







1. 分析图1(注:图1是2级页表,对应于IA-32位系统),解释图中每一类方框和箭头的含义,在代码树中寻找相关数据结构片段,做简单解释。

(1)Linux进程描述符task_struct结构体
在上次大作业中我们同样分析task_struct结构体,上次分析的部分是关于进程调度的,而由图中可以看出结构体中的mm_struct与这次内存管理实验主要相关
//task_struct结构体定义在include/linux/sched.h文件
//关于进程的地址空间,指向进程的地址空间。(链表和红黑树)
struct mm_struct *mm, *active_mm;
//mm 进程所拥有的用户空间内存描述符,内核线程无的mm为NULL
//active_mm active_mm 指向进程运行时所使用的内存描述符,对于普通进程而言,这两个指针变量的值相同。但是内核线程 kernel thread是没有进程地址空间的,所以内核线程的tsk->mm域是空(NULL)。但是内核必须知道用户空间包含了什么, 因此它的active_mm成员被初始化为前一个运行进程的active_mm值。
(2)内存描述符 mm_struct
-
一个进程的虚拟地址空间主要由两个数据结来描述。一个是最高层次的:mm_struct,一个是较高层次的:vm_area_structs。最高层次的mm_struct结构描述了一个进程的整个虚拟地址空间。较高层次的结构vm_area_truct描述了虚拟地址空间的一个区间。
-
每一个进程都会有自己独立的mm_struct,这样每一个进程都会有自己独立的地址空间,这样才能互不干扰。
//mm_struct 定义在include/linux/mm_types.h
//这里我们提取mm_struct结构体中的 mmap和pgd 进行分析
//指向虚拟区间(VMA)的链表
struct vm_area_struct * mmap;
//指向页全局目录
pgd_t * pgd;(3)内存映射mmap和结构体 vm_area_struct
- Linux的虚拟内存管理是基于mmap来实现的,vm_area_struct是在mmap的时候创建的,代表一段连续的虚拟地址,这些虚拟地址相应地映射到一个后备文件或者一个匿名文件的虚拟页。一个vm_area_struct映射到一组连续的页表项,页表项又指向物理内存page,这样就把一个文件和物理内存页相映射。
- 虚拟地址的映射过程:拿到一个虚拟地址,根据已有的vm_area_struct看这个虚拟地址是否属于某个vm_area_struct
- 如果没有匹配到,就报段错误,访问了一个没有分配的虚拟地址。
- 如果匹配到了vm_area_struct,根据虚拟地址和页表的映射关系,找到对应的页表项PTE,如果PTE没有分配,就报一个缺页异常,去加载相应的文件数据到物理内存,如果PTE分配,就去相应的物理页的偏移位置读取数据
//Linux通过类型为vm_area_struct的结构体对象实现线性区,该结构定义了内存VM内存区域。
//分析部分代码
struct vm_area_struct {
//vm_area_struct结构所描述的虚存空间以vm_start、vm_end成员表示,它们分别保存了该虚存空间的首地址和末地址后 第一个字节的地址,以字节为单位,所以虚存空间范围可以用[vm_start, vm_end)表示。
unsigned long vm_start;
unsigned long vm_end;
//每个任务的VM区域的链接列表,按地址排序
struct vm_area_struct *vm_next, *vm_prev;
struct mm_struct *vm_mm; //我们所属的address space
pgprot_t vm_page_prot; // 此VMA的访问权限
unsigned long vm_flags; //vm_flags主要保存了进程对该虚存空间的访问权限,然后还有一些其他的属性。
/*
对于具有地址空间(address apace)和后备存储(backing store)的区域,
链接到address_space->i_mmap间隔树,或者链接到address_space-> i_mmap_nonlinear列表中的vma。
*/
union {
struct {
struct rb_node rb;
unsigned long rb_subtree_last;
} linear;
struct list_head nonlinear;
} shared;
//处理匿名文件共享内存映射的情况,映射到同一物理内存页的映射都保存在一个链表中
struct anon_vma *anon_vma;
/* 用于处理此结构体的函数指针 */
const struct vm_operations_struct *vm_ops;
/* 后备存储(backing store)的信息: */
//处理有后备文件内存映射的情况,获得该映射在文件的页偏移量,以及打开文件file实例的信息
unsigned long vm_pgoff; /* 以PAGE_SIZE为单位的偏移量(在vm_file中),*不是* PAGE_CACHE_SIZE*/
struct file * vm_file; /* 我们映射到文件(可以为NULL)*/
void * vm_private_data; /* 是vm_pte(共享内存) */
};
结构体vm_area_struct与用户进程空间,如下图对应结构体指向用户进程线性区

