









最近在做一个数据挖掘类的比赛,关于心电图分类的。因为是数据挖掘的比赛,又刚好我最近工作需要用到Jupyter notebook,那就先来熟悉熟悉Jupyter notebook这个工具的使用。
Jupyter notebook的使用
Jupyter notebook它虽然没有像Pycharm那样的强大调试功能,但是它有逐行调试、逐单元格运行的功能,十分方便,也可以展示代码的逻辑,使之看起来更加整洁、清晰,拥有强大的交互能力。在编写代码的同时还可以使用Markdown来作笔记,写下你的结论,注释等。
当然,你可以将它转为PDF,HTML,PPT等格式。

新建Jupyter notebook文档
1.进入到你所需要编写的那个目录,在CMD窗口中输入:jupyter notebook即可打开,系统会自动帮助你打开浏览器中的Jupyter notebook。

2.新建文档,点击右上方那个new就可以了。Python3代表建立ipynb文件;R:R文件;Text File:文本文件;Folder:文件夹;Terminal:终端

3.然后你可以给新建的untitle文件修改名字。有两种方法:第一是点击左上角File中的rename。二是点击文档上方的那大标题直接编辑。

单元格的操作
单元格的基本操作应该就下面这些,更多的操作可以自己去探索,还可以类似vs code一样安装插件,提高编码效率。

绿色的轮廓线所在的单元格,就是当前工作单元。在这个单元格里输入你想要的内容,然后shift + Enter就可以运行单元格的内容了。


两种模式与快捷键
对于Notebook中的单元,有两种模式:命令模式(Command Mode)与编辑模式(Edit Mode),在不同模式下我们可以进行不同的操作。

如上图,在编辑模式(Edit Mode)下,右上角出现一只铅笔的图标,单元左侧边框线呈现出绿色,点Esc键或运行单元格(ctrl-enter)切换回命令模式。
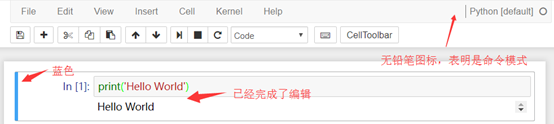
在命令模式(Command Mode)下,铅笔图标消失,单元左侧边框线呈现蓝色,按Enter键或者双击cell变为编辑状态。
并且Jupyter notebook有着和vim差不多便捷的快捷键:


不需要刻意去背,用多了就好,毕竟熟能生巧。
Markdown的用法
用于编辑文本的markdown也是用多就可以记住了,它这个也是很简洁,风格我十分喜欢。

kernel
其实Jupyter notebook就是依赖于一个内核进行运行,可以理解为python运行的依赖环境,解释器。

读取心电图的数据
终于到了本次的主题:进行心电图的分类。在这里,我们只进行对数据的读取。
这里的任务是来自天池比赛的预测心电图心跳信号类别。 数据来自某平台心电图数据记录,可以去天池官网下载。总数据量超过20万,主要为1列心跳信号序列数据,其中每个样本的信号序列采样频次一致,长度相等。 从中抽取10万条作为训练集,2万条作为测试集A,另外抽取2万条作为测试集B,同时会对心跳信号类别(label)信息进行脱敏。
Field Description id 为心跳信号分配的唯一标识 heartbeat_signals 心跳信号序列 label 心跳信号类别(0、1、2、3)
import pandas as pd
import numpy as np
path='../dataset/'
train_data = pd.read_csv(path + 'train.csv')
test_data = pd.read_csv(path + 'testA.csv')
print('Train data shape:', train_data.shape)
print('TestA data shape:', test_data.shape)

train_data.head()

