







 LRSpeech是一个针对低资源语言的语音识别和合成系统,它利用迁移学习、对偶变换和知识蒸馏技术。在多资源语言上预训练后在低资源语言上微调,通过TTS和ASR之间的相互提升提高准确性。知识蒸馏用于定制高质量目标说话人的TTS模型,并改进多说话人ASR模型。实验表明,LRSpeech在TTS的可懂度和自然度以及ASR的识别准确度上都达到了工业标准。
LRSpeech是一个针对低资源语言的语音识别和合成系统,它利用迁移学习、对偶变换和知识蒸馏技术。在多资源语言上预训练后在低资源语言上微调,通过TTS和ASR之间的相互提升提高准确性。知识蒸馏用于定制高质量目标说话人的TTS模型,并改进多说话人ASR模型。实验表明,LRSpeech在TTS的可懂度和自然度以及ASR的识别准确度上都达到了工业标准。

摘要
语音合成和语音识别通常需要大量数量的文本和语音对数据来训练模型。然而在世界上还有超过6000种语言缺少语音训练数据,在低资源的语言上建立语音合成和语音识别系统依然是很有挑战的。 在这篇文章中, 我们提出了LRSpeech, 一个在低资源下的语音识别和语音合成系统,能够支持少量数据的不常见的语言。 LRSpeech 由三个关键技术组成:(1) 在多资源的语种上进行预训练,然后在低资源的数据上进行微调(2)TTS和ASR之间的对偶转换能够提高彼此的准确率;(3)用知识蒸馏的方法,根据高质量的目标说话人的声音来定制TTS模型,并在多说话人上改善ASR模型。我们在多资源语言(英语)和极低资源的语言(立陶宛语)来验证LRSpeech的效果。实验结果表明: (1)TTS在可懂度,自然度方面都达到工业发展的要求;(2)ASR达到可信的识别准确度;
简介
数据:

- 在多资源的条件下, TTS和ASR都需要大量的语音文本对数据来达到较高的准确率。 TTS通常需要大量单说话人的高质量录音, 而ASR需要至少上百小时的多说话人的低质量数据。 此外,在丰富的资源环境下,TTS还利用语音词典来实现准确的发音。可选地,可以利用未配对的语音和文本数据。
- 在低资源的条件下,TTS任务中单说话人高质量对数据被缩减到分钟级【2,12,23,31】, ASR任务中低质量对数据被缩减到小时级【16,32,33,39】。此外,他们还使用未配对的语音和文本对来保证效果
- 在无监督的条件下, ASR模型只使用未配对的文本和语音对数据
简介
LRSpeech的目标是在两个约束下依然能够达到工业标注:(1) 极低资源【表1】(2)高准确率。对于第一个限制, LRSpeech探究了数据需求的局限性通过以下几个实验:
- 尽可能少地使用高质量成对的单人数据(several minutes)
- 使用低质量成对的多人数据(several hours)
- 使用低质量的不成对的多人数据(dozens of hours)
- 不使用高质量未配对的单人数据
- 不使用语音词典, 直接将字符作为TTS和ASR的输入和输出
对于第二个限制, LRSpeech使用了几个关键技术: 迁移学习, 对偶变换提高TTS和ASR的准确度,知识蒸馏。 总的来说,LRSpeech包含三个阶段:
- 首先在多资源语言上对TTS和ASR模型进行预训练, 模型能够学习到语音和文本之间的对其关系,这样有助于低资源语音上对齐任务的学习。
- 在 未配对的语音和文本上使用对偶变换
- 此外,我们利用未配对的语音和文本数据进行知识蒸馏,在高质量的目标说话人语音上定制TTS模型,并对多语音上的ASR模型进行改进。
LRSpeech
pipeline
为了保障在极低资源下TTS和ASR模型的准确率,我们设计了三个阶段的pipeline,如下图所示:
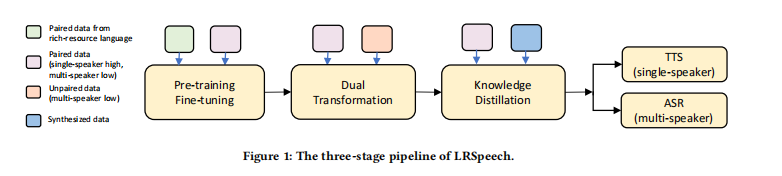
- 预训练和微调: 我们首先在多资源的语言上对TTS和ASR进行预训练, 然后在低资源的语言上进行微调。 使用多资源的语言在LRSpeech主要是基于两个考虑: 1)大量成对的多资源语言数据是可获取的 2)在多资源语言上的对齐有助于低资源语言上的对齐,人类语言之间的发音具有相似性。
- 对偶变换(Dual transformation): 利用TTS和ASR两个任务之间的对偶性
- 知识蒸馏: 为了进一步提升TTS和ASR的准确率,使用了知识蒸馏的方法来合成。
Denotation
D : paired text and speech corpus;
(
x
,
y
)
∈
D
(x,y) \in D
(x,y)∈D;
x: a phoneme or character
y: a frame of speech
TTS loss [mean square error loss]:
L
(
θ
;
D
)
=
−
∑
(
x
,
y
)
∈
D
(
y
−
f
(
x
;
θ
)
)
2
L(\theta; D) = - \sum _{(x,y)\in D}(y-f(x;\theta))^2
L(θ;D)=−(x,y)∈D∑(y−f(x;θ))2
ASR loss [negative log likelihood loss]:
L
(
θ
;
D
)
=
∑
(
x
,
y
)
∈
D
l
o
g
P
(
x
∣
y
;
σ
)
L(\theta; D) = \sum _{(x,y)\in D} logP(x|y;\sigma)
L(θ;D)=(x,y)∈D∑logP(x∣y;σ)
D
r
i
c
h
t
t
s
D_{rich_tts}
Drichtts: high-quality TTS paired data in rich-resource language
D
r
i
c
h
a
s
r
D_{rich_asr}
Drichasr: low-quality TTS paired data in rich-resource language
D
h
D_h
Dh: single-speaker high-quality paired data for target spealer
D
l
D_l
Dl: multi-speaker low-quality paired data
X
u
X^{u}
Xu:unpaired text data
Y
u