(4)结构体 vm_operations_struct
//该结构体定义在/include/linux/mm.h
//Linux利用了面向对象的思想,即把一个虚拟区间看成一个对象,用vm_area_structs描述了这个对象的属性,其中的vm_operation结构描述了在这个对象上的操作
struct vm_operations_struct {
void (*open)(struct vm_area_struct * area);
void (*close)(struct vm_area_struct * area);
struct page * (*nopage)(struct vm_area_struct * area, unsigned long address, int unused);
};
//vm_operations结构中包含的是函数指针;其中,open、close分别用于虚拟区间的打开、关闭,而nopage用于当虚存页面不在物理内存而引起的“缺页异常”时所应该调用的函数。(5)二级页表结构
-
页目录表 pgd
-
每个进程有一个属于自己的页目录表,可通过 CR3 寄存器找到
- 而内核也有一个独立于其它进程的页目录表,保存在 swapper_pg_dir[] 数组中
- 当进程切换的时候,只需要将新进程的页目录把地址加载到 CR3 寄存器中即可
- 创建一个新进程的时候,需要为它分配一个 page,作为页目录表,并将swapper_pg_dir[] 的高256项拷贝过来,低768项则清0
-
页表含有220(1M)个表项,而每项占用4Byte。如果作为一个表来存放的话,它们最多将占用4MB的内存。因此为了减少内存占用量,80x86使用了两级表。由此,高20位线性地址到物理地址的转换也被分成两步来进行,每步使用(转换)其中的10bit。
- 第一级表称为页目录(page directory)。它被存放在1页4K页面中,具有210(1K)个4Byte长度的表项。这些表项指向对应的二级表。线性地址的最高10位(位31~22)用作一级表(页目录)中的索引值来选择210个二级表之一。
- 第二级表称为页表(page table),它的长度也是1个页面,最多含有1K个4B的表项。每个4B表项含有相关页面的20位物理基地址。二级页表使用线性地址中间10位(位 21~12)作为表项索引值,以获取含有页面20位物理基地址的表项。该20位页面物理基地址和线性地址中的低12位(页内偏移)组合在一起就得到了分页转换过程的输出值,即对应的最终物理地址。
-
mem_map是一个struct page的数组,管理着系统中所有的物理内存页面。在系统启动的过程中,创建和分配mem_map的内存区域。UMA体系结构中,free_area_init()函数在系统唯一的struct node对象contig_page_data中node_mem_map成员赋值给全局的mem_map变量。
调用的关系图如下

- 主要的核心函数free_area_init_core(),为node的初始化过程分配本地的lmem_map(node->node_mem_map)。
- 数组的内存在boot memory 分配的alloc_bootmem_node()函数分配.
- 在UMA体系结构中,这个新分配的lmem_map成为全局的mem_map.
- 对于NUMA体系,lmem_map赋值给每一个node的node_mem_map成员,而这个情况下mem_map就被简单的赋值为PAGE_OFFSET;
- UMA体系中,node中的各个zone的zone_mem_map就指向mem_map中的某些元素作为zone所管理的第一个page的地址。
//出于节省内存的考虑,struct page中使用了大量的联合体union
//在mem_map[]结构中找到对应的struct page结构体
struct page {
unsigned long flags; /* 原子标志,有些情况下会异步更新 */
atomic_t _count; /* 使用计数,见下文。 */
union {
atomic_t _mapcount; /* 内存管理子系统中映射的页表项计数,
* 用于表示页是否已经映射,还用于限制逆向映射搜索。
*/
unsigned int inuse; /* 用于SLUB分配器:对象的数目 */
};
union {
struct {
unsigned long private; /* 由映射私有,不透明数据:
*如果设置了PagePrivate,通常用于buffer_heads;
*如果设置了PageSwapCache,则用于swp_entry_t;
* 如果设置了PG_buddy,则用于表示伙伴系统中的阶。
*/
struct address_space *mapping; /* 如果最低位为0,则指向inode
* address_space,或为NULL。
* 如果页映射为匿名内存,最低位置位,
* 而且该指针指向anon_vma对象:
* 参见下文的PAGE_MAPPING_ANON。
*/
};
...
struct kmem_cache *slab; /* 用于SLUB分配器:指向slab的指针 */
struct page *first_page; /* 用于复合页的尾页,指向首页 */
};
union {
pgoff_t index; /* 在映射内的偏移量 */
void *freelist; /* SLUB: freelist req. slab lock */
};
struct list_head lru; /* 换出页列表,例如由zone->lru_lock保护的active_list!
*/
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* 内核虚拟地址(如果没有映射则为NULL,即高端内存) */
#endif /* WANT_PAGE_VIRTUAL */
};(6)进程的线性空间
在linux的内存管理中,用户使用0~3GB的地址空间,而内核只是用了3GB~4GB区间的地址空间,共1GB;非连续空间的物理映射就位于3GB~4GB之间

