






去年圣诞节前后,OpenAI 开启了 “撒钱” 模式。
我当时第一时间发现并分享了这一消息。
其实并不是真正意义的 “撒钱”,OpenAI 该项目的学名应该是 数据共享计划。讲人话,用数据换 token。
你只需要开启 “数据共享”,每天就能免费获得总计 1100 万的 tokens,其中包括 100 万 tokens 的 gpt-4o 和 o1 模型 API,以及 1000 万 tokens 的 gpt-4o-mini 和 o1-mini 模型 API。注意,是每天。
当时的活动说明长这样。
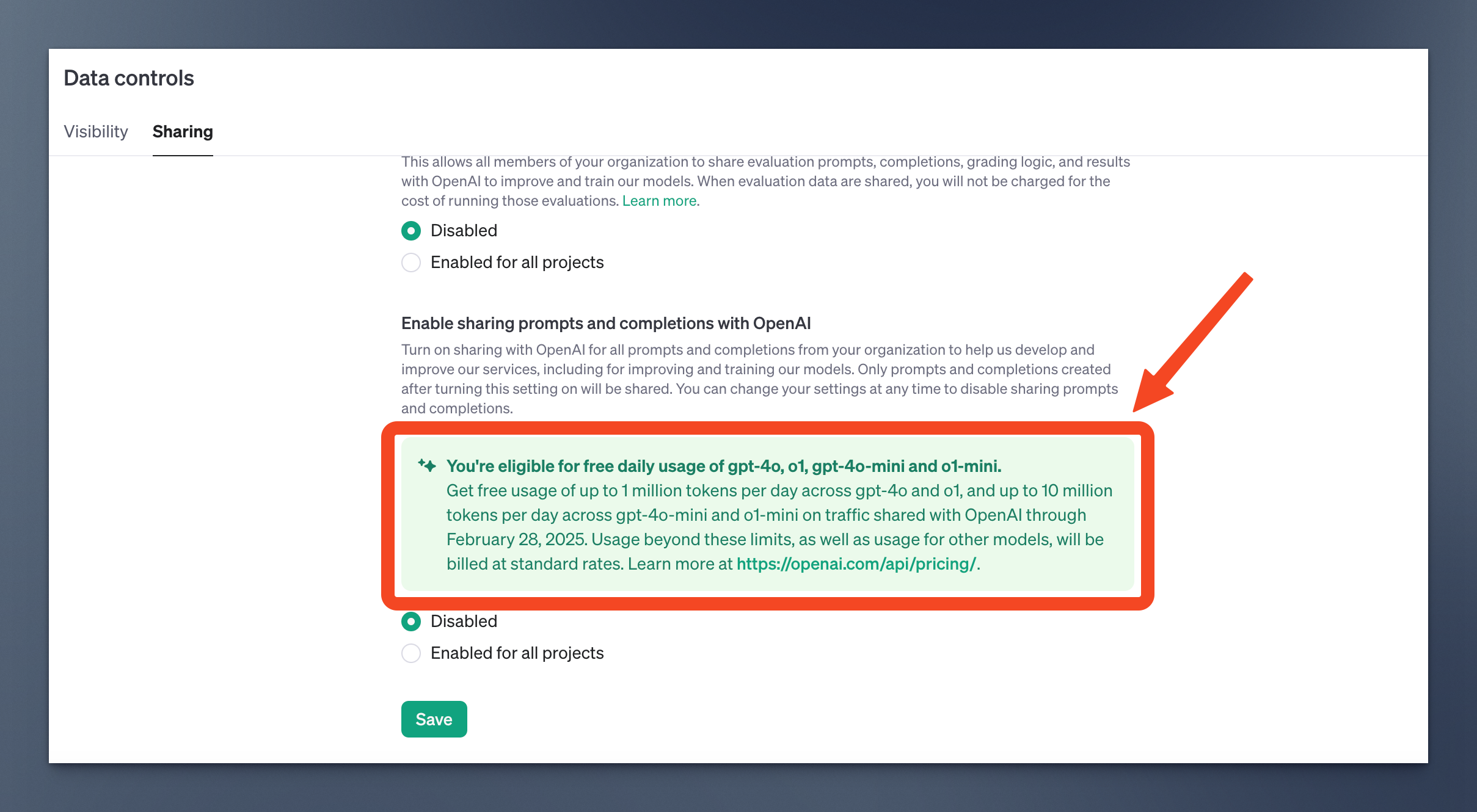
可以清楚地看到,OpenAI 最初设定的 数据共享计划 于 2025 年 2 月 28 日截止。
然而,故事并没有就此结束。
某天我突然收到了来自 OpenAI 官方的一封邮件。

