







一、概述
机器语音系统的一个巨大缺点是机器人不知道如何“好好说话”。由于这个原因,它们无法合成自己的句子。它们需要人类来为它们编写一些语法规则,从而它们可以自己构造句子。
本文提出了一个M2M机器对话机器(Machines Talking To Machines)框架,它是一个结合自动化和众包模式的框架,可快速引导端到端对话智能体在任意域中进行目标导向的对话。换句话说,M2M是一个功能导向的流程,用于训练对话智能体(聊天机器人)。
其主要目标是通过与自动化任务无关的步骤来减少建立对话数据集所需的代价,从而对话开发者只需要提供对话的特定任务。
另一个目标是获得更高质量的对话。
本文引入了自对话(dialogue self-play)的概念,自对话是两个或者多个对话智能体通过选择离散对话行为进行交互,以尽可能地生成对话历史。论文中作者用一个基于议程的用户模拟器智能体 和一个基于有限状态机器的系统智能体,来进行自对话步骤。
二、M2M框架概述
M2M 只需要来自对话系统开发者的一个任务纲要(Task Schema)和一个 API 客户端就可以扩展到新的任务中去,但它也可以通过客户定制进行特定任务的交互。在数据收集方面,M2M 有丰富的多样性和更广泛的重要对话流的覆盖范围,同时保持了个人语言的自然性。
第一阶段,一个模拟用户机器人和一个领域不可知的系统机器人进行交谈,以尽可能生成对话“轮廓”(大纲Outlines),即模板对话和它们的语义解析。
第二阶段,众包人员(Crowd Workers)对对话进行上下文重写,以使对话更加自然,同时保持原来的含义。
整个过程可以在数小时内完成。文中用 M2M 收集了一个跨越两个领域的包含 3000 个对话的新语料库,并和流行的对话数据集在表层句子形式和对话流的质量、多样性上进行了比较。
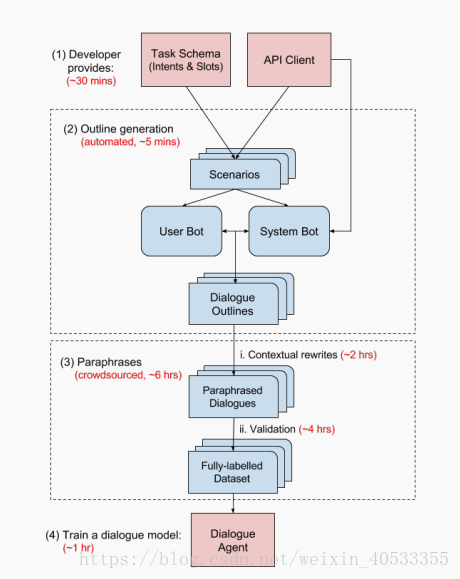
图 1:提出的 M2M 框架:(1)对话开发者提供一个任务纲要和一个 API 客户端。(2)自动化机器人生成对话大纲;(3)众包人员改写对话并验证 slot span; (4)使用监督学习在数据集上训练一个对话模型。整个流程可在 8 小时内完成。
2.1 框架第一部分解析
如图1所示,M2M连接一个提供任务纲要(Task Schema)和一个 API 客户端的对话系统开发者和一个框架,对话系统开发者提供特定的任务信息。框架提供与任务无关的信息,用于生成以完成任务为中心的对话。 形式上,框架F将任务规范T(task specification)映射成一组对话D:

每个对话di是一系列自然语言表达(Natuaral Language Utterances)(或对话轮次(Dialogue turns))uji及其对应的注释aji组成。aji包括该回合的语义解析以及与该回合相关的附加信息。
框架的输入是从对话开发者处得到的任务规范(Task Specification),任务规范定义了相关任务的对话交互的范围。
本文中主要关注是数据库查询应用程序,数据库查询应用程序主要包含用户通过语言对话选择的实体。实体的属性(即数据库的列)引起“slots”的模式S。每个slot是用户在选择实体时所关心的约束。例如图2a中,实体为movies。则slot是其后面的约束name,theatre等。开发人员必须提供API客户端C,C可以使用类似SQL的语法查询,以返回任何有效的slot值组合的匹配候选实体列表。
任务模式和API客户端一起形成任务规范,T =(S,C)。 (图2a)
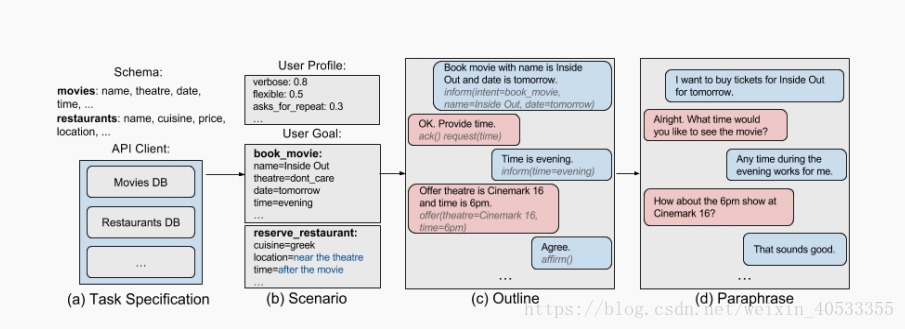
图 2:生成大纲与段落的示例。
2.2 框架第二部分解析(图2b,2c)
框架F生成特定任务对话框的过程,可分为两步进行:
F=F1 * F2
F1:将任务规范T映射到一组大纲O
F2:将每个大纲映射O到自然语言对话D

Oi:为一系列模板话语ti及其相应的注释ai组成。
ti:是一种简单的语句,使用一些规则就很容易生成语言。
为了生成大纲,框架首先从任务规范中抽取一个场景(Scenario)。并将场景定义为用户配置文件(User profile)和用户目标(User goals),即si =(pi,gi)(图2b)。在面向目标的对话中,用户希望在对话智能体的帮助下完成目标,例如预订电影票或预订餐馆。
每个目标都与映射到架构的slot的约束相关联,例如电影名称,流派,票证数量和价格范围。用户目标中的slot可以具有固定值(例如,电影流派是“喜剧”),或者是可能值的列表(例如,流派应该是“喜剧”或“动作”),又或者是灵活的值(例如“喜剧“是首选,但用户看到任何类型的电影)。在多领域设置中,目标的slot 值可以参考先前的目标,例如,用户可能想要购买电影票,然后在看完电影后通过前面的子对话中选择出电影院附近的餐馆吃晚餐。
场景生成器(Scenario Generator)随机地从任务规范(Task Specification)中对目标gi进行采样,并为架构中的每个slot选择约束类型和值。对话流还取决于用户的性格。
通过定义用户配置文件向量pi(user profile vector)用来封装用户行为的所有与任务无关的特征。场景生成器从指定的用户配置文件分布对pi进行采样。利用对话场景si,框架在用户机器人BU和系统机器人BS之间执行self-play后生成轮次注释(turn annotation)序列a1i..... ani

每个ai包含一个对话框(dialogue frame),它将转向的语义编码(Encodes The Semantics)变为对话行为(Dialogue Act)和slot值的映射。表4列出了对话行为的完整列表。

