









1 vector
定义概要
class vector
{
public:
typedef value_type* iterator; //迭代器就是指针
typedef value_type& reference;
. . .
protected:
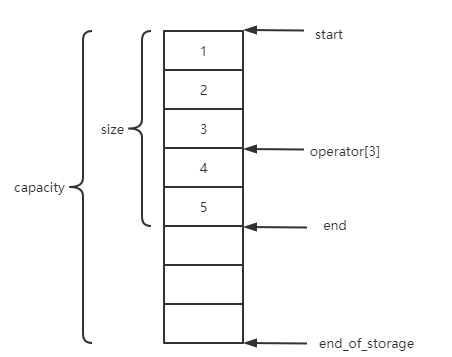
iterator start; //目前使用空间的头
iterator finish; //目前使用空间的尾
iterator end_of_storage; //目前可用空间的尾
public:
//O(1)
iterator begin() {return start;} //第一个元素的迭代器
iterator end() {return finish;} //最后一个元素的迭代器
int size() {return (end() - begin());} //当前元素个数
int capacity() {return end_of_storage()-begin();} //容量
bool empty() {return begin()==end();} //判断是否为空
reference font() {return *begin();} //第一个元素的引用
reference end() {return *(end()-1);} //最后一个元素的引用
void pop_back() {--finish;destory(finish);} //取出最尾端元素
//O(n)
iterator erase(iterator position){...} //清除某位置上的元素
iterator erase(iterator first,iterator last){...} //清除[first, last)
void clear(){erase(begin(),end());} //清除所有元素
void resize(int new_size, const T& x){ //调整size,不改变capacity
if(new_size < size()) //只需要将后面的截断
erase(begin()+new_size,end());
else //在后面补上x
insert(end(),new_size - size(),x);//调用insert,可能会改变容量
}
void push_back(const T&x){...} //在末尾插入
void insert(iterator pos,int n,int x){..} //在pos位置插入n个x,可能改变容量
}
空间管理
空间增长
一般情况下,vector的空间是只增不减的。vector的容量capacity是动态增长的,它并不是在原空间之后续接新空间(因为无法确保原空间之后有可供配置的空间),而是以原capacity的两倍另外配置一块新的空间,然后将原内容拷贝过来,并释放原空间。因此,对vector的任何操作,一旦引起空间重新配置,指向原vector放入所有迭代器都失效了。可能引起空间重新配置的操作有:push_back() insert() resize()。
https://blog.csdn.net/yangshiziping/article/details/52550291
1. 为什么是空间成倍而不是以固定值大小增长?
-
每次增长m倍,一直增长到n,需要复制的元素个数为:

因此,均摊复杂度为O(1); -
每次增长k个元素空间,一直增长到n,需要复制的元素个数为:

因此,均摊复杂度为O(n);
2.为什么倍数是1~2
参考:Milo Yip的回答 - 知乎

如果是以k = 2倍的方式增长,那么原先的分配空间将刚好不能被下一次所重复利用,例如4+8 < 16,4+8+16 < 32,因此最好就选k < 2;
比如取k = 1.5,可以看到在几次扩展之后,前面的空间可以再次被利用到,而不是每次都要去寻找一个更大的空间。当然,之前的空间能够重新被分配的前提是这些内存是连续的;
3. 一些疑问
疑问1:在上图中,既然在后面有连续的内存可以分配,为什么不在原来的基础上追加呢?
- 一般分配器不支持 realloc(),即使支持也需要有 in-place 扩展功能。一般在应用层面只能重新分配一块新内存,然后把旧的数据复制过去,再释放之前的内存;
释放vector的内存空间
需要注意,clear() erase()等操作并不会释放内存空间,也就是不会改变capacity,那么何时会释放vector的内存空间呢?有2种情形:
- vector离开作用域,自动调用析构函数;
- 调用
swap(),手动释放内存,swap交换技巧实现内存释放的思想是:假设需要释放my_v的内存空间,使用vector的默认构造函数建立临时vector对象tmp_v,再调用swap()函数,交换my_v和tmp_v的空间,这样my_v就具有临时对象的大小,而临时对象随即被析构,从而其占用的空间也被释放。
vector<int>().swap(my_v);
等价于:
{
vector<int> tmp_v(); //一个空的容器
tmp_v.swap(my_v); //tmp_v拥有my_v的内存空间
}
//tmp_v离开作用域,其内存空间(也就是之前my_v的内存)被释放
vector<int> my_v;
cout << "新建一个空的vector my_v, 其capacity为" << my_v.capacity() << endl;
for(int i = 0; i < 10;i++) my_v.push_back(i);
cout << "插入元素后,my_v的capacity为 " << my_v.capacity() << endl;
vector<int>().swap(my_v);
cout << "与临时vector进行swap()后,my_v的capacity为" << my_v.capacity() << endl;