邮件里,OpenAI 表示这个 1100 万 tokens 的 数据共享计划 本应在 2 月 28 日结束,但 后又决定延长这个活动的期限至 2025 年 4 月 30 日。
所以,狂欢继续。
这还不是最关键的。最关键的是,在最新的 数据共享计划 活动说明中,明确标出了参加活动的模型,其中包括 OpenAI 最新,也是最后一个 “非思考” 模型 GPT-4.5;以及最新的推理模型 o3-mini。
最新的活动说明是这样描述的。
Get free usage of up to 1 million tokens per day across gpt-4.5-preview, gpt-4o and o1, and up to 10 million tokens per day across gpt-4o-mini, o1-mini and o3-mini on traffic shared with OpenAI through April 30, 2025. Usage beyond these limits, as well as usage for other models, will be billed at standard rates.

翻译一下,和之前相比,最新的 数据共享计划 在每天 100 万高级模型 tokens 中增加了 gpt-4.5-preview,在每天 1000 万标准模型 tokens 中增加了 o3-mini。
如果是之前,这个 数据共享计划 可以说是有用,但用处也不是很大。但现在,绝对推荐。
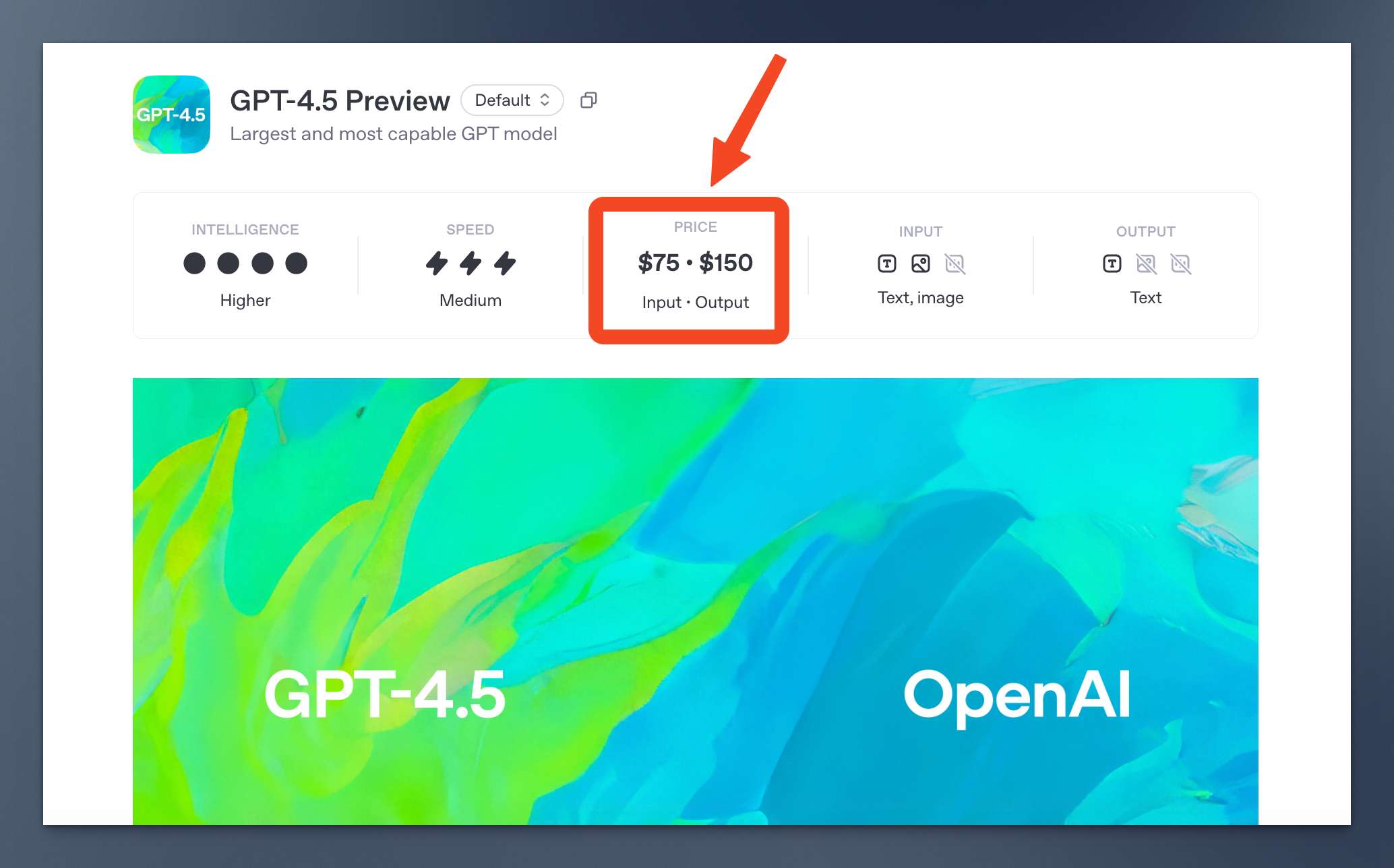
因为 gpt-4.5-preview API 本身非常贵:每百万输入 tokens 75 美元,每百万输出 tokens 150 美元。