通过self-play的作用下(图2c),从每个机器人迭代采样得到的新的轮次注释ai。直到用户以“再见()”动作或达到最大轮次则退出对话。
论文中BU是一个基于议程的用户模拟器(agenda-based user simulator),其修改了用户配置文件中的动作选择模型(action selection model)。
BS为一个有限状态机(finite state machine),它编码一组独立于任务的规则来构造系统轮次(system turns),每个turn由一个响应框架(响应用户之前的turn)和一个启动框架(启动框架通过子对话序列推动对话)组成。
模板话语生成器(template utterance generator)将每个turn 中的映射转为ai→ti。
ti:是模板话语(template utterance)。ti是turn注释ai和相应的自然语言表达uj之间的重要桥梁。
2.3 框架第三部分解析
为了从其大纲中获得更加自然的语言对话 F2({oi})→{di}。该框架采用众包(crowdsourcing)来将模板话语tji转换为更自然的话语uji。
转义任务(paraphrase task)是流程第三部分,它被设计为“上下文重写”(contextual rewrite)任务,其中众包人员(crowd workers)可以看到每一轮次对话完整的tji和uji。
上下文重写任务的屏幕截图界面如图3所示。
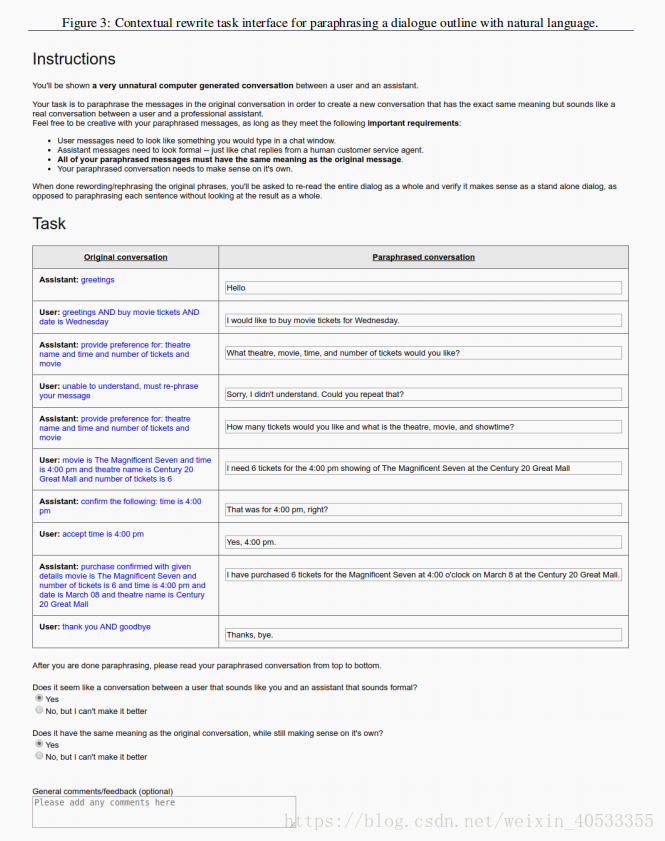
由于tji和uji表达的内容是一样的,aji会自动应用于uji,从而消除了对昂贵的注释步骤的需要。每个uji都会询问两个众包人员是否具有与tji相同的含义,并且如果其中一个众包人员否定,则放弃该表达。
通过众包步骤F2收集的重写t→{u}k被编译成映射L(a)→{u}k即可。
这也可以用来扩展数据集。这部分说明在下面第三部分总结中会说明。
2.4框架第四部分
当有了这些数据集后,就可以训练语言模型了。例如:可以训练以下模型:用于语言理解的组件模型,对话政策和语言生成,端到端模型等。
三、总结
通俗的说本文描述的这个框架是一个可用于训练聊天机器人说自然语言的协议并且可以生成数据集。但是它仍然需要大量的人力。M2M的工作方式和流程第二部分已经概述,这里说下如何生成数据集。简单的说通过对话self-play生成大纲,然后使用众包(crowd sourcing)来重写模板话语。文章中对数据集的多样性和质量进行了评估。结果显示数据集还不错。
最后这个框架的源代码我在GitHub上没有找到,可能官方没有发布,但是他们发布了通过框架生成的数据集。

表 1:用 M2M 收集的对话

表 2:DSTC2 与 M2M Restaurant 数据集在语言与对话流多样性的对比。

表 3:用 M2M 收集的对话的人类评价。众包人员对用户与系统对话给出得分的平均值(1-5 分), 括号内是标准偏差。

表5:给出了一个完整的对话框和对应的释义.(跨越两个相互依赖的任务的对话,其中用户想要先购买电影票,然后在电影之后预订餐桌)。

图4:对话质量评估任务界面,用于评估用户和已完成对话的系统轮次。















 799
799











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









