







一、常见的聚类分析算法
- K-Means: K-均值聚类也称为快速聚类法,在最小化误差函数的基础上将数据划分为预定的类数K。该算法原理简单并便于处理大量数据。
- K-中心点:K-均值算法对孤立点的敏感性,K-中心点算法不采用簇中对象的平均值作为簇中心,而选用簇中离平均值最近的对象作为簇中心。
- 系统聚类:也称为层次聚类,分类的单位由高到低呈树形结构,且所处的位置越低,其所包含的对象就越少,但这些对象间的共同特征越多。该聚类方法只适合在小数据量的时候使用,数据量大的时候速度会非常慢。
二、K-Means 算法原理
-
初始化常数k, 随机初始化 k 个聚类中心;
-
重复计算以下过程, 直到聚类中心不再改变;
-计算每个样本与每个聚类中心之间的相似度, 将样本划分到最相似的类别中;
-计算划分到每个类别中的所用样本特征的均值, 并将该均值作为每个类新的聚类中心。 -
输出最终的聚类中心以及每个样本所属的类别。
以下图解过程:
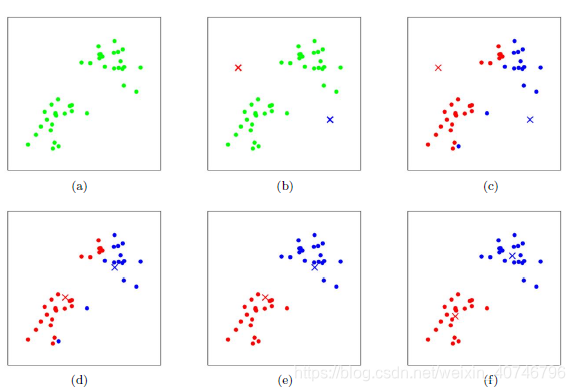
上图a表达了初始的数据集,假设k=2。在图b中,我们随机选择了两个k类所对应的类别质心,即图中的红色质心和蓝色质心,然后分别求样本中所有点到这两个质心的距离,并标记每个样本的类别为和该样本距离最小的质心的类别,如图c所示,经过计算样本和红色质心和蓝色质心的距离,我们得到了所有样本点的第一轮迭代后的类别。此时我们对我们当前标记为红色和蓝色的点分别求其新的质心,如图4所示,新的红色质心和蓝色质心的位置已经发生了变动。(将染色的点计算它们的平均值(平均下来的位置)此时将相应的聚类中心移动到这个均值处。)图e和图f重复了我们在图c和图d的过程,即将所有点的类别标记为距离最近的质心的类别并求新的质心。最终我们得到的两个类别如图f。当然在实际K-Mean算法中,我们一般会多次运行图c和图d,才能达到最终的比较优的类别。
三、K-Means 算法的实践
# -*- coding: utf-8 -*-
import numpy as np
def load_data(file_path):
'''导入数据
input: file_path(string):文件的存储位置
output: data(mat):数据
'''
f = open(file_path)
data = []
for line in f.readlines():
row = [] # 记录每一行
lines = line.strip().split("\t")
for x in lines:
row.append(float(x)) # 将文本中的特征转换成浮点数
data.append(row)
f.close()
return np.mat(data)
def distance(vecA, vecB):
'''计算vecA与vecB之间的欧式距离的平方
input: vecA(mat)A点坐标
vecB(mat)B点坐标
output: dist[0, 0](float)A点与B点距离的平方
'''
dist = (vecA - vecB) * (vecA - vecB).T
return dist[0, 0]
def randCent(data, k):
'''随机初始化聚类中心
input: data(mat):训练数据
k(int):类别个数
output: centroids(mat):聚类中心
'''
n = np.shape(data)[1] # 属性的个数
centroids = np.mat(np.zeros((k, n))) # 初始化k个聚类中心
for j in range(n): # 初始化聚类中心每一维的坐标
minJ = np.min(data[:, j])
rangeJ = np.max(data[:, j]) - minJ
# 在最大值和最小值之间随机初始化
centroids[:, j] = minJ * np.mat(np.ones((k , 1))) \
+ np.random.rand(k, 1) * rangeJ
#计算随机值的公式:c=min+rand(0,1)*(max-min)
return centroids
def kmeans(data, k, centroids):
'''根据KMeans算法求解聚类中心
input: data(mat):训练数据
k(int):类别个数
centroids(mat):随机初始化的聚类中心
output: centroids(mat):训练完成的聚类中心
subCenter(mat):每一个样本所属的类别
'''
m, n = np.shape(data) # m:样本的个数,n:特征的维度
subCenter = np.mat(np.zeros((m, 2))) # 初始化每一个样本所属的类别
change = True # 判断是否需要重新计算聚类中心
while change == True:
change = False # 重置
for i in range(m):
minDist = np.inf # 设置样本与聚类中心之间的最小的距离,初始值为正无穷
minIndex = 0 # 所属的类别
for j in range(k):
# 计算i和每个聚类中心之间的距离
dist = distance(data[i, ], centroids[j, ])
if dist < minDist:
minDist = dist
minIndex = j
# 判断是否需要改变
if subCenter[i, 0] < minIndex: # 需要改变
change = True
subCenter[i, ] = np.mat([minIndex, minDist])
# 重新计算聚类中心
for j in range(k):
sum_all = np.mat(np.zeros((1, n)))
r = 0 # 每个类别中的样本的个数
for i in range(m):
if subCenter[i, 0] == j: # 计算第j个类别
sum_all += data[i, ]
r += 1