意味着单 gpt-4.5-preview 这一项,你每天就能从 OpenAI 薅到价值 150 美元的羊毛。
值得注意的是,OpenAI 的这个 数据共享计划 并不是面向所有开发者的,据观察需要 OpenAI 的开发者账号等级在 Tier 3 及以上。
想查看自己有没有参与资格也很简单,登录 OpenAI 开放平台(platform.openai.com),按照下面的步骤操作即可。
如果你能在 设置 -> Data controls 数据管理 -> Sharing 共享 -> Enable 开启 处看到下面截图里的绿色说明文字,那说明你是 OpenAI 的 “天选之子”。
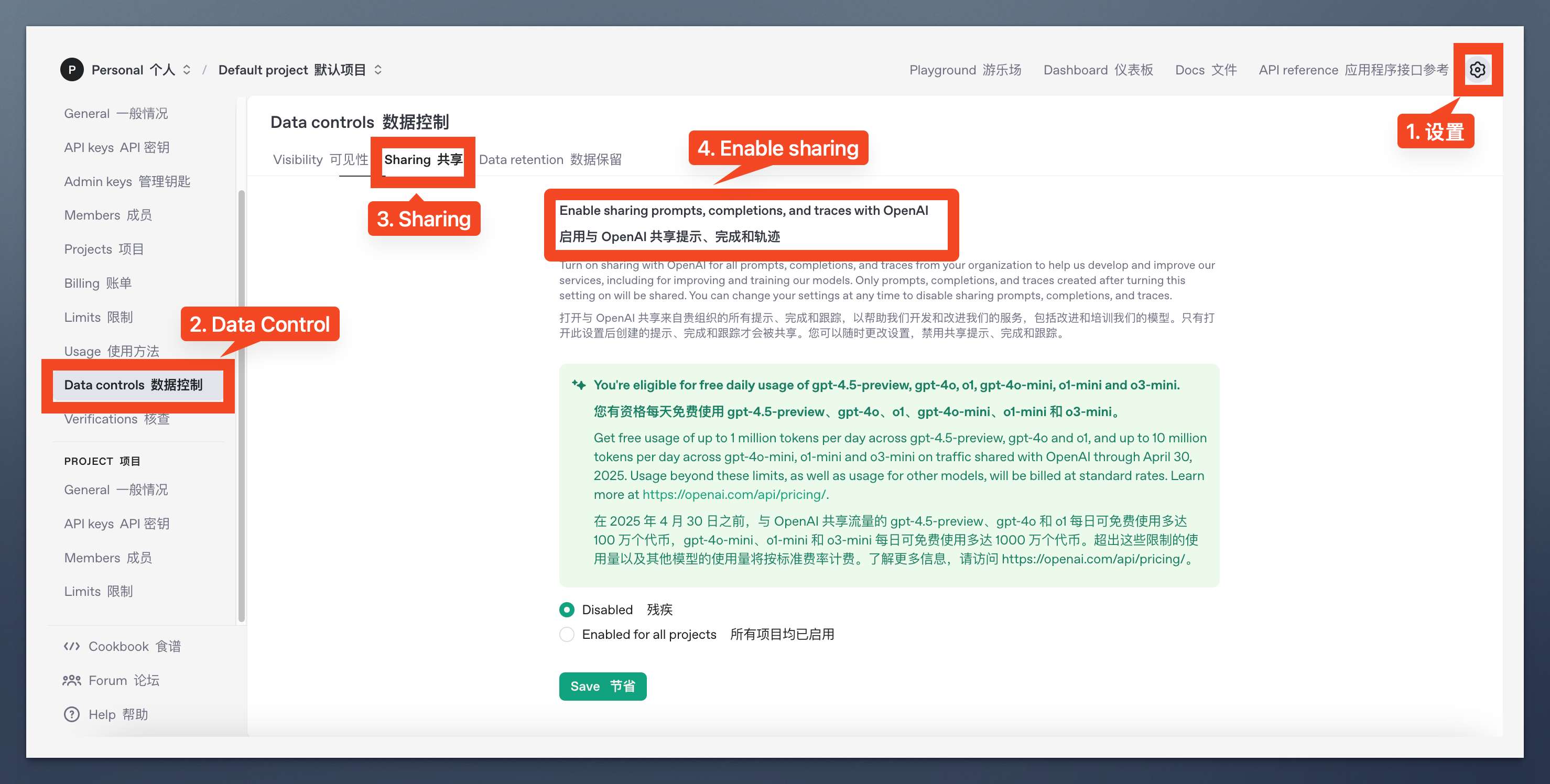
选择 Enabled for all projects,点击 Save。
在弹出的确认弹窗里,点击 同意,然后 确认。

