






华为云田奇团队联合上海交大提出最强视觉编码器 | COMM: CLIP + DINOv2的完美融合
本文重点讨论了多模态大语言模型中的视觉编码器的效果。通过深入分析,作者强调了浅层特征的重要性,这些特征捕捉了有助于 grounding 和定位任务的低级细节。
链接:https://arxiv.org/pdf/2310.08825.pdf
代码:https://github.com/YuchenLiu98/COMM
本文重点讨论了多模态大语言模型(Multi-modal Large Language Models,MLLMs)中的视觉编码器的效果。现有的方法通常使用 CLIP 或其变体作为视觉分支,仅从深层中提取特征。然而,这些方法缺乏对MLLMs 中视觉编码器的全面分析。
作者进行了广泛的研究,发现 CLIP 的浅层特征在细粒度任务(如 grounding 和区域理解)方面具有特殊优势。令人惊讶的是,仅仅为视觉模型 DINO 配备一个 MLP 层,它就在 MLLMs 内部作为视觉分支表现出令人满意的性能。
基于这些观察,作者提出了一种名为 COMM 的简单而有效的特征融合策略,它通过多层次特征融合来增强 MLLMs 的视觉能力。通过在各种基准测试中对 COMM 进行的综合实验,包括图像字幕生成、视觉问题回答、视觉 grounding 和物体幻觉等结果表明,与现有方法相比,COMM 表现出卓越的性能,突显了其在 MLLMs 内部增强的视觉能力。
本小节简单介绍下大语言模型(LLMs)的重要性和多模态扩展的动机。
LLMs 在语言理解和生成领域取得了显著进展,通过指令调整能够处理各种任务。研究人员现在希望通过将视觉信号作为输入来扩展它们的能力,以生成与视觉内容密切相关的文本输出,从而在视觉-语言理解和生成领域开辟了令人兴奋的可能性。
为了实现这一目标,一系列方法如大家所熟悉的 Flamingo 和 BLIP2 通过将 LLMs 与冻结的视觉编码器对齐,以理解视觉输入并执行各种视觉-语言任务。然而,这些方法主要基于图像级别的对齐,存在局部细粒度理解和严重幻觉问题。为此,诸如 GPT4ROI、Kosmos-2 和 Shikra 进一步被提出以增强LLMs的视觉能力,相信各位小伙伴最近已被 GPT4V 刷屏了。
然而,大多数现有多模态LLMs仍然使用 CLIP 或其变体作为视觉分支,但缺乏对这一选择的全面分析。作者强调了 MLLMs 中的视觉编码器和语言编码器之间的不平衡性,以及视觉模型的不足之处,如上下文学习、跨域问题以及有限的零样本能力。

因此,本文的目标是对 MLLMs 中的不同视觉编码器进行全面调查,并提出一种多层次特征融合策略(COMM)来增强其视觉能力。作者的研究发现,不同层次的特征对局部和全局模式有不同的偏见,浅层特征对于细粒度任务有益,而深层特征对全局理解更有优势(符合常理~~~skr)。最令人惊讶的部分,DINOv2 作为仅带有 MLP 层的视觉模型在 MLLMs 中表现出良好的性能,这可能归因于 DINOv2 捕获的细粒度定位信息。因此,本文最终选择了 CLIP+DINO 的组合。