for z in range(n):
try:
centroids[j, z] = sum_all[0, z] / r
except:
print (" r is zero")
return subCenter
def save_result(file_name, source):
'''保存source中的结果到file_name文件中
input: file_name(string):文件名
source(mat):需要保存的数据
output:
'''
m, n = np.shape(source)
f = open(file_name, "w")
for i in range(m):
tmp = []
for j in range(n):
tmp.append(str(source[i, j]))
f.write("\t".join(tmp) + "\n")
f.close()
if __name__ == "__main__":
k = 4 # 聚类中心的个数
file_path = "D:/anaconda4.3/spyder_work/data4.txt"
# 1、导入数据
print ("---------- 1.load data ------------")
data = load_data(file_path)
# 2、随机初始化k个聚类中心
print ("---------- 2.random center ------------")
centroids = randCent(data, k)
# 3、聚类计算
print ("---------- 3.kmeans ------------")
subCenter = kmeans(data, k, centroids)
# 4、保存所属的类别文件
print ("---------- 4.save subCenter ------------")
save_result("sub", subCenter)
# 5、保存聚类中心
print ("---------- 5.save centroids ------------")
save_result("center", centroids)
四、使用python 显示聚类结果
from sklearn.cluster import KMeans
import numpy
import matplotlib.pyplot as plt
print('---------- 1.load data ------------')
#读取数据并存储到dataSet中
dataSet = []
fileIn = open('D:/anaconda4.3/spyder_work/data4.txt')
for line in fileIn.readlines():
lineArr = line.strip().split()
dataSet.append('%0.6f' % float(lineArr[0]))
dataSet.append('%0.6f' % float(lineArr[1]))
print('---------- 2.clustering ------------')
#调用sklearn.cluster中的KMeans类
dataSet = numpy.array(dataSet).reshape(80,2)
kmeans = KMeans(n_clusters=4, random_state=0).fit(dataSet)
#求出聚类中心
center=kmeans.cluster_centers_
center_x=[]
center_y=[]
for i in range(len(center)):
center_x.append('%0.6f' % center[i][0])
center_y.append('%0.6f' % center[i][1])
#标注每个点的聚类结果
labels=kmeans.labels_
type1_x = []
type1_y = []
type2_x = []
type2_y = []
type3_x = []
type3_y = []
type4_x = []
type4_y = []
for i in range(len(labels)):
if labels[i] == 0:
type1_x.append(dataSet[i][0])
type1_y.append(dataSet[i][1])
if labels[i] == 1:
type2_x.append(dataSet[i][0])
type2_y.append(dataSet[i][1])
if labels[i] == 2:
type3_x.append(dataSet[i][0])
type3_y.append(dataSet[i][1])
if labels[i] == 3:
type4_x.append(dataSet[i][0])
type4_y.append(dataSet[i][1])
#画出四类数据点及聚类中心
plt.figure(figsize=(10,8), dpi=80,facecolor='gray')
axes = plt.subplot(111)
type1 = axes.scatter(type1_x, type1_y, s=30, c='red')
type2 = axes.scatter(type2_x, type2_y, s=30, c='green')
type3 = axes.scatter(type3_x, type3_y,s=30, c='pink' )
type4 = axes.scatter(type4_x, type4_y, s=30, c='yellow')
type_center = axes.scatter(center_x, center_y, s=40, c='blue',marker='*')
plt.xlabel('x')
plt.ylabel('y')
plt.title("KMeans")