至此,开通成功。可以开启每天免费 1100 万 tokens 的愉快之旅了!
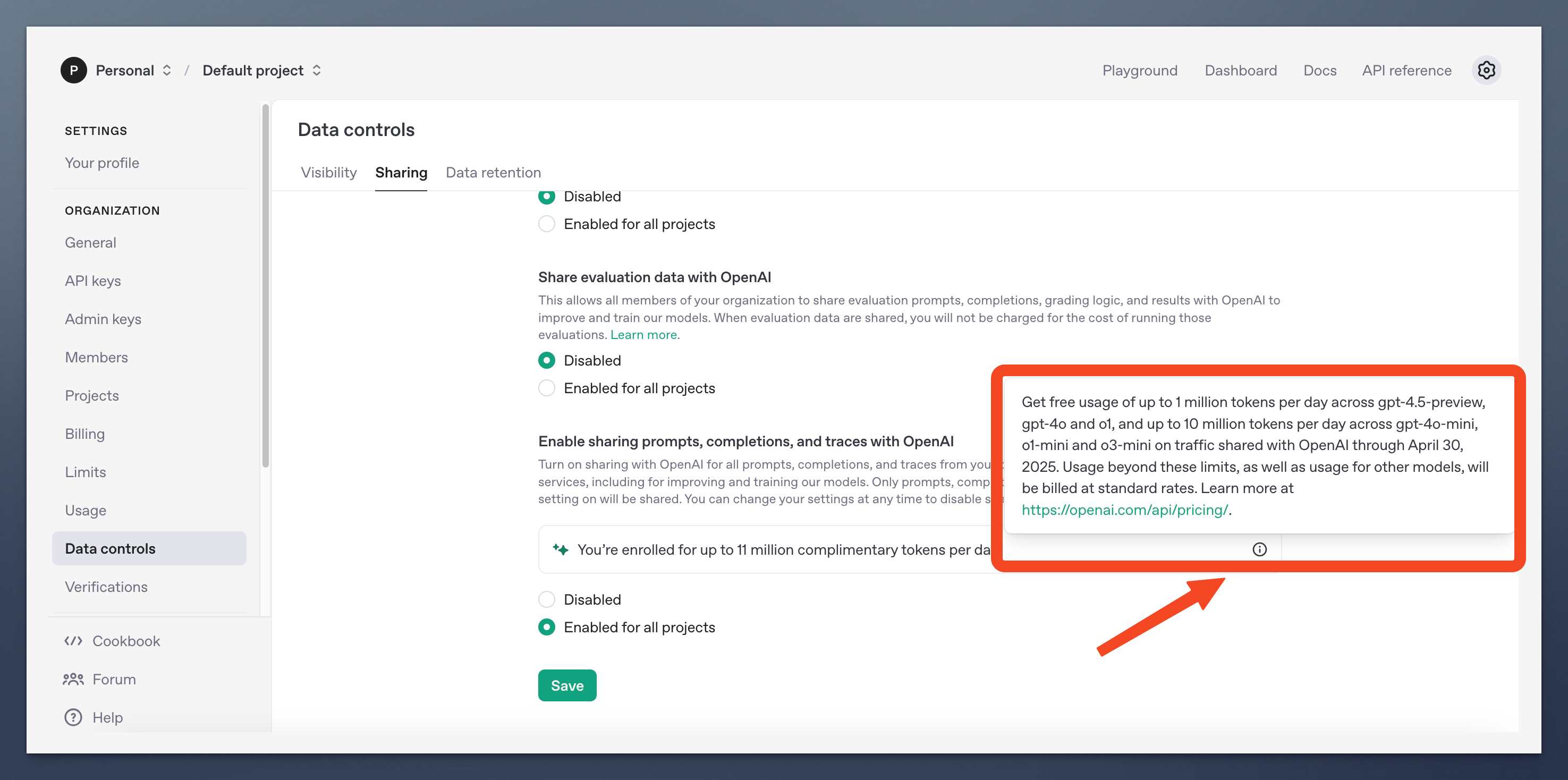
可以直接在 OpenAI 开放平台里的 “Playground” 测试、使用各个模型。也可以通过 API 调用在第三方客户端里使用 API,比如 Cherry Studio、Chatbox、和 沉浸式翻译。
亲测,你使用的 tokens 会自动计入每天的免费额度里,不会扣你自己的余额。
OpenAI 不是第一家推出 数据共享计划 的 AI 厂商。
早在去年年中,谷歌就面向所有用户免费推出了 AI Studio,所有模型,完全免费,几乎无限使用。
今年年初,马斯克旗下的 xAI 也推出了类似的 数据共享计划,为开发者每月免费提供价值 150 美元的模型 API 余额。
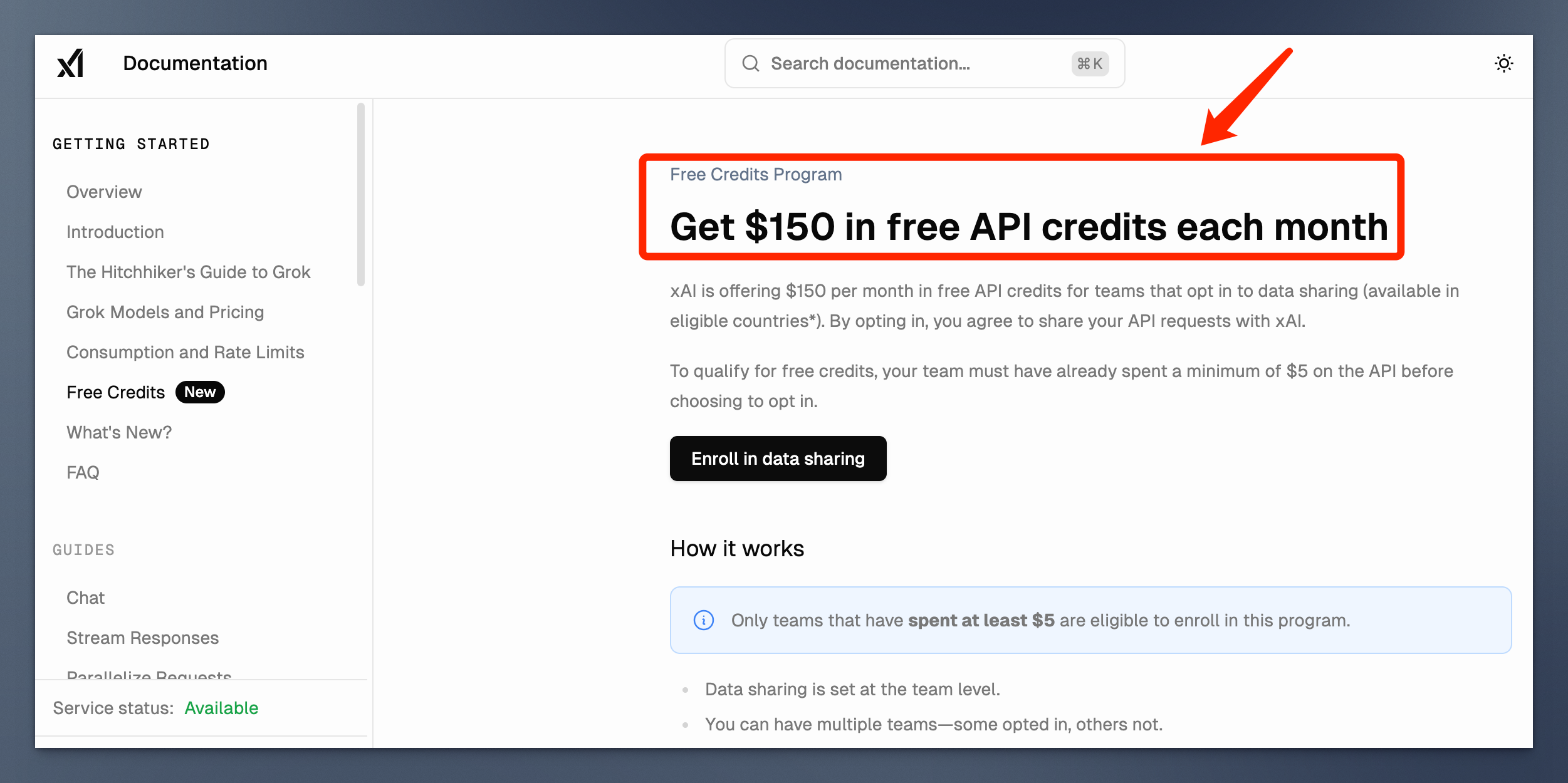
所有这些免费 tokens 的前提,都是 “数据共享”,即:这些 AI 厂商有权使用你的提示词和模型的回答来训练、优化、研究 AI 模型。
推出这种活动的原因也很简单:缺少高质量训练数据。数据是 AI 模型训练的“第一生产力”。然而,互联网上的数据是有限的,用一个少一个,但新模型的训练(如果按照传统的技术架构)又依赖更多的训练数据。这就是这些 AI 厂商感到危机的原因。
所以,在使用这类免费的 tokens 时,切记不要上传任何自己的隐私数据及敏感数据。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。

















 466
466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