大语言模型的视觉骨干分析
这一小节我们简要分析 MLLMs 中不同视觉编码器的影响。
CLIP
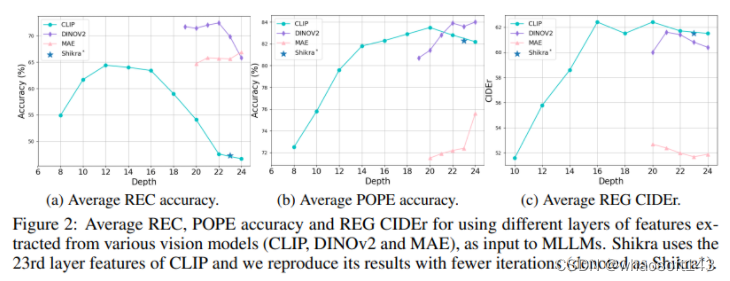
关于CLIP,作者观察到不同层次的特征对 grounding 和理解能力有不同的偏见。如上图所示,浅层特征在 REF 和理解能力方面表现出相对较高的准确性,而深层特征在理解能力方面表现出更高的准确性。因此,与以前的方法不同,作者认为将浅层和深层特征进行整合对于提高MLLMs的整体性能至关重要。通过平均整合浅层和深层特征,以及采用LLN-Layerscale策略,CLIP在通用的视觉-语言任务上实现了显著的性能提升。
DINOv2
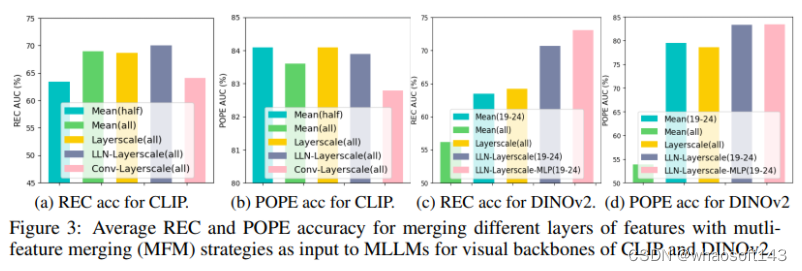
DINOv2 具有丰富的细粒度视觉信息,但与文本不天然对齐,因此作者使用非线性的多层感知器(MLP)模块来将图像特征与词嵌入空间对齐。作者观察到DINOv2的深层特征在 grounding 能力方面表现出优势,而多层特征融合(Multi-Level Feature Merging,MFM)通过LLN-Layerscale-MLP模块实现的更强连接对性能提升起到了明显作用,在各种视觉-语言任务中取得了显著的性能提升。
MAE & DeiT
MAE 特征在 REF 准确性上表现可接受,但在 POPE 和 REG 评估中性能下降明显,因为MAE特征缺乏足够的语义信息以进行全局或区域理解。DeiT的性能甚至不如MAE,猜测可能是因为受到监督训练的影响太大,学到了难以与词嵌入空间对齐的专门的视觉空间。
方法
通过上述的动机分析,我们知道 COMM 是一种整合了 CLIP 和 DINOv2,并采用多层特征融合策略的增强 MLLMs 视觉能力的方法,下面小编简要介绍下。
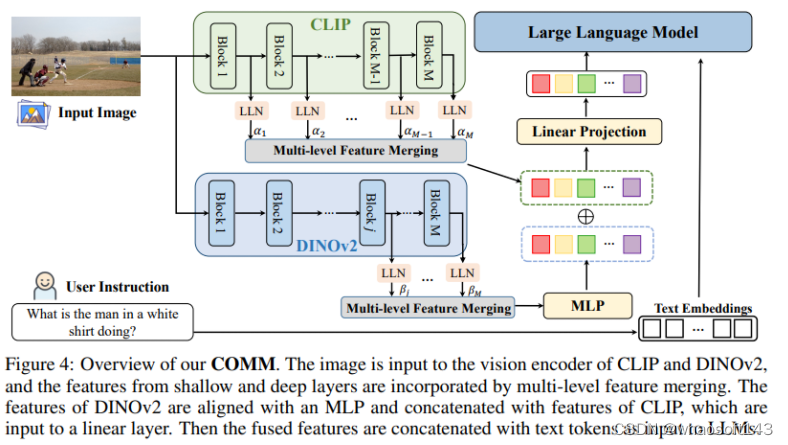
架构概述
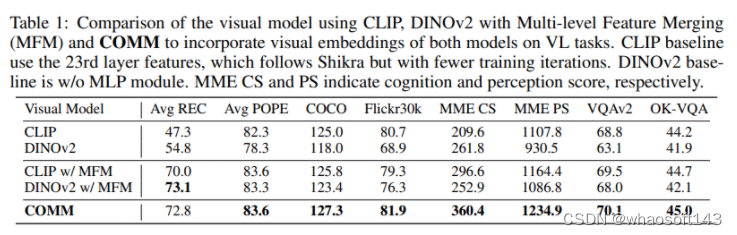
COMM 方法被引入到一个基于最新的语言和视觉-语言基础模型构建的视觉-语言指令遵循模型中。这个模型根据输入的指令,将视觉和语言作为输入,生成遵循输入指令的文本响应。具体而言,本文采用 CLIP 和 DINOv2(基于ViT-Large)的视觉编码器以及 Vicuna 作为语言解码器。视觉编码器通过下采样将图像表示为序列,然后将融合后的标记特征通过线性层进行投影,并与指令标记一起作为输入传递给语言解码器。这个解码器是一个通用接口,统一了各种视觉-语言任务,将其视为文本生成任务。
融合策略