迭代器
vector的迭代器就是指针:
vector<int>:: iterator iter1; //类型是int*
vector<A>:: iterator iter2; //类型是A*
迭代器何时失效
迭代器失效意味着它指向的位置使能无效的,迭代器失效的情形有:
- 空间重新配置,前面已经提到,引起空间重新配置的操作有
push_back() insert() resize(); insert() resize(),当insert()不引起空间重新配置时,也会使插入位置后面的迭代器失效,resize()可能会调用insert();erase() clear(),erase()会使被清除元素后面的迭代器失效,clear()相当于erase( begin(),end() )。
实例
2 list
相较于vector的连续空间,list就显得复杂许多,它的好处就是每次插入或删除一个元素,就配置或释放一个元素的空间。因此,list对于空间的运用有绝对的精准,一点也不浪费,而且,对于任何位置的元素的插入或元素移除,list永远是O(1)。
list的节点(node)
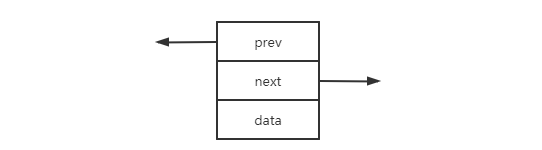
list的本身和list节点的是不同的结构,需要分开设计。下面先介绍list的节点(node):
template<class T>
struct __list_node{
typedef void* void_pointer;
void_pointer prev;
void_pointer next;
T data;
}
显然,这是一个双向链表:
list的迭代器
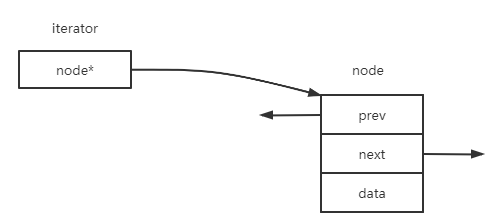
list不能像vector那样用普通指针作为迭代器,因为它的节点不保证在连续的存储空间存在。list的迭代器必须有能力指向list的节点,并且能够正确地递增、递减、取值等操作。
list迭代器有一些重要的性质:
- 插入操作和接合操作(splice)都不会造成原有list迭代器失效;
- list的元素删除操作(erase)也只有“指向被删除元素”的那个迭代器失效,其他迭代器不受影响。
下面是list迭代器的设计:
template<class T, class Ref, class Ptr>
struct __list_iterator
{
typedef __list_iterator<T, T&, T*> iterator;
typedef __list_iterator<T, Ref, Ptr> self;
typedef T value_type;
typedef Ptr pointer;
typedef Ref reference;
typedef __list_node<T>* link_type;
link_type node; //迭代器内部有一个普通指针,用于指向list节点
//构造函数
__link_iterator(link_type x):node(x) { }
...
bool operator==(const self& x)const
{
return node == x.node;
}
reference operator*()const { return (*node).date; }
pointer operator->()const { return &(operator*());}
//前缀++
self& operator++()
{
node = (link_type)((*node).next);
return *this;
}
//后缀++
self operator++(int)
{
self tmp = *this;
++*this; //调用前缀++
return tmp;
}
//前缀--与后缀--同理
...
}
list的数据结构
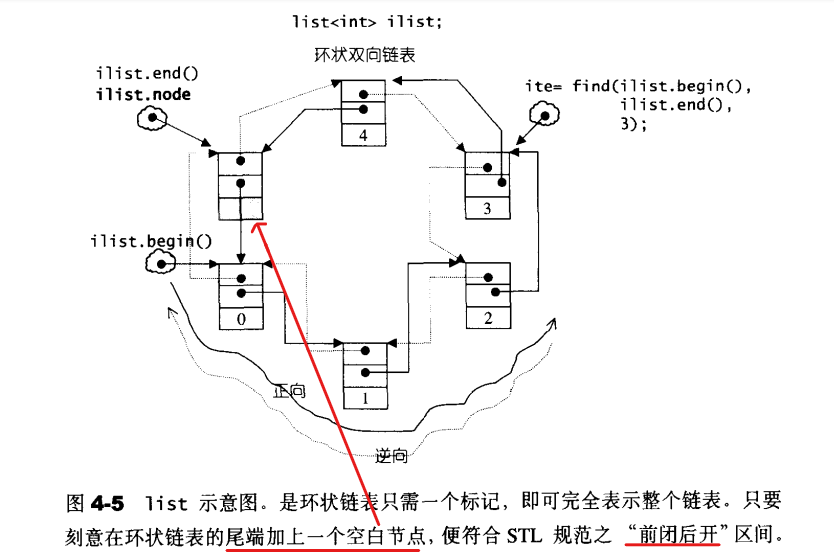
SGI list不仅是一个双向链表,还是一个环状双向链表。所以它只需要一个指针,便可以完整表示整个链表:
template<class T, class Alloc = alloc>
class list
{
protected:
typedef __list_node<T> list_node;
public:
typedef list_node* link_type;
protected:
link_type node; //只需要一个指针,就可以表示整个环状双向链表
public:
iterator begin() { return (link_type)((*node).next); }
iterator end() { return node; }
bool empty() const
{
return node->next == node;
}
//取头结点的内容(元素值)
reference front() { return *begin(); }
//取尾结点的内容(元素值)
reference back() { return *end(); }
}
list的元素操作
