







卷积神经网络+Text-Text
一、卷积神经网络
1.1 卷积
卷积(Convolution),其实是一种数学运算,在信号处理或图像处理中,经常使用一维卷积或二维卷积。
1.1.1 一维卷积
一维卷积经常用在信号处理中,用于计算信号的延迟累积。
假设一个信号发生器每个时刻
t
t
t产生一个信号
x
t
x_t
xt ,其信息的衰减率为
w
k
w_k
wk,即在
k
−
1
k-1
k−1个时间步长后,信息为原来的
w
k
w_k
wk倍。
假设
w
1
=
1
,
w
2
=
1
/
2
,
w
3
=
1
/
4
w_1=1,w_2=1/2,w_3=1/4
w1=1,w2=1/2,w3=1/4,那么在时刻
t
t
t收到的信号
y
t
y_t
yt为当前时刻产生的信息和以前时刻延迟信息的叠加,
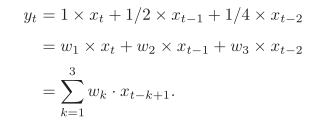
我们把
w
1
,
w
2
,
.
.
.
w_1,w_2,...
w1,w2,...称为滤波器(Filter)或卷积核(Convolution Kernel)。假设滤波器长度为
m
m
m,它和一个信号序列
x
1
,
x
2
,
.
.
.
x_1,x_2,...
x1,x2,...的卷积为

信号序列
x
x
x和滤波器
w
w
w的卷积定义为:

一般情况下滤波器的长度
m
m
m远小于信号序列长度
n
n
n,当滤波器
f
k
=
1
/
m
,
1
<
=
k
<
=
m
f_k=1/m,1<=k<=m
fk=1/m,1<=k<=m时,卷积相当于信号序列的移动平均。
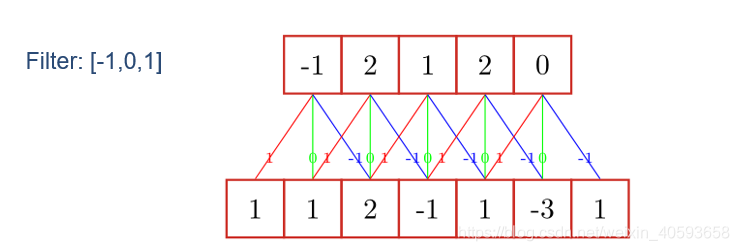
一维卷积的示意图如下:
1.1.2 二维卷积
在图像处理中,图像是以二维矩阵的形式输入到神经网络中,因此我们需要二维卷积。
给定一个图像
X
∈
R
M
×
N
X∈R^{M×N}
X∈RM×N ,和滤波器
W
∈
R
m
×
n
W∈R^{m×n}
W∈Rm×n
一般
m
<
<
M
,
n
<
<
N
m<<M,n<<N
m<<M,n<<N,其卷积为:
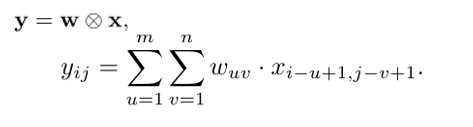
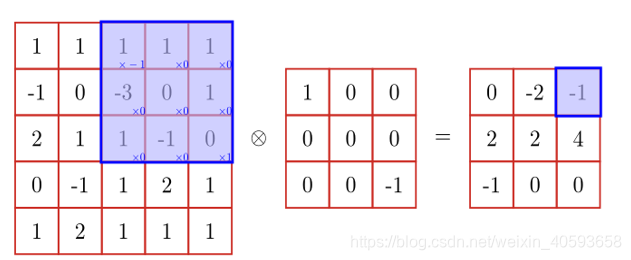
卷积操作的示例:
在图像处理中,卷积经常作为特征提取的有效方法。一幅图像在经过卷积操作后得到结果称为特征映射(Feature Map)。下图给出在图像处理中几种常用的滤波器,以及其对应的特征映射。图中最上面的滤波器是常用的高斯滤波器,可以用来对图像进行平滑去噪;中间和最下面的过滤器可以用来提取边缘特征。
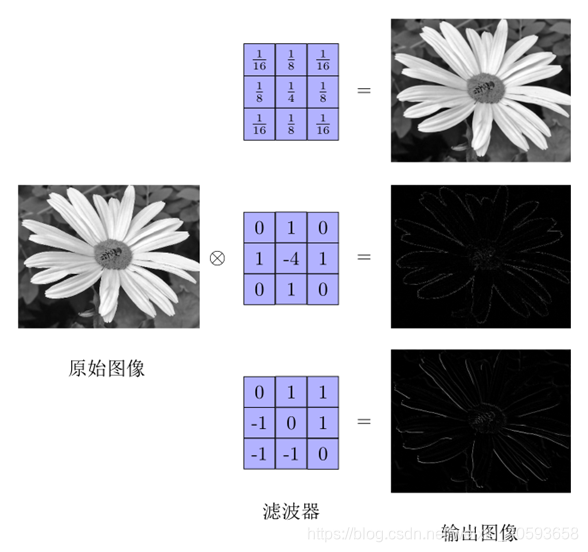
卷积种类
假设卷积层的输入神经元个数为
n
n
n,卷积大小为
m
m
m,步长(stride)为
s
s
s,输入神经元两端各填补
p
p
p个零(zero padding),那么该卷积层的神经元数量为
(
n
−
m
+
2
p
)
/
s
+
1
(n − m + 2p)/s + 1
(n−m+2p)/s+1。
- 窄卷积(Narrow Convolution):步长 s = 1 s = 1 s=1,两端不补零 p = 0 p = 0 p=0,卷积后输出长度为 n − m + 1 n − m + 1 n−m+1。
- 宽卷积(Wide Convolution):步长 s = 1 s = 1 s=1,两端补零 p = m − 1 p = m− 1 p=m−1,卷积后输出长度 n + m − 1 n + m − 1 n+m−1。
- 等宽卷积(Equal-Width Convolution):步长 s = 14 , 两 端 补 零 ¥ p = ( m − 1 ) / 2 ¥ , 卷 积 后 输 出 长 度 s = 14,两端补零¥p = (m−1)/2¥,卷积后输出长度 s=14,两端补零¥p=(m−1)/2¥,卷积后输出长度n$。
卷积层的作用是提取一个局部区域的特征,不同的卷积核相当于不同的特征提取器,并减少参数数量,卷积层有两大特性:
- 局部连接:在卷积层(假设是第 l l l层)中的每一个神经元都只和下一层(第 l − 1 l-1 l−1 层)中某个局部窗口内的神经元相连,构成一个局部连接网络。如下图所示,卷积层和下一层之间的连接数大大减少,由原来的 n l ∗ n l − 1 n^l*n^{l-1} nl∗nl−1变为 n l ∗ m n^l*m nl∗m, m m m为滤波器大小
- 权重共享:作为参数的滤波器
w
(
l
)
w^{(l)}
w(l) 对于第
l
l
l 层的所有的神经元都是相同的。下图中,所有的同颜色连接上的权重是相同的.
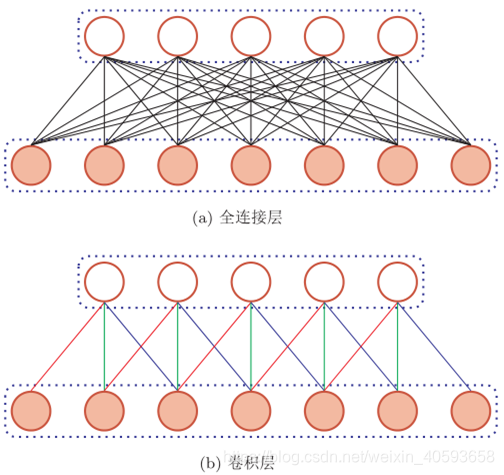
由于局部连接和权重共享,卷积层的参数只有一个 m m m维的权重 w ( l ) w^{(l)} w(l) 和1维的偏置 b ( l ) b^{(l)} b(l),共 m + 1 m + 1 m+1 个参数。参数个数和神经元的数量无关。此外,第 l l l 层的神经元个数不是任意选择的,而是满足 n ( l ) = n ( l − 1 ) − m + 1 n^{(l)}=n^{(l−1)}−m+1 n(l)=n(l−1)−m+1