Y^{u}
Yu:multi-speaker low-quality unpaired speech data
Pre-training and Fine-Tuning
文本和语音之间的转换最重要的是学习到字符表示和声学特征之间的对齐关系。 不同国家的人们说这不同的语言,但是有着相同的发音器官,因此学习一种语言的对齐关系有利于学习另一种语言的对齐关系。因此我们将在多资源语言上的TTS和ASR模型迁移到低资源的语言上。
Pre-training: 用语料
D
r
i
c
h
_
t
t
s
D_{rich\_tts}
Drich_tts预训练TTS模型
θ
\theta
θ, 用KaTeX parse error: Undefined control sequence: \asr at position 8: D_{rich\̲a̲s̲r̲}训练ASR模型
ϕ
\phi
ϕ
Fine-tuning: 考虑到多资源和低资源语言有着不同的音素/字符 和说话人, 我们用低资源语言来初始化TTS 和ASR模型的参数(除了phoneme/character embedding和speaker embedding)。之后使用 D h 和 D l D_h 和D_l Dh和Dl来微调TTS和ASR模型。 在微调的过程中, 我们首先对character embedding 和 speaker embedding进行微调, 然后再对其他的参数进行微调。 这可以避免TTS和ASR模型在有限的低资源数据上过拟合。
Dual Transformation between TTS and ASR
TTS和ASR是两个对偶的任务, 由于这两个任务的对偶性,可以提升彼此之间的准确度,尤其是在低资源任务上。 因此我们使用了对偶变换(dual transfomation)[不知道这里有没有翻译错误]来提高文本到语音的转换能力。 对偶变换的工作流程如下:
- 对每个unpaired 的 text sequence x ∈ X u x \in X^{u} x∈Xu, 首先使用TTS模型将其转换为音频, 然后构建一个伪语料库 D ( X u ) D(X^u) D(Xu) 来训练ASR模型
- 对每条unpaired 音频序列 y ∈ Y u y \in Y^u y∈Yu, 首先使用ASR模型将其转换为对应的文本序列, 然后构建一个伪语料库 D ( Y u ) D(Y^u) D(Yu)来训练TTS模型
在训练过程中,动态运行双重转换过程,即每次迭代都会更新伪语料库,并且模型可以从彼此生成的最新数据中获益。接下来,介绍一些具体的双转换设计,以支持多说话人TTS和ASR。
Multi-speaker TTS synthesis:随机选择一个说话人, 给定文本, 合成该说话人对应的语音,这有利于多说话人ASR模型的训练。同样, ASR模型将多说话人的语音转换为文本,能够有助于多说话人TTS模型的训练。