在 COMM 中,视觉编码器由 CLIP 和 DINOv2 组成。给定一个输入图像 ,从 CLIP 和 DINOv2 中提取特征。CLIP 提取了所有层的补丁标记特征,而 DINOv2 提取了深层的特征。这两个模型提取的特征被连接在一起,通过线性层进行投影,并通过线性层归一化模块(Linear-layernorm)来对齐不同层次的特征空间。然后,多层特征融合策略(Layerscale)用于将多个层次的特征进行融合,其中 α 和 β 是可学习的缩放参数。接下来,采用 MLP 层来处理 DINOv2 的特征,并将其与 CLIP 的特征连接在一起。最后,通过线性层将融合后的视觉特征的维度匹配到文本特征的维度,融合后的视觉特征与文本标记一起作为 LLMs 的输入。
总的来说,COMM 的目标是将 CLIP 和 DINOv2 的视觉信息融合,以提高 MLLMs 在各种视觉-语言任务中的性能。这种融合策略允许利用 CLIP 的全局视觉信息和 DINOv2 的细粒度定位信息,从而实现更强大的视觉能力。
实验
实现细节
COMM 的训练分为两个阶段:
- 第一预训练阶段:在这个阶段,模型在重新组织的视觉-语言数据集上进行预训练,包括公共的视觉问答(VQA)、图像字幕数据集以及一些包含位置注释的数据集,如RefCOCO、visual gemone和Visual-7W。这个阶段的预训练进行了100,000个步骤。
- 第二指令调整阶段:在第二阶段,采用LLaVA-Instruct-150K和Shikra-RD数据集,设置采样比例为50%。与现有MLLMs目前使用的224×224分辨率不同,作者采用336×336的分辨率,以减少由图像下采样引起的信息丢失,并提升细粒度感知能力。
- 冻结和调整参数:在两个阶段中,视觉编码器被冻结,所有参数在LLMs、对齐层和多层特征融合模块中都被调整。作者采用AdamW作为优化器,余弦退火调度器作为学习率调度器,初始学习率为2e-5,全局批次大小为64。
- 训练硬件:所有训练在8块NVIDIA A800 GPU上进行。第一阶段的训练大约需要100小时,第二阶段的训练大约需要20小时。
实际效果

总结
本研究对于多模态大语言模型(MLLMs)中不同视觉模型的有效性进行了全面探究。通过深入分析,作者强调了浅层特征的重要性,这些特征捕捉了有助于 grounding 和定位任务的低级细节。此外,文中发现了仅包含图像信息的 DINOv2 模型的潜力,它利用细粒度的像素级信息,当与 MLP 层进行对齐时,可以增强 MLLMs 在细粒度感知方面的表现。受到这些分析结果的启发,作者最后引入了一种融合策略,将 CLIP 和 DINOv2 获取的视觉特征相结合,从而进一步增强了 MLLMs 的视觉能力和性能。















 1806
1806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