1.1.3 卷积网络—动机
卷积运算运用三个重要的思想来帮助改进机器学习系统 :稀疏交互(sparse interactions)、参数共享(parameter sharing)、等变表示(equivariant pepresentations)。
传统的神经网络使用矩阵乘法来建立输入与输出的连接关系。其中,参数矩阵中每一个单独的参数都描绘了一个输入单元与一个输出单元之间的交互,这其实就意味着每一个输出单元与每一个输入单元都产生交互 ,but 卷积网络具有稀疏交互的特征 。然后呢,呵呵,举个例子:
当处理一张图像时,输入的图像可能包含成千上万个像素点 ,但是我们可以通过只占用几十个到上百个像素点的核来检测一些小的有意义的特征 ,比如说图像的边缘。。。。
这么一来呢,我们所需存储的参数就减少了,那么统计效率也就蹭蹭地上去了。
参数共享:是指 在一个模型的多个函数中使用相同的参数。
卷积运算中的参数共享保证了我们只需要学习一个参数集合,而不是对于每一个位置都需要需学习一个单独的参数集合。
平移等变:参数共享的特殊形式使得神经网络具有平移等变的性质。
If一个函数满足输入改变,输出也以同样的方式改变的这一性质,我们就说它是等变的(equivariant).特别的是:如果函数
f
(
x
)
f(x)
f(x)和
g
(
x
g(x
g(x满足这个性质:
f
(
g
(
x
)
)
=
g
(
f
(
x
)
)
f(g(x))=g(f(x))
f(g(x))=g(f(x)),那么我们就说
f
(
x
)
f(x)
f(x)对于
g
(
x
)
g(x)
g(x)具有等变性。
卷积对于一些变换不是天然等变的,比如说图像的缩放或者旋转变换的呢,需要其他机制来处理。
1.1.4 一维卷积运算和二维卷积运算
参考:https://www.cnblogs.com/dasein/p/5692153.html
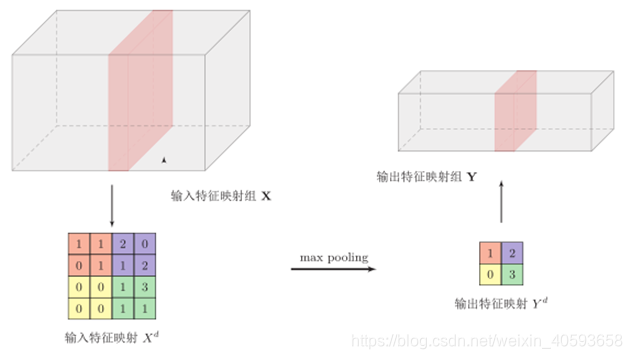
1.2 池化层
池化层(Pooling Layer)也叫子采样层(Subsampling Layer),其作用是进行特征选择,降低特征数量,并从而减少参数数量。
卷积层虽然可以显著减少网络中连接的数量,但特征映射组中的神经元个数并没有显著减少。如果后面接一个分类器,分类器的输入维数依然很高,很容易出现过拟合。为了解决这个问题,可以在卷积层之后加上一个汇聚层,从而降低特征维数,避免过拟合。
常用的池化操作:
-
最大池化:一般是取一个区域内所有神经元的最大值。
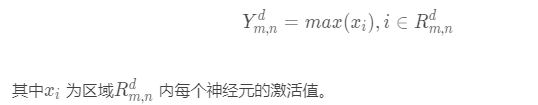
-
平均池化: 一般是取区域内所有神经元的平均值。
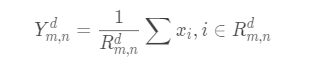
二、Text-CNN
参考:https://blog.csdn.net/weixin_40593658/article/details/90522840
参考:
https://blog.csdn.net/xh999bai/article/details/89483673
https://www.jianshu.com/p/e3824e8fd115
https://blog.csdn.net/chuchus/article/details/77847476















 930
930











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









