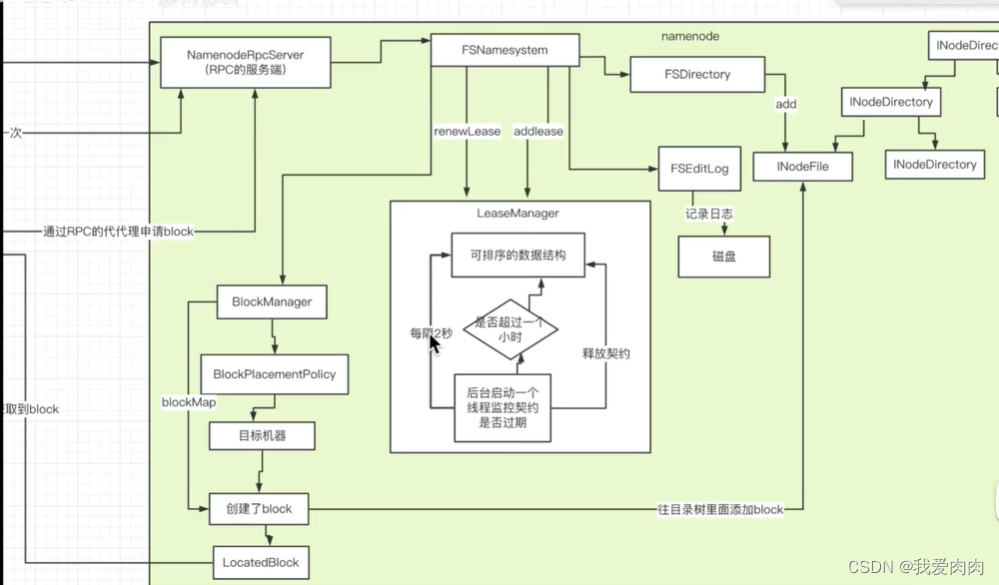
右 NameNode
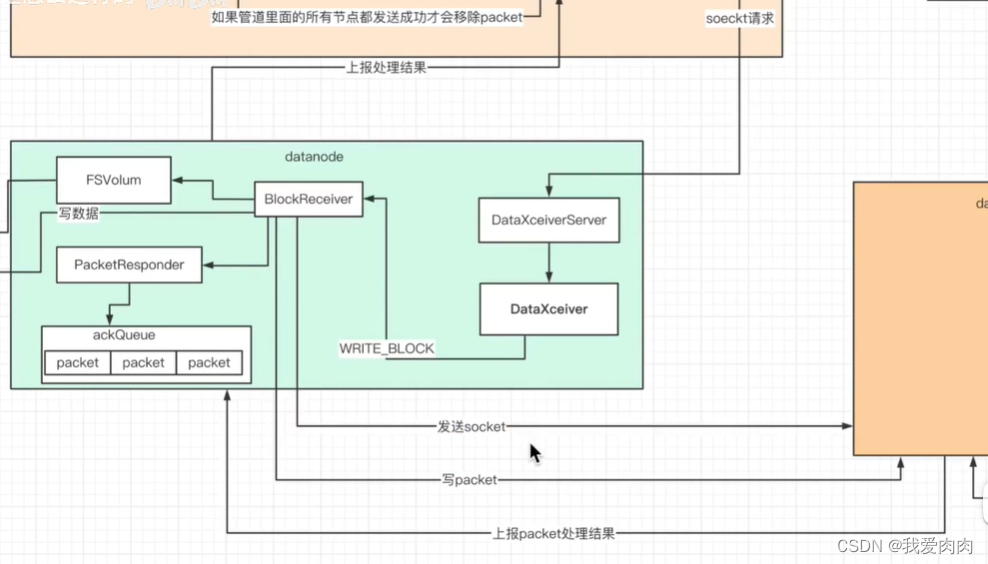
HDFS契约

HDFS写流程
1 创建INodeFile流程(数据封装成内存目录树)
2 添加文件契约流程
调用namenode rpc代理
底层是红黑树,实现按照契约时间排序
3 DataStreamer启动流程(重要!写数据关键服务)
等待DataQueue有数据后执行
备注:
一个目录包含多个文件,一个文件包含多个block(默认128mb),
一个block包含多个package(64k),一个package包含127个chunk
4 启动文件续约流程
datanode调用namenode rpc代理续约
数据结构内删除契约,修改上一次心跳时间,新契约加入数据结构
5 契约扫描机制
NameNode monitor线程周期性每2秒遍历所有契约,数据结构前面提过是排序的,
直接可拿出最老的契约时间遍历,当最老时间不过期直接break,提高效率
6 chunk封装成packet写入dataQueue
触发写dataQueue条件:写满127个chunk或写满128mb block
7 Block申请流程
namenode创建block,文件目录树记录block信息,磁盘记录元信息,BlockManager记录block元数据信息
8 pipeline数据管道流程建立
为什么需要数据管道传输(副本之间依次传输),而不是client直接同时传输数据到3个副本?
1 因为一般副本之间在同一机房/物理距离近,内网快/网络性能好
2 减轻client压力,只需要传输其中一个副本
备注:数据管道不是串行写,也就是不是第一个副本完全写完后再传递第二个副本。而是同时副本之间传递写
9 管道建立容错处理
建立不成功则放弃block,记录排除问题节点,重新选取block重试
10 ResponseProcessor组件初始化流程
11 BlockReceiver和PacketResponser初始化
12 写数据层上报处理结果
管道传输,副本上报返回处理结果
13 写数据容错分析
dataQueue会将数据放入ackQueue中,做数据容错
如果datanode收到上报结果已成功,才会删除ackQueue中数据
如果上报结果有异常,则会把ackQueue数据放入dataQueue重新数据处理,并删除ackQueue
一些问题总结

















 2429
2429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