Levering unpaired Speech of Unseen Speakers : 因为多说话人低质量的且没有对应文本的语音数据比高质量单说话人的数据更容易获得, 因此使得TTS和ASR模型能够利用未见过的说话人在对偶变换中, 使得我们的系统能够更加稳定并且更可扩展。在TTS中,合成未见过说话人的声音比ASR更难, 因此将对偶变换分成两个部分: 1) 第一步, 只使用在训练数据中出现的说话人的纯音频; 2) 第二步, 将训练集中未出现的说话人数据加入到训练数据中, 当ASR模型能够识别未见过的说话人时, 伪语料集就能用于训练TTS模型, 并合成未见过的说话人的声音。
Customization on TTS and ASR through Knowledge Distillation
使用对偶变换的TTS和ASR模型还未达到上线的标准, 主要还存在以下几个问题: 1) 尽管TTS模型能够支持多说话人, 但是目标说话人的音频质量还不够好;2)合成的语音还存在漏字和重复的现象; 3) ASR模型的识别准确率还需要进一步提升。 因此我们利用了知识蒸馏的方法, 来构建伪语料集, 使得定制的TTS和ASR模型由更高的准确率。
knowledge Distillation for TTS
- 对于每一条文本 x ∈ X u x \in X^u x∈Xu, 用对偶变换的TTS模型合成相应目标说话人的音频, 构建一个单说话人的伪语料集 D ( X u ) D(X^u) D(Xu)
- 过滤掉有漏字 重复的音频
- 使用过滤后的伪语料集 D ( X u ) D(X^u) D(Xu)来训练一个目标说话人的新的TTS模型
knowledge Distillation for ASR:
- 对于每一条音频 y ∈ Y u y \in Y^u y∈Yu, 使用ASR生成对应的文本, 构建一个伪语料集 D ( Y u ) D(Y^u) D(Yu)
- 对于每个文本 x ∈ X u x\in X^u x∈Xu, 合成相应的多说话人的音频, 构建伪语料集 D ( X u ) D(X^u) D(Xu)
- 结合 D ( X u ) 和 D ( Y u ) , D h , D l D(X^u)和D(Y^u), D_h, D_l D(Xu)和D(Yu),Dh,Dl来训练一个新的ASR模型。
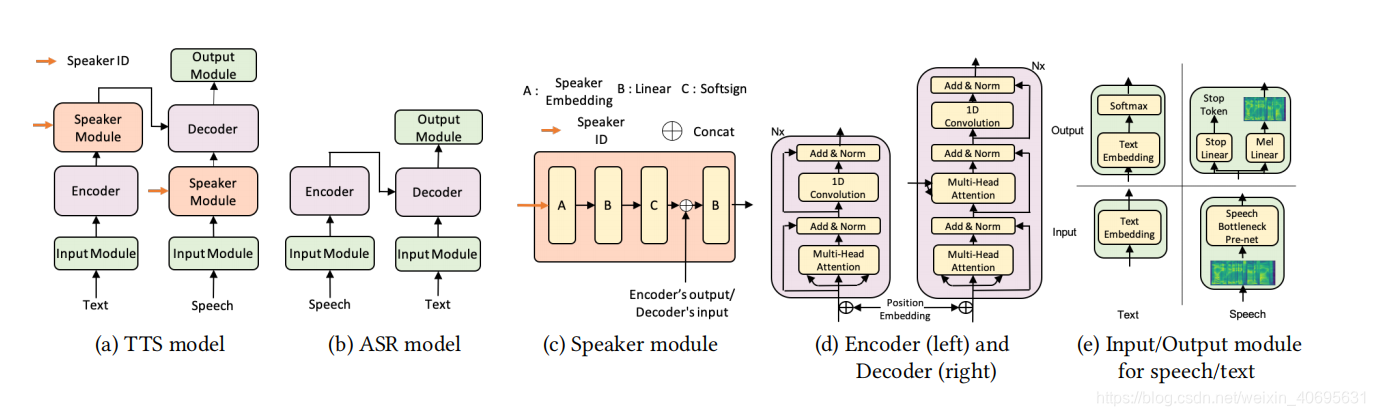
Model Structure of LRSpeech
Experiments
experiments setup
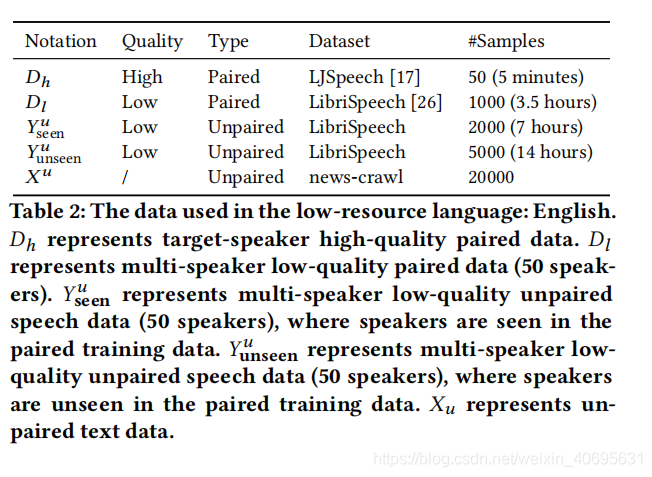
数据集:
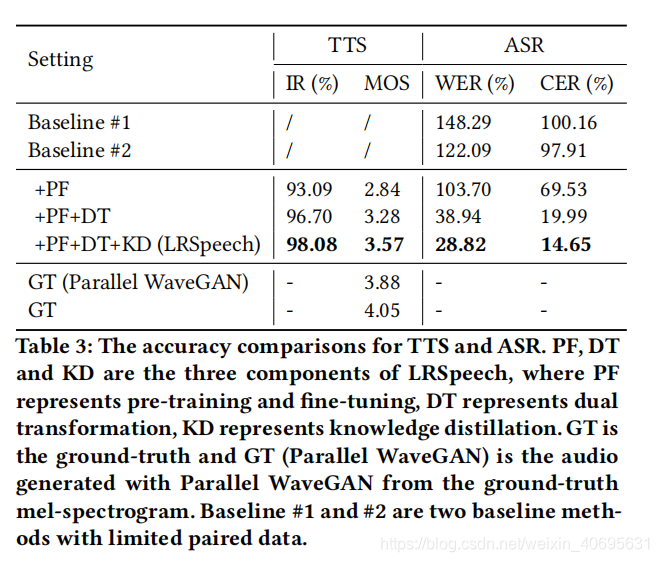
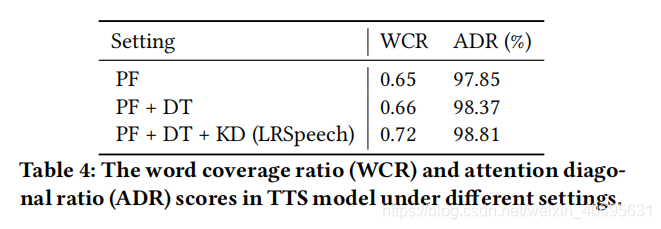
result

【2】Alexei Baevski, Michael Auli, and Abdelrahman Mohamed. 2019. Effectiveness of self-supervised pre-training for speech recognition. arXiv preprint arXiv:1911.03912 (2019).
