







Low Resource也是对话摘要任务中的一个研究重点,因为对话摘要的数据集相对偏少,最多也只有一万条数据,而且现实生活中也难以为长对话标注对应的摘要。这里记录两篇low resource对话摘要方面的论文
AdaptSum: Towards Low-Resource Domain Adaptation for Abstractive Summarization
论文链接:
https://arxiv.org/abs/2103.11332
主要动机与想法:
生成式摘要模型依赖于大规模的摘要数据,需要大量的人工标注,很多领域并没有这样的数据。一种方法就是领用领域适应技术,利用新闻等大规模的摘要数据集来辅助特定领域的摘要任务。预训练的语言模型取得 了巨大的成功,进行第二次预训练是领域适应任务的一个有效方法,但之前很少有工作把二次预训练应用到文本生成任务上来。这篇文章通过进行第二次预训练来进行领域适应,完成低资源领域的摘要生成任务。
这篇文章设计了三种二次预训练的设计,第一种是source domain pretraining(SDPT),在有标签的源领域数据集上预训练,第二种是domain adaptive pre-training(DAPT)在大规模的无标签的领域相关的语料上预训练第三种是task-adaptive pre-training(TAPT),在小规模的无标签的任务相关数据集上预训练。
这篇文章主要关注六个低资源领域,Dialog(对话),Email(邮件),Movie Review(电影评论),Debate(辩论),Social Media(社交媒体),Science(科学),这篇文章收集了这六个领域的数据集,以及相应领域的无标签数据集,用来进行第二次预训练。
方法
采用二阶段预训练方法,根据三种不同的设置,使用数据集对预训练的BART模型进行第二次预训练,然后再在目标领域的有标签数据集上进行微调。这里详细介绍一下这三种二次预训练的设置:
第一种是源领域数据预训练(SDPT),使用新闻数据(xsum)作为源领域,利用新闻领域大量的有标签数据进行二次预训练。二次预训练时目标函数与BART的原始预训练任务(句子重构)不同,而是利用新闻领域有标签的摘要数据来监督,这种预训练可以引入任务(摘要任务)相关的知识,帮助模型快速的适应到相同的任务上去。
第二种是领域相关数据预训练(DAPT),使用无监督的大规模的领域相关的数据集来继续对预训练的BART模型进行预训练,目标函数和原始BART相同。这种预训练可以引入领域知识。
第三种是任务相关预训练(TAPT),在目标领域的摘要任务上的一部分无监督数据上进行预训练,这部分数据比较少,但是直接是任务相关(摘要任务),目标函数和DAPT一样,直接用BART原始的目标函数
二阶段预训练可能会造成灾难性遗忘问题,可以通过引入持续学习的方法来解决,这里用RecAdam,目标函数公式如下:
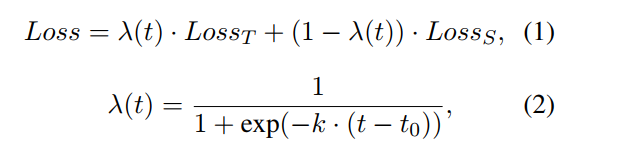
L
o
s
s
t
Loss_t
Losst代表目标任务目标函数,
L
o
s
s
s
Loss_s
Losss模拟了第一阶段预训练,
L
o
s
s
s
Loss_s
Losss公式如下

