






1. 准备测试数据
DROP DATABASE IF EXISTS es;
CREATE DATABASE es DEFAULT CHARACTER SET utf8;
USE es;
CREATE TABLE book
(
id INT NOT NULL,
title VARCHAR(20),
author VARCHAR(20),
price DECIMAL(6,2),
PRIMARY KEY(id)
);
DROP PROCEDURE IF EXISTS batchInsertBook;
DELIMITER $$
CREATE PROCEDURE batchInsertBook(IN seed INT, IN loops INT)
BEGIN
DECLARE i INT;
DECLARE id INT;
SET i = 0;
SET id = seed;
WHILE i < loops DO
INSERT INTO book(id, title,author, price) VALUES
雪山飞狐', '金庸', 50),
神雕侠侣', '金庸', 60),
三国演义', '罗贯中', 50),
西游记', '吴承恩', 40);
SET id = id + 4;
SET i = i + 1;
END WHILE;
END $$
DELIMITER ;
-- 禁用索引,加快数据导入速度
ALTER TABLE book DISABLE KEYS;
-- 调用存储过程导入数据
CALL batchInsertBook(1, 10000);
-- 添加索引
ALTER TABLE book ENABLE KEYS;
-- 修改表的引擎为innodb
ALTER TABLE book ENGINE INNODB;
2. Logstash介绍
Logstash是一个开源的数据收集引擎,具有实时管道功能。Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地。
Logstash使用管道来进行数据的收集和输出,如下:
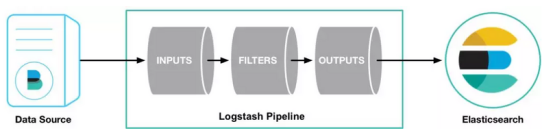
从上图可以看出,输入插件从数据源那里消费数据,过滤器插件根据你的期望来修改数据,输出插件将数据写入目的地。其中的INPUTS和OUTPUTS是必须要有的,中间的FILTERS是可选的。
INPUTS
Logstash支持各种输入方式,并可以捕捉来自不同输入源的不同事件:
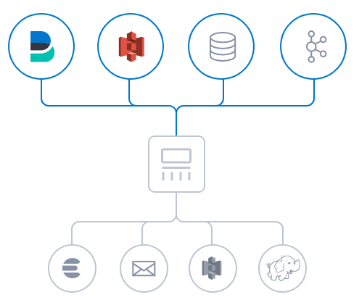
目前,Logstash主要支持的数据输入方式有:标准输入、文件输入、TCP输入、syslog输入、http_poller抓取、kafka消息队列等。
FILTERS
Logstash过滤器能够解析各种不同的输入源的不同事件,也能识别已命名的字段以构建出结构,并将这些构建好的结构转换成通用的数据格式:
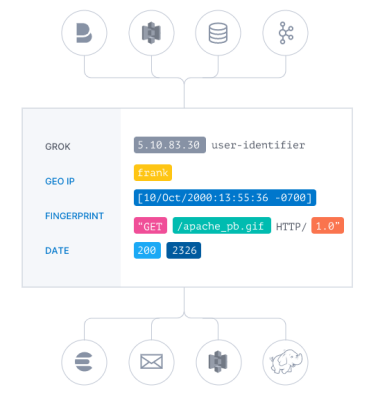
OUTPUT
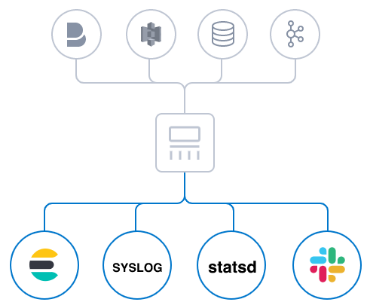
尽管 Elasticsearch 是我们首选的输出目的地,能够为我们的搜索和分析带来无限可能,但它并非唯一选择:
3 Docker安装Logstash
docker pull logstash:7.11.2
在宿主机配置目录
mkdir -p /root/logstash
在宿主机创建/root/logstash/logstash.yml,内容为空即可,该步骤不能省略
在宿主机创建/root/logstash/logstash.conf
input {
jdbc {
jdbc_driver_library => "/usr/share/logstash/mysql-connector-java-5.1.46.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://172.16.4.115:3306/es?characterEncoding=UTF-8&useSSL=false"
jdbc_user => "root"
jdbc_password => "123"
schedule => "* * * * *"
statement => "SELECT * FROM book"
type => "jdbc"
}
}
filter {
}
output {
stdout {
codec => json_lines
}
}
将mysql-connector-java-5.1.46.jar先传给宿主机
rz
同时记得设置mysql-connector-java-5.1.46.jar的权限为644
chmod 644 mysql-connector-java-5.1.46.jar
允许root远程登录
mysql -uroot -p123
use mysql;
update user set host = '%' where user = 'root';