进程的4G 线性空间被划分成三个部分:进程空间(0-3G)、内核直接映射空间(3G – high_memory)、内核动态映射空间(VMALLOC_START - VMALLOC_END)
- 三个空间使用同一张页目录表,通过 CR3 可找到此页目录表。但不同的空间在页目录表中页对应不同的项,因此互相不冲突
- 内核初始化以后,根据实际物理内存的大小,计算出 high_memory、VMALLOC_START、VMALLOC_END 的值。并为“内核直接映射”空间建立好映射关系,所有的物理内存都可以通过此空间进行访问。
- “进程空间”和“内核动态映射空间”的映射关系是动态建立的(通过缺页异常)
关于内核空间中这1GB的分配

-
通常会把内核空间中大于896M的空间称作内核空间中的高端内存。内核可以用三种不同的机制将页框映射到高端内存:永久内核映射、临时内核映射和非连续内存分配。
-
非连续内存的线性地址空间是从VMALLOC_START~VMALLOC_END,共128MB大小。当内核需要用vmalloc类的函数进行非连续内存分配时,就会申请一个vm_struct结构来描述对应的vmalloc区,若分配多个vmalloc的内存区,那么相邻两个vmalloc区之间的间隔大小至少为4KB,即至少是一个页框大小PAGE——SIZE。 如下图所示
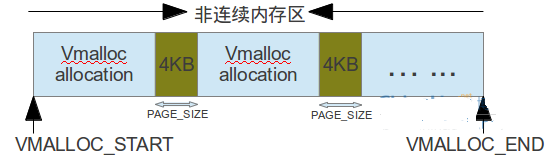
//vm_struct结构体在include/linux/vmalloc.h中定义
struct vm_struct {
struct vm_struct *next; //指向下一个vm_struct区,所有非连续区组成一个单链表
void *addr; //代表每个内存区的起始地址,即指向申请的内存区的第一个内存单元(线性地址) unsigned long size; //当前所申请的内存区大小加4KB(安全区)
unsigned long flags; //标识内存区类型
struct page **pages; //指向nr_pages页描述符指针数组的指针
unsigned int nr_pages; //所申请的内存区大小对应的页框数
phys_addr_tphys_addr; //该字段一般为0,除非内存已经被申请用作映射一个硬件设备的I/O共享内存
const void *caller; //当前调用vmalloc类的函数的返回地址
};
/*
内核中用get_vm_area函数来创建一个新的非连续区结构,在该函数的实现中又会调用kmallloc函数和kfree函数
分别为vm_struct结构分配和释放所需的内存。
vmalloc给内核分配一个非连续的内存区,其原型为:
void *vmalloc(unsigned longsize)
函数首先把size参数取为页面的大小(即4KB)的倍数,然后进行有效性检查,若有大小适合的可用内存,就调用
get_vm_area()获得一个内存区的结构,最后会调用vmalloc_area_pages()进行真正的的非连续内存的分配,该函数
实际上建立了非连续内存到物理页面的映射。
*/(7)内存管理——管理区(zone)
管理区的类型
//这里只举出图中出现的类型
enum zone_type {
//内存首部16MB,即低端范围的物理内存,某些工业标准体系结构(ISA)设备需要用到ZONE_DMA;
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
//标记了使用32位地址字可寻址, 适合DMA的内存域。
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
//16MB~896MB,该部分的内存由内核直接映射到线性地址空间的较高部分;
//许多内核操作只有通过ZONE_NORMAL才能完成,因此ZONE_NORMAL是影响系统性能最为重要的管理区。
ZONE_NORMAL,
//896MB~末尾,将保留给系统使用,是系统中预留的可用内存空间,不能被内核直接映射。
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
};管理区描述符struct zone
//struct zone结构体在<linux/mmzone.h>中定义
struct zone {
//各种级别的水线需要保留的内存页面数量,在页面分配器和kswapd页面回收中会用到。
unsigned long watermark[NR_WMARK];
//保留的页框池。linux为了尽量减少内存分配失败的情况发生,内核为原子内存分配请求保留了一个页框池,该页框池只有在内存不足的时候才使用。ZONE_DMA和ZONE_NORMAL内存管理区将一定数量的页框贡献给保留内存,这个数目与两个管理区的相对大小成比例。
long lowmem_reserve[MAX_NR_ZONES];
//该管理区的父节点。
struct pglist_data *zone_pgdat;
//如果用于slab的页达到这个值就缓存收缩。
unsigned long min_slab_pages;
//zone 中被伙伴系统管理的页面数量。
unsigned long managed_pages;
//对应于伙伴系统中MIGRATE_RESEVE链的页块的数量
int nr_migrate_reserve_block;
//...
//空闲区域位图,由伙伴分配器使用。(下面进行介绍)
struct free_area free_area[MAX_ORDER];zone和页面之间的映射
- 系统在初始化管理区(zone)后,紧接着就会建立和初始化zone相关的page。