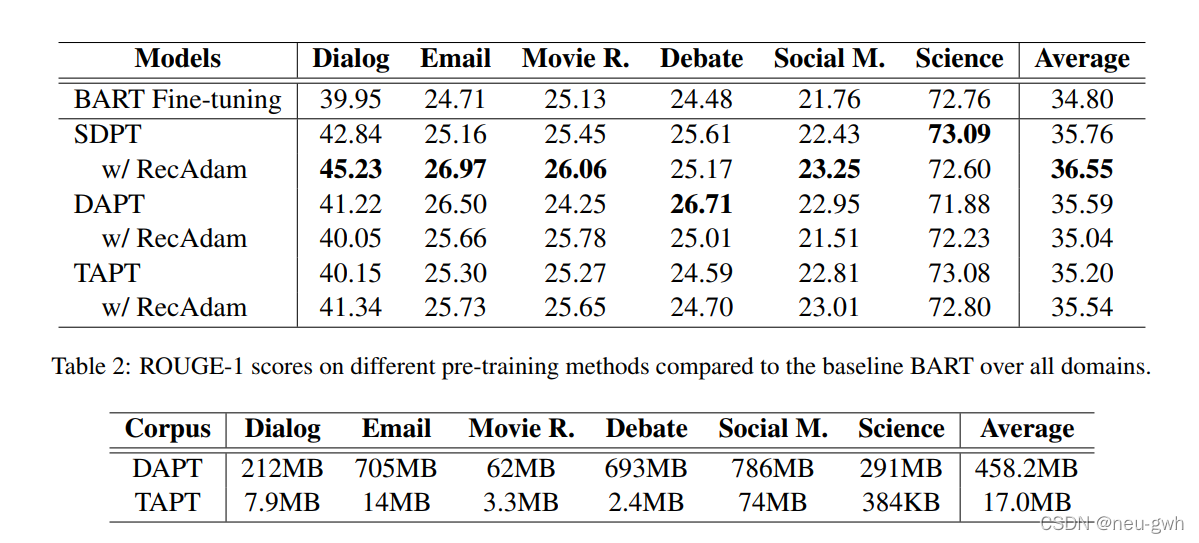
实验结果:
代码链接
https://github.com/TysonYu/AdaptSum
Low-Resource Dialogue Summarization with Domain-Agnostic Multi-Source Pretraining
论文链接:
https://arxiv.org/abs/2109.04080
代码链接:
https://github.com/RowitZou/DAMS
主要动机与想法
之前的低资源的对话摘要的工作大多是直接利用其他领域(新闻)的数据进行预训练,但是这么做忽略了对话数据和传统文本(新闻,论文)等的巨大差异,这篇文章利用大规模的领域内的无监督数据分别训练编码器和解码器,再在有摘要标签的领域外数据上训练整个seq2seq模型。
方法
这篇文章把整个序列到序列的预训练模型的训练分为三部分,编码器训练,解码器训练,整个序列模型的训练。具体来说,在大规模的无标注的无监督的对话数据上训练编码器,来学习对话建模和理解的方式,在大规模的summary-like短文本上训练摘要解码器,这些短文本都是日常闲聊风格的,这样就可以学习一个对话摘要生成风格的语言模型。最后,把编码器和解码器组合在一起,在外部的摘要数据集上预训练来完成总体的摘要生成。这里还设计了对抗性准则,来进行领域不可知的摘要,消减不同领域数据间的巨大差异。
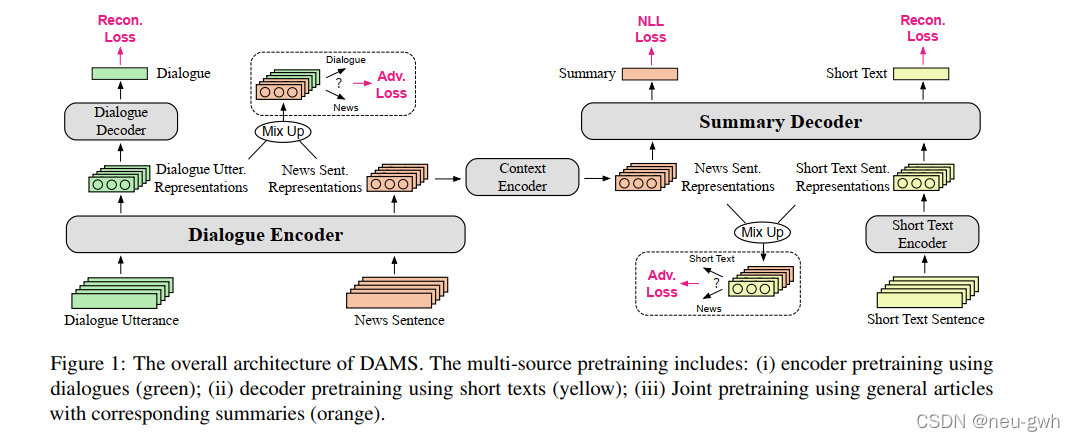
总体架构如上图所示,下面对各部分进行详细介绍:
Pretraining of dialogue modeling
用去噪编码器(DAE)的方式来训练编码器,从而有效提取出对话的特征。用transformer作为DAE的编码器和解码器,将所有的utterance分词,随机mask掉每个utterance中一定比例的token,然后让DAE重构出原来的utterance
,具体的公式如下:
首先在每个加入噪声的序列前加CLS,经过编码器编码
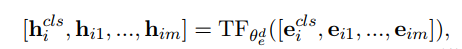
再通过解码器预测:

使用重构损失函数:
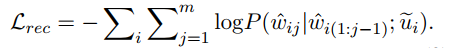
Pretraining of summary language modeling
解码器的训练方式类似,这里用BooksCorpus 数据集作为外部语料来训练解码器生成对话摘要风格的文本。还是和编码器一样引入噪声,用Transformer进行一次编码,因为解码器需要顺序的生成所有句子,所以预训练解码器时多引入一个Transformer,来混合上下文的信息,公式如下:
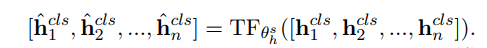
训练解码器利用上面得到的表示,恢复原来的文本
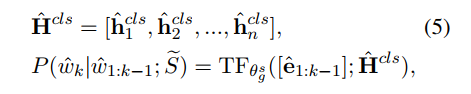
损失函数如下:
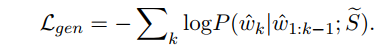
Pretraining of abstractive summarization
用领域外数据集(新闻摘要)来训练生成式摘要任务模型,重用上面预训练的对话编码器
T
F
θ
e
d
\mathrm{TF}_{\theta_{e}^{d}}
TFθed和摘要解码器
T
F
θ
g
s
\mathrm{TF}_{\theta_{g}^{s}}
TFθgs,这里在中间了添加了一个context encoder(见上面的架构图,也是Transformer)作为过渡,和训练解码器时的
T
F
θ
h
s
\mathrm{TF}_{\theta_{h}^{s}}
TFθhs公式一样。
损失函数如下所示,
D
S
D_S
DS代表输入文档

通过将编码器和解码器整合在一起训练完成生成式摘要任务,可以帮助整个模型学习如何捕获关键信息并生成摘要。
Domain-Agnostic Summarization with Adversarial Learning
模型可能会学习到一些领域的特定特征,使得模型难以泛化到新的领域,这篇文章设计了一个对抗(adversial)准则,设计判别器区分不同领域的特征,利用gradient reversal 机制使得不同领域的特征分布尽可能的接近,使判别器难以区分,这样就可以产生领域无关的特征分布,使得模型只关注于内容而不是领域的特定特征。
这里添加了两个对抗性准则,一个是
L
e
D
\mathcal{L}_{e}^{D}
LeD,另一个是
L
g
D
\mathcal{L}_{g}^{D}
LgD在编码器输出那里,分类输出向量是新闻还是对话句子,另一个在解码器输出那里,区分新闻和短文本,总体损失函数如下,
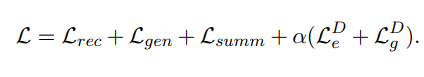
Finetuning
通过以上步骤完成了多来源的预训练,然后再把预训练得到的对话编码器,上下文编码器(context encoder),摘要解码器组合在一起,在具体的对话摘要任务数据集上微调
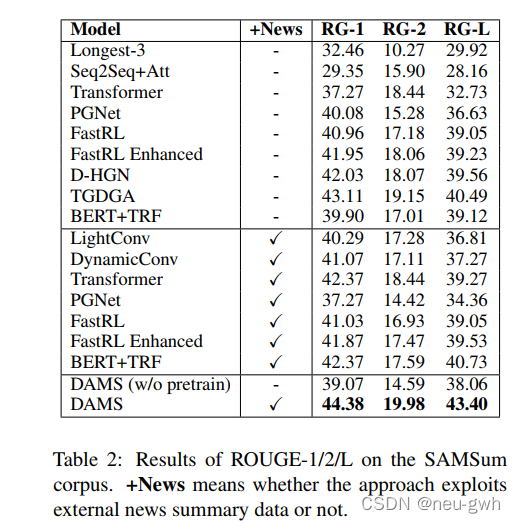
实验结果:














 196
196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