axes.legend((type1, type2, type3, type4,type_center), ('0','1','2','3','center'),loc=2)
plt.show()
五、K-Means++算法的基本思想
K-Means++算法在聚类中心的初始化过程中的基本原则是使得初始的聚类中心之间的相互距离尽可能远,K-Means++算法的初始化过程如下:
- 在数据集随机选择一个样本点作为第一个初始化的聚类中心;
- 选择出其余的聚类中心:
计算样本中的每一个样本点与已经初始化的聚类中心之间的距离,并选择其最短的距离,记为 d i d_{i} di ;
以概率选择距离最大的样本作为新的聚类中心,重复上述过程,直到 k 个聚类中心都被确定。 - 对 k 个初始化的聚类中心,利用K-Means算法计算最终的聚类中心。
六、详解scikit-learn中的KMeans聚类实现
来看看主函数KMeans:
sklearn.cluster.KMeans(n_clusters=8,
init='k-means++',
n_init=10,
max_iter=300,
tol=0.0001,
precompute_distances='auto',
verbose=0,
random_state=None,
copy_x=True,
n_jobs=1,
algorithm='auto')
- 参数的意义:
- n_clusters:簇的个数,即你想聚成几类
- init: 初始簇中心的获取方法
- n_init: 获取初始簇中心的更迭次数,为了弥补初始质心的影响,算法默认会初始10次质心,实现算法,然后返回最好的结果。
- max_iter: 最大迭代次数(因为kmeans算法的实现需要迭代)
- tol: 容忍度,即kmeans运行准则收敛的条件
- precompute_distances:是否需要提前计算距离,这个参数会在空间和时间之间做权衡,如果是True会把整个距离矩阵都放到内存中,auto 会默认在数据样本大于featurs*samples 的数量大于 12 e 6 12e^{6} 12e6的时候False,False 时核心实现的方法是利用Cpython 来实现的
- verbose: 冗长模式(不太懂是啥意思,反正一般不去改默认值)
- random_state: 随机生成簇中心的状态条件。
- copy_x: 对是否修改数据的一个标记,如果True,即复制了就不会修改数据。bool 在scikit-learn很多接口中都会有这个参数的,就是是否对输入数据继续copy 操作,以便不修改用户的输入数据。这个要理解Python的内存机制才会比较清楚。
- n_jobs: 并行设置
- algorithm: kmeans的实现算法,有:‘auto’, ‘full’, ‘elkan’, 其中 'full’表示用EM方式实现
虽然有很多参数,但是都已经给出了默认值。所以我们一般不需要去传入这些参数,参数的。可以根据实际需要来调用。
KMeans分析的一些类如何调取与意义:
import numpy as np
from sklearn.cluster import KMeans
data = np.random.rand(100, 3) #生成一个随机数据,样本大小为100, 特征数为3
#假如我要构造一个聚类数为3的聚类器
estimator = KMeans(n_clusters=3)#构造聚类器
estimator.fit(data)#聚类
label_pred = estimator.labels_ #获取聚类标签
centroids = estimator.cluster_centers_ #获取聚类中心
inertia = estimator.inertia_ # 获取聚类准则的总和,用来评估簇的个数是否合适,距离越小说明簇分的越好
estimator初始化Kmeans聚类;estimator.fit聚类内容拟合;
estimator.label_聚类标签,这是一种方式,还有一种是predict;estimator.cluster_centers_聚类中心均值向量矩阵
estimator.inertia_代表聚类中心均值向量的总和
from sklearn.cluster import KMeans
num_clusters = 3
km_cluster = KMeans(n_clusters=num_clusters, max_iter=300, n_init=40, \
init='k-means++',n_jobs=-1)
#返回各自文本的所被分配到的类索引
result = km_cluster.fit_predict(tfidf_matrix)
print("Predicting result: ", result)
km_cluster是KMeans初始化,其中用init的初始值选择算法用’k-means++’;
km_cluster.fit_predict相当于两个动作的合并:km_cluster.fit(data)+km_cluster.predict(data),可以一次性得到聚类预测之后的标签,免去了中间过程。
- n_clusters: 指定K的值
- max_iter: 对于单次初始值计算的最大迭代次数
- n_init: 重新选择初始值的次数
- init: 制定初始值选择的算法
- n_jobs: 进程个数,为-1的时候是指默认跑满CPU
- 注意,这个对于单个初始值的计算始终只会使用单进程计算,
- 并行计算只是针对与不同初始值的计算。比如n_init=10,n_jobs=40,
- 服务器上面有20个CPU可以开40个进程,最终只会开10个进程
其中:
km_cluster.labels_
km_cluster.predict(data)
这是两种聚类结果标签输出的方式,结果都一样。都需要先km_cluster.fit(data),然后再调用。














 7663
7663











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