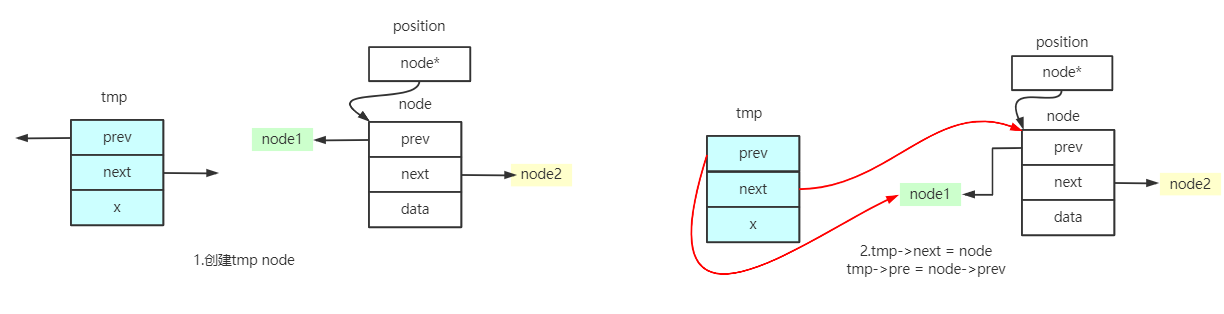
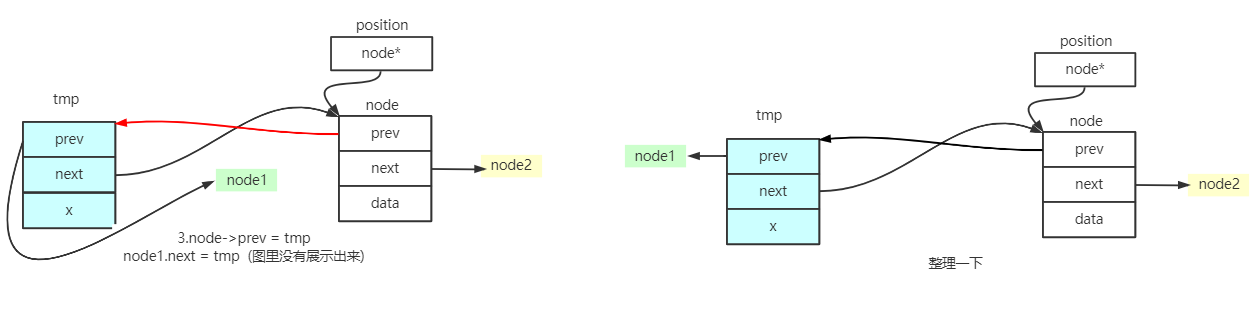
insert()
//在迭代器position所指位置插入一个节点,内容为x
iterator insert(iterator position, const T& x)
{
link_type tmp = create_node(x);
tmp->next = position.node;
tmp->prev = position.node->prev;
(link_type(position.node->prev))->next = tmp;
position.node->prev = tmp;
return tmp;
}
size()
复杂度为O(N),调用distance():
size_t size() const
{
size_t res = 0;
distance(begin(),end(),res); //全局函数P98,并非list特有
return res;
}
erase()
iterator erase(iterator position)
{
link_type next_node = link_type(position.node->next);
link_type prev_node = link_type(position.node->prev);
prev_node->next = next_node;
next_node->prev = prev_node;
destory_node(position.node);
return iterator(next_node);
}
clear()
//遍历链表,并逐个将节点销毁
void clear()
{
link_type cur = (link_type) node->next; //begin()
while(cur != node) //遍历每一个节点
{
link_type tmp = cur;
cur = (link_type) cur->next;
destory_node(tmp);
}
//恢复node原始状态,即只有一个空白节点的状态
node->next = node;
node->prev = node;
}
remove()和unique()
//将数值为value的所有元素移除
void remove(const T& value)
{
iterator first = begin();
iterator last = end();
while(first != last) //遍历每个节点
{
iterator next = first;
++next;
if(*first == value) earse(first);
first = next;
}
}
//移除数值相同的连续元素,注意,只有“连续而相同的元素”才会被移除剩一个
void unique()
{
iterator first = begin();
iterator last = end();
if(first == last) return;
iterator next = first;
while(++next != last) //遍历每个节点
{
if(*first == *next)
erase(next);
else
first = next;
next = first;
}
}
reverse()
transfer()
transfer()是splice(),merge()和sort()的基础。
splice()
merge()
将两个有序的list合并成一个有序的list。
sort()
由于STL算法的sort只接受RandomAccessIterator,因此list需要自己实现自己的排序算法,采用的是归并排序:
template <class T>
void list<T>::sort()
{
//下面判断空链表,或仅有一个元素
//使用size()<=1来判断复杂度是O(N),因此直接判断节点更快一些:
if(node->next == node || link_type(node->next)->next == node)
return;
//一些新的lists,作为中介数据存放区
list<T> carry;
list<T> counter[64];
int fill = 0;
while(!empty())
{
carry.splice(carry.begin(), *this, begin());
int i = 0;
while(i < fill && !counter[i].empty())
{
counter[i].merge(carry);
carry.swap(counter[i++]);
}
carry.swap(counter[i]);
if(i == fill) ++fill;
}
//最后将counter数组merge起来,再放回this中
for(int i = 1;i < fill; i++)
counter[i].merge(counter[i-1]);
swap(counter[fill-1]);
}
假设初始链表为:

每次循环的过程如下:
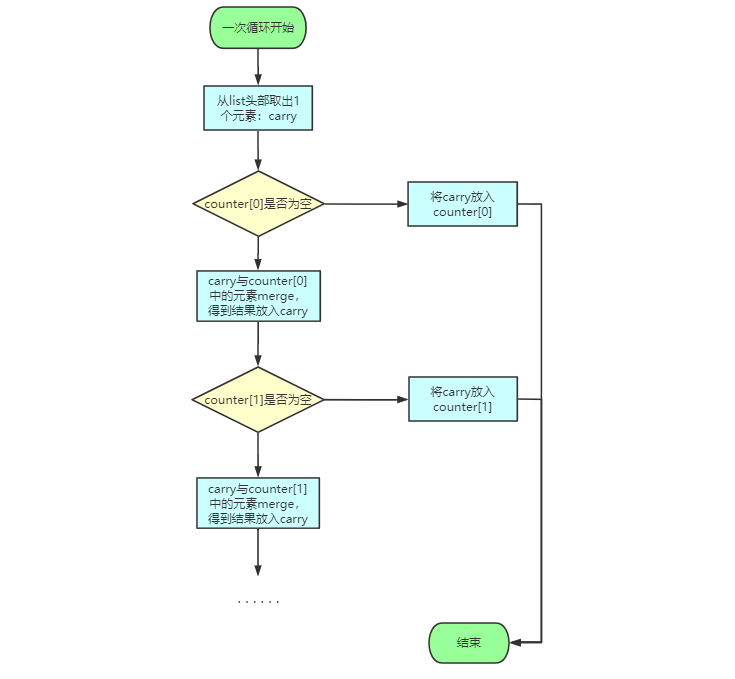
counter数组在每次循环的变化如下:

list.sort不同于传统的归并排序,传统的归并排序需要在O(1)时间内找到数组的中点,而list无法办到,因此采用上面的办法,并且还避免了递归,十分巧妙。
3 deque
vector是单向开口的连续空间,deque则属一种双向开口的连续性空间。所谓双向开口,是指可以在头尾两端分别做元素的插入和删除操作,当然vector也可以在头尾两端进行操作(从技术观点),但是其头部操作效率极差。
deque相较于vector有以下特点:
- deque允许在常数时间内对头端进行元素的插入或删除操作;
- deque没有容量(capacity)观念,因为他是动态地以分段连续空间组合而成,随时可以增加一块新的空间链接起来;换句话说,deque不会像vector那样有“因旧空间不足而重新配置一块更大的空间,并将元素复制过去,再释放旧空间”的情况;
- deque的迭代器不再是普通指针,它的迭代器比较复杂,导致其多种操作的效率不如vector;例如要对deque进行排序操作,为了提高效率,可将deque完整复制到一个vector,将vector排序后,再复制回deque;
- 除非必要,我们应尽量使用vector而非deque。















 348
348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