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123';
FLUSH PRIVILEGES;
启动logstash容器
docker run -d \
-v /root/logstash/logstash.yml:/usr/share/logstash/config/logstash.yml \
-v /root/logstash/logstash.conf:/usr/share/logstash/pipeline/logstash.conf \
-v /root/logstash/mysql-connector-java-8.0.30.jar:/usr/share/logstash/mysql-connector-java-8.0.30.jar \
logstash:7.11.2
启动logstash容器,观察容器的控制台即可
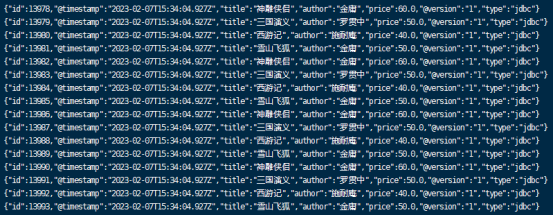
4 将数据输出到ElasticSearch
既然我们能从mysql中读取数据,并输出到stdout,那么我们同样可以从mysql中读取数据,然后将数据输出到ElasticSearch,修改logstash.conf,内容如下:
input {
jdbc {
jdbc_driver_library => "/usr/share/logstash/mysql-connector-java-5.1.46.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://192.168.1.105:3306/es?characterEncoding=UTF-8&useSSL=false"
jdbc_user => "root"
jdbc_password => "123"
schedule => "* * * * *"
statement => "SELECT * FROM book"
type => "jdbc"
}
}
filter {
}
output {
elasticsearch {
hosts => ["192.168.188.130:9200"]
index => "book"
document_id => "%{id}"
}
stdout {
codec => json_lines
}
}
确保elasticsearch容器是启动着的,然后重启logstash容器
docker restart logstash容器id
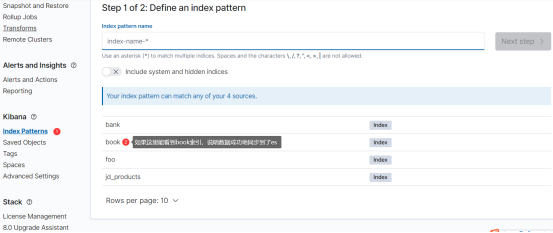
进而创建出book索引的 Index Pattern:
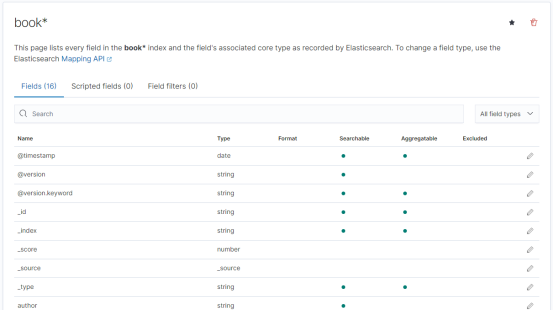
在Kibana中,再从book索引中检索数据:
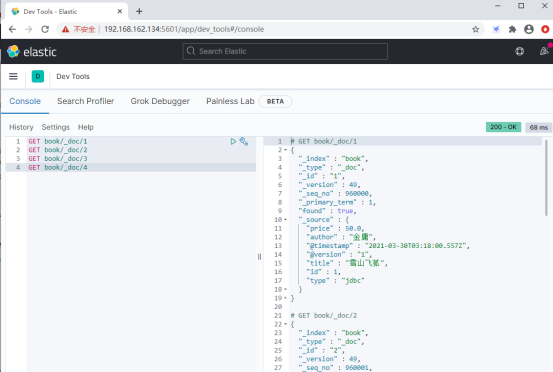
以上的这种同步数据的方式,我们称之为“全量同步”。
5 增量同步
修改logstash.conf,内容如下:
input {
jdbc {
jdbc_driver_library => "/usr/share/logstash/mysql-connector-java-5.1.46.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://192.168.1.105:3306/es?characterEncoding=UTF-8&useSSL=false"
jdbc_user => "root"
jdbc_password => "123"
schedule => "* * * * *"
type => "jdbc"
记录查询结果中,某个字段的值
use_column_value => true
记录id字段的值,用于增量同步
tracking_column => "id"
指明要记录的字段的类型
tracking_column_type => numeric
指定要记录上一次查询的数据
record_last_run => true
代表上次查询出来的最大的“tracking_column”中的值
statement => "SELECT * FROM book where id > :sql_last_value"
last_run_metadata_path => "syncpoint_table"
}
}
filter {
}
output {
elasticsearch {
hosts => ["192.168.188.130:9200"]
index => "book"
document_id => "%{id}"
}
stdout {
codec => json_lines
}
}
重启logstash容器查看效果即可:
















 8361
8361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









