







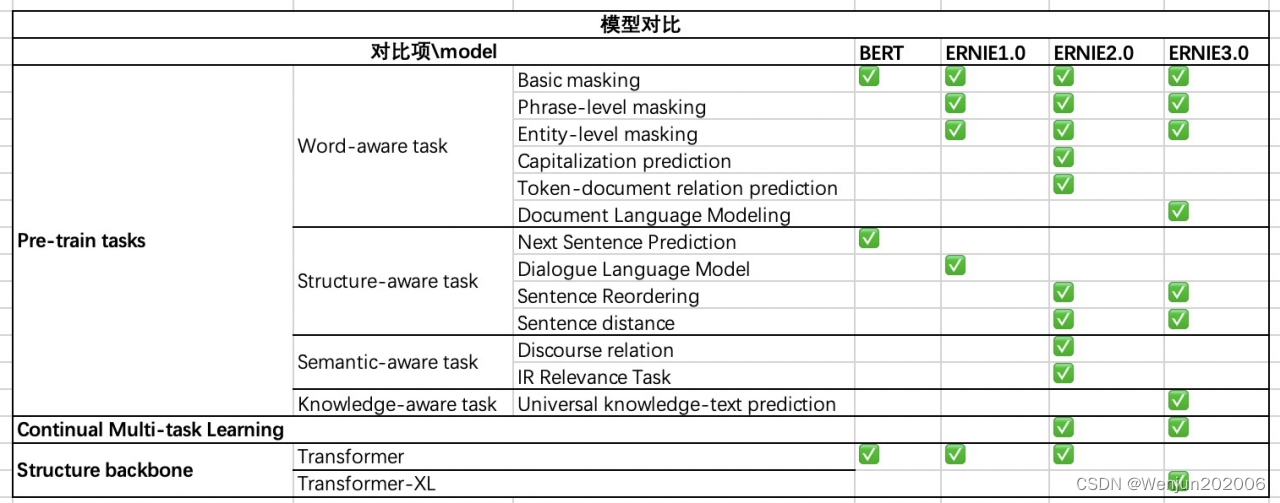
总结:ERNIE 3.0与ERNIE 2.0比较
(1)相同点:
采用连续学习
采用了多个语义层级的预训练任务
(2)不同点:
ERNIE 3.0 Transformer-XL Encoder(自回归+自编码), ERNIE 2.0 Transformer Encoder(自编码)
预训练任务的细微差别,ERNIE3.0里增加的知识图谱
ERNIE 3.0考虑到不同的预训练任务具有不同的高层语义,而共享着底层的语义(比如语法,词法等),为了充分地利用数据并且实现高效预训练,ERNIE 3.0中对采用了多任务训练中的常见做法,将不同的特征层分为了通用语义层(Universal Representation)和任务相关层(Task-specific Representation)。
参考
- Sun Y, Wang S, Li Y, et al. Ernie: Enhanced representation through knowledge integration[J]. arXiv preprint arXiv:1904.09223, 2019.
- Sun Y, Wang S, Li Y, et al. Ernie 2.0: A continual pre-training framework for language understanding[C]//Proceedings of the
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2756
2756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