- free_area_init_core()向每个zone填充相关信息的过程中调用memmap_init()建立和初始化page,并设置所有page的PG_reserved位。
- memmap_init()通过memmap_init_zone()建立和初始化某个zone中的page
/*
* 将zone中的页框PG_reserved置位。表示该页不可用。
* 同时初始化页框中其他值。
*/
void __meminit memmap_init_zone(unsigned long size, int nid, unsigned long zone,
unsigned long start_pfn, enum memmap_context context)
for (pfn = start_pfn; pfn < end_pfn; pfn++) {
if (context == MEMMAP_EARLY) {
if (!early_pfn_valid(pfn))
continue;
if (!early_pfn_in_nid(pfn, nid))
continue;
if (!update_defer_init(pgdat, pfn, end_pfn,&nr_initialised))
break; }
if (!(pfn & (pageblock_nr_pages - 1))) {
//创建page
struct page *page = pfn_to_page(pfn);
//初始化page
__init_single_page(page, pfn, zone, nid);
set_pageblock_migratetype(page, MIGRATE_MOVABLE);
}
else {
__init_single_pfn(pfn, zone, nid);
}
//在一个循环中建立和初始化了该zone地址范围内的所有page,函数pfn_to_page()用于创建page, //__init_single_page()用于初始化page
//页面和zone映射的api
static inline struct zone *page_zone(const struct page *page){
return &NODE_DATA(page_to_nid(page))->node_zones[page_zonenum(page)];
}
static inline void set_page_zone(struct page *page, enum zone_type zone){
page->flags &= ~(ZONES_MASK << ZONES_PGSHIFT);
page->flags |= (zone & ZONES_MASK) << ZONES_PGSHIFT;
}
{(8)伙伴系统
1.伙伴关系
- 由一个母实体分成的两个各方面属性一致的两个子实体,这两个子实体就处于伙伴关系。在操作系统分配内存的过程中,一个内存块常常被分成两个大小相等的内存块,这两个大小相等的内存块就处于伙伴关系。它满足 3 个条件 :
- 两个块具有相同大小记为 2^K
- 它们的物理地址是连续的
- 从同一个大块中拆分出来
2.伙伴系统相关的结构体
//zone中定义的
struct free_area free_area[MAX_ORDER];
//用于管理该zone的伙伴系统信息。伙伴系统将基于这些信息管理该zone的物理内存。该数组中每个数组项用于管理一个空闲内存页块链表,同一个链表中的内存页块的大小相同,并且大小为2的数组下标次方页。MAX_ORDER定义了支持的最大的内存页块大小。
//free_area结构体的详解
struct free_area {
structlist_head free_list[MIGRATE_TYPES];
unsignedlong nr_free;
};
//nr_free:其中nr_free表示内存页块的数目,对于0阶的表示以1页为单位计算,对于1阶的以2页为单位计算,n阶的以2的n次方为单位计算。
//free_list:用于将具有该大小的内存页块连接起来。由于内存页块表示的是连续的物理页,因而对于加入到链表中的每个内存页块来说,只需要将内存页块中的第一个页加入该链表即可。因此这些链表连接的是每个内存页块中第一个内存页,使用了struct page中的struct list_head成员lru。free_list数组元素的每一个对应一种属性的类型,可用于不同的目地,但是它们的大小和组织方式相同。
3.系统伙伴系统当前的信息可以通过下列命令查看
cat /proc/buddyinfo
(9)slab分配器
-
实现目的:
- Linux内核中基于伙伴算法实现的分区页框分配器适合大块内存的请求,它所分配的内存区是以页框为基本单位的。对于内核中小块连续内存的请求,比 如说几个字节或者几百个字节,如果依然分配一个页框来来满足该请求,那么这很明显就是一种浪费,即产生内部碎片。
- 为了解决小块内存的分配,Linux内核基于Solaris 2.4中的slab分配算法实现了自己的slab分配器。除此之外,slab分配器另一个主要功能是作为一个高速缓存,它用来存储内核中那些经常分配并释放的对象。
-
基本原理
- slab分配器中用到了对象这个概念,所谓对象就是内核中的数据结构以及对该数据结构进行创建和撤销的操作。它的基本思想是将内核中经常使用的对象 放到高速缓存中,并且由系统保持为初始的可利用状态。比如进程描述符,内核中会频繁对此数据进行申请和释放。
- 当一个新进程创建时,内核会直接从slab分 配器的高速缓存中获取一个已经初始化了的对象;
- 当进程结束时,该结构所占的页框并不被释放,而是重新返回slab分配器中。
-
分配器的结构

