







卷积神经网络(Convolutional Network)
目录:
- 卷积神经网络的发展与优势
- 什么是卷积
- 卷积神经网络的结构
- 经典的卷积网络结构
- 代码实现
卷积神经网络的发展与优势
卷积层第一次被提出是在1998年,由Yann LeCun,Leon Bottou,Yoshua Bengio,Patrick Haffner等人发表的论文(http://goo.gl/A347S4)提出。该论文除了提出著名的LeNet架构,还第一次提出了卷积层(convolutional layers)和池化层(pooling layers)的概念。在二十多年前,Yann LeCun等人的LeNet-5就对手写数字识别达到非常好的效果。
卷积网络诞生之后,越来越多人意识到它在图像处理领域的优势。直到今天,CNN依然主要应用于图像领域。
CNN的优势:
-
减少参数。
普通的DNN(全连接的深度网络)在处理图像时,由于是把像素作为特征输入,假设一张100x100的彩色图像,输入层就需要100x100x3个神经元。假设第二层有1000个神经元(1000个真的不多,已经减少了大量传入到后面网络的数据量),则输入层与第一个隐藏层之间就有100x100x3x1000=30,000,000个参数,这还没算后面的网络呢。如此大的参数量对硬件要求很高。而CNN由于每两层之间只连接一部分,而且高度重复使用权重,所以,蚕食要比DNN少很多。训练速度更快。