【6】William Chan, Navdeep Jaitly, Quoc Le, and Oriol Vinyals. 2016. Listen, attend
and spell: A neural network for large vocabulary conversational speech recognition. In Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Conference on. IEEE, 4960–4964.
【8】Yi-Chen Chen, Chia-Hao Shen, Sung-Feng Huang, and Hung-yi Lee. 2018. Towards Unsupervised Automatic Speech Recognition Trained by Unaligned Speech and Text only. arXiv preprint arXiv:1803.10952 (2018)
【10】Chung-Cheng Chiu, Tara N Sainath, Yonghui Wu, Rohit Prabhavalkar, Patrick
Nguyen, Zhifeng Chen, Anjuli Kannan, Ron J Weiss, Kanishka Rao, Ekaterina Gonina, et al. 2018. State-of-the-art speech recognition with sequence-to-sequence models. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 4774–4778.
【11】Jan Chorowski, Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2014.
End-to-end continuous speech recognition using attention-based recurrent nn: First results. In NIPS 2014 Workshop on Deep Learning, December 2014.
【12】Yu-An Chung, Yuxuan Wang, Wei-Ning Hsu, Yu Zhang, and RJ Skerry-Ryan. 2019.
Semi-supervised training for improving data efficiency in end-to-end speech synthesis. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 6940–6944.
【22】Naihan Li, Shujie Liu, Yanqing Liu, Sheng Zhao, Ming Liu, and M Zhou. 2019.Neural Speech Synthesis with Transformer Network. AAAI.
【23】Alexander H Liu, Tao Tu, Hung-yi Lee, and Lin-shan Lee. 2019. Towards Unsupervised Speech Recognition and Synthesis with Quantized Speech Representation Learning. arXiv preprint arXiv:1910.12729 (2019).
【24】Da-Rong Liu, Kuan-Yu Chen, Hung-yi Lee, and Lin-shan Lee. 2018. Completely
Unsupervised Phoneme Recognition by Adversarially Learning Mapping Relationships from Audio Embeddings. Proc. Interspeech 2018 (2018), 3748–3752.
【28】Wei Ping, Kainan Peng, Andrew Gibiansky, Sercan O. Arik, Ajay Kannan, Sharan
Narang, Jonathan Raiman, and John Miller. 2018. Deep Voice 3: 2000-Speaker Neural Text-to-Speech. In International Conference on Learning Representations.
【30】 Yi Ren, Yangjun Ruan, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, and Tie-Yan
Liu. 2019. Fastspeech: Fast, robust and controllable text to speech. In Advances in Neural Information Processing Systems. 3165–3174.
【31】Yi Ren, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, and Tie-Yan Liu. 2019. Almost
Unsupervised Text to Speech and Automatic Speech Recognition. In International Conference on Machine Learning. 5410–5419.
【32】Andrew Rosenberg, Yu Zhang, Bhuvana Ramabhadran, Ye Jia, Pedro Moreno,
Yonghui Wu, and Zelin Wu. 2019. Speech Recognition with Augmented Synthesized Speech. arXiv preprint arXiv:1909.11699 (2019).
【33】Steffen Schneider, Alexei Baevski, Ronan Collobert, and Michael Auli. 2019.
wav2vec: Unsupervised Pre-Training for Speech Recognition. Proc. Interspeech
2019 (2019), 3465–3469.
【39】Andros Tjandra, Sakriani Sakti, and Satoshi Nakamura. 2017. Listening while
speaking: Speech chain by deep learning. In Automatic Speech Recognition and Understanding Workshop (ASRU), 2017 IEEE. IEEE, 301–308.
【45】Chih-Kuan Yeh, Jianshu Chen, Chengzhu Yu, and Dong Yu. 2019. Unsupervised
Speech Recognition via Segmental Empirical Output Distribution Matching. ICLR
(2019).

















 439
439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