slab分配器为每种对象分配一个高速缓存,这个缓存可以看做是同类型对象的一种储备。每个高速缓存所占的内存区又被划分多个slab,每个 slab是由一个或多个连续的页框组成。每个页框中包含若干个对象,既有已经分配的对象,也包含空闲的对象。
//每个高速缓存通过kmem_cache结构来描述,这个结构中包含了对当前高速缓存各种属性信息的描述。
//所有的高速缓存通过双链表组织在一起,形成 高速缓存链表cache_chain。
//每个kmem_cache结构中并不包含对具体slab的描述,而是通过kmem_list3结构组织各个 slab。
struct kmem_list3 {
//该结构将当前缓存中的所有slab分为三个集合:空闲对象的slab链表slabs_free,非空闲对象的slab链表 slabs_full以及部分空闲对象的slab链表slabs_partial。
struct list_head slabs_partial;
struct list_head slabs_full;
struct list_head slabs_free;
unsigned long free_objects;
unsigned int free_limit;
unsigned int colour_next;
spinlock_t list_lock;
struct array_cache *shared;
struct array_cache **alien;
unsigned long next_reap;
int free_touched;
}
//slab描述符
//每个slab有相应的slab描述符
struct slab {
struct list_head list;
unsigned long colouroff;
void *s_mem;
unsigned int inuse;
kmem_bufctl_t free;
unsigned short nodeid;
}2.参考图2解释内核层不同内存分配接口的区别,包括__get_free_pages,kmalloc,vmalloc等

(1)分配的位置
- kmalloc:分配的内存为内核区的ZONE_NORMOL区,该区的大小在3G+16-896区间内,大小有限不适合开辟太大的空间
- vmalloc:分配的是ZONE_HIGHMEM高端内存区也就是非连续内存区。
- malloc:分配的是用户空间的堆区数据
(2)分配是否连续
- kmalloc保证分配的内存在物理上是连续的,虚拟地址自然也是连续的
- vmalloc保证的是在虚拟地址空间上的连续,物理空间不一定连续,它通过分配非连续的物理内存块,在修正页表,把内存映射到逻辑地址空间的连续区域中
(3)分配的大小
- kmalloc能分配的大小有限,vmalloc和malloc能分配的大小相对较大
(4)
- kmalloc和get_free_page申请的内存位于物理内存映射区域,而且在物理上也是连续的,它们与真实的物理地址只有一个固定的偏移,因此存在较简单的转换关系,virt_to_phys()可以实现内核虚拟地址转化为物理地址
- vmalloc申请的内存则位于vmalloc_start~vmalloc_end之间,与物理地址没有简单的转换关系,虽然在逻辑上它们也是连续的,但是在物理上它们不要求连续。















 446
446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