接下来就是经典的混淆矩阵,来计算准确率,精确率,召回率这一些数据挖掘中经常使用到的指标。
准确率(Accuracy) 准确率是常用的一个评价指标,但是不适合样本不均衡的情况,医疗数据大部分都是样本不均衡数据。 A c c u r a c y = C o r r e c t T o t a l A c c u r a c y = T P + T N T P + T N + F P + F N Accuracy=\frac{Correct}{Total}\ Accuracy = \frac{TP + TN}{TP + TN + FP + FN} Accuracy=TotalCorrect Accuracy=TP+TN+FP+FNTP+TN 精确率(Precision)也叫查准率简写为P
精确率(Precision)是针对预测结果而言的,其含义是在被所有预测为正的样本中实际为正样本的概率在被所有预测为正的样本中实际为正样本的概率,精确率和准确率看上去有些类似,但是是两个完全不同的概念。精确率代表对正样本结果中的预测准确程度,准确率则代表整体的预测准确程度,包括正样本和负样本。
P
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
Precision = \frac{TP}{TP + FP}
Precision=TP+FPTP 召回率(Recall) 也叫查全率 简写为R
召回率(Recall)是针对原样本而言的,其含义是在实际为正的样本中被预测为正样本的概率。 R e c a l l = T P T P + F N Recall = \frac{TP}{TP + FN} Recall=TP+FNTP
下面我们通过一个简单例子来看看精确率和召回率。假设一共有10篇文章,里面4篇是你要找的。根据你的算法模型,你找到了5篇,但实际上在这5篇之中,只有3篇是你真正要找的。
那么算法的精确率是3/5=60%,也就是你找的这5篇,有3篇是真正对的。算法的召回率是3/4=75%,也就是需要找的4篇文章,你找到了其中三篇。以精确率还是以召回率作为评价指标,需要根据具体问题而定。
混淆矩阵(Confuse Matrix)
(1)若一个实例是正类,并且被预测为正类,即为真正类TP(True Positive )
(2)若一个实例是正类,但是被预测为负类,即为假负类FN(False Negative )
(3)若一个实例是负类,但是被预测为正类,即为假正类FP(False Positive )
(4)若一个实例是负类,并且被预测为负类,即为真负类TN(True Negative )
第一个字母T/F,表示预测的正确与否;第二个字母P/N,表示预测的结果为正例或者负例。如TP就表示预测对了,预测的结果是正例,那它的意思就是把正例预测为了正例。
from sklearn.metrics import accuracy_score, precision_score, recall_score
from sklearn.metrics import f1_score
y_true = [1, 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 4, 4,5,5,6,6,6,0,0,0,0] #真实值
y_pred = [1, 1, 1, 3, 3, 2, 2, 3, 3, 3, 4, 3, 4, 3,5,1,3,6,6,1,1,0,6] #预测值
#计算准确率
print("accuracy:", accuracy_score(y_true, y_pred))
#计算精确率
#计算macro_precision
print("macro_precision", precision_score(y_true, y_pred, average='macro'))
#计算micro_precision
print("micro_precision", precision_score(y_true, y_pred, average='micro'))
#计算召回率
#计算macro_recall
print("macro_recall", recall_score(y_true, y_pred, average='macro'))
#计算micro_recall
print("micro_recall", recall_score(y_true, y_pred, average='micro'))
#计算F1
#计算macro_f1
print("macro_f1", f1_score(y_true, y_pred, average='macro'))
#计算micro_f1
print("micro_f1", f1_score(y_true, y_pred, average='micro'))

比赛计算的公式为:平均指标abs-sum。 比如说:针对某一个信号,若真实值[y1, y2, y3, y4]的预测值为[a1, a2, a3, a4],那么就通过上述公式进行计算。 例如:心跳信号为1时,通过编码可转为[0, 1, 0, 0],预测为不同心跳信号的概率为[0.1, 0.7, 0.1, 0.1],那么通过上述公式,得: abs-sum = |0.1 - 0| + |0.7 - 1| + |0.1 - 0| + |0.1 - 0| = 0.6
def abs_sum(y_pre,y_tru):
#y_pre为预测概率矩阵
#y_tru为真实类别矩阵
y_pre=np.array(y_pre)
y_tru=np.array(y_tru)
loss=sum(sum(abs(y_pre-y_tru)))
return loss
















 157
157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