图1:CNN后面的神经元只连接前面的一部分 -
保留了图像的结构化信息
普通的DNN把像素作为输入,像素彼此之间的结构化信息就这样被破坏了。
而CNN低层网络可以保留一些小的结构化信息,高层可以保留一些大的结构化信息。这样,就不会破坏图像的结构特征。这也是为什么CNN尤其适合图像处理的原因。 -
当CNN学会检测图像某个特征时,它可以在图像任何区域检测到该特征,因为一个特征图(feature map)上的权重是一样的。而DNN只能检测到该位置的特征。
什么是卷积
卷积在信号处理,复变函数等课程里都有介绍。书上介绍的卷积主要分为连续型和离散型两种。
***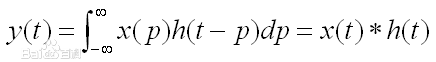
连续型卷积
连续型卷积主要是积分,两个函数在(-∞,+∞)的域内做积分。
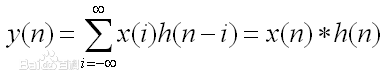
离散型卷积
对于离散型函数,积分肯定是不行的了。所以,就在(-∞,+∞)内进行相乘再相加的运算。
演示:
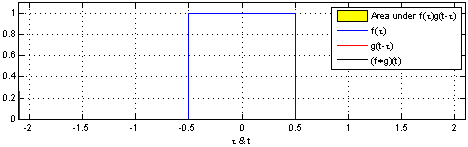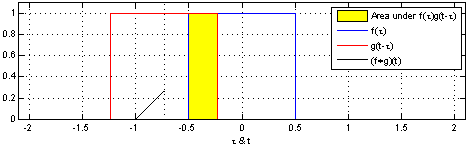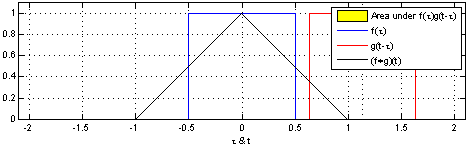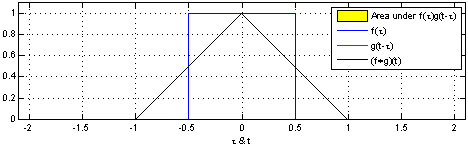
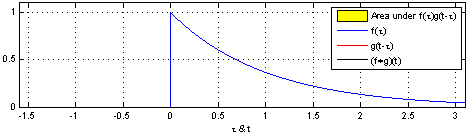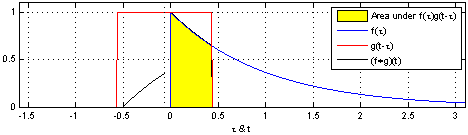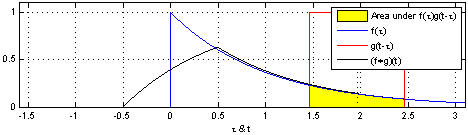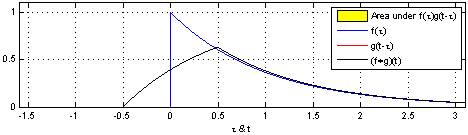
在深度学习中的卷积不再是一维的了,但是原理不变。
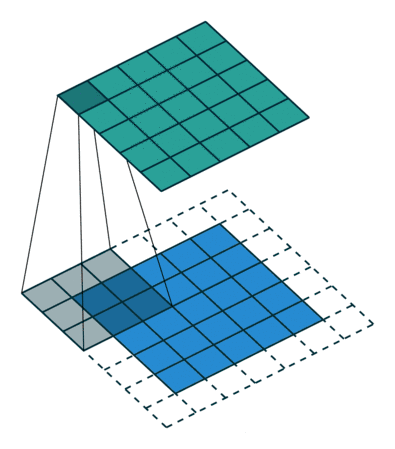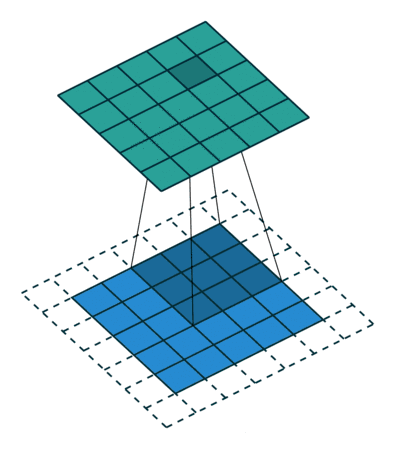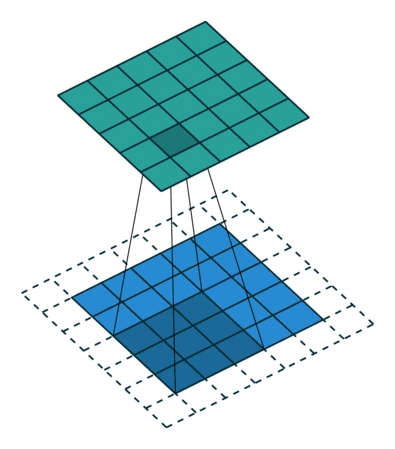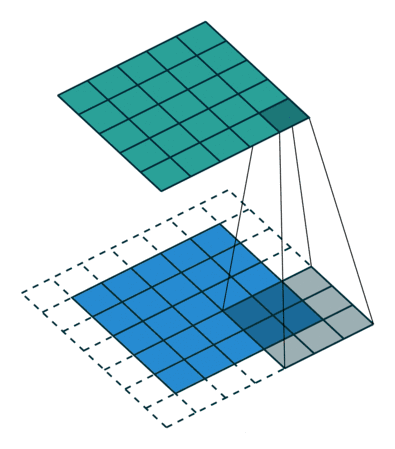
像这样,卷积的两个函数都是二维的,只不过一个大,一个小。小的叫做filter(上图中那个不断滑动的3x3阴影),filter不断在大的上面滑动,每次向左向下滑动多少叫做strides,上图中大的外面一层白色边框是加上去的全0的像素,如果不加,那么卷积之后生成的新图叫特征图(feature map)就比原来的每个边少一个像素(strides=1),加边框的这个过程角做zero padding。filetr每经过大的图像的一个区域,就把对应的元素相乘,再相加得到新的特征图的一个像素。
下图是一个卷积的计算过程:
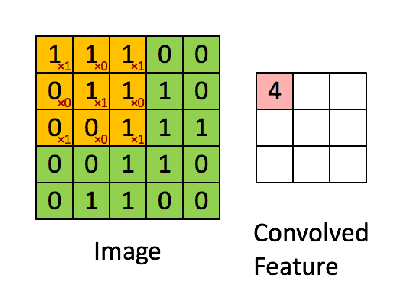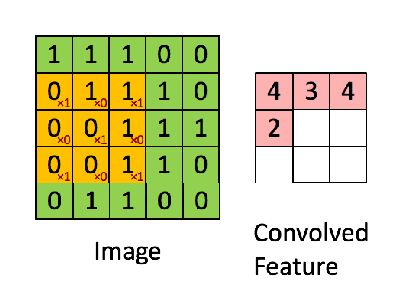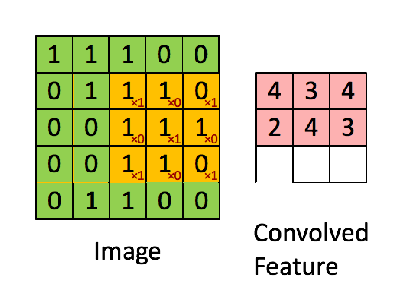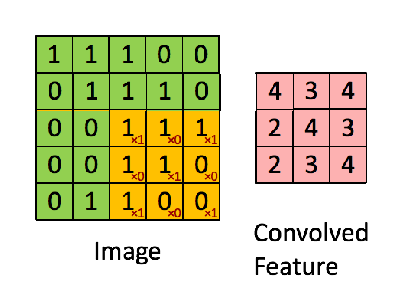
对于CNN,同一个卷积层不是只有一个特征图,而是很多。
卷积神经网络的结构
卷积神经网络最主要的就是卷积层,除此之外,还有一个叫做池化层的东西。理解了卷积层之后,池化层就简单了,因为池化层除了把卷积的相乘再求和改为直接求最大值或者均值外,其他都一样。
池化可以降低数据的大小,从而达到减小计算负载,内存利用率和参数数量,降低过拟合的风险等。
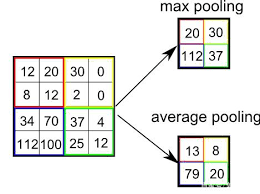
卷积和池化二者构成了CNN的基本结构。但是,作为图像分类的话,一般,最后还需要添加全连接层。
举一个例子来介绍CNN的基本结构:

首先,输入一个32x32的图像,通过卷积得到6个特征图,再通过池化,把特征图大小减小到一半。然后再通过卷积,池化。之后,通过全连接层得到输出。
经典卷积网络
LeNet-5

AlexNet

GoogLeNet

Google就喜欢整深层网络(有钱就是任性)
ResNet(残差网络)
这个才是可怕,152层

ResNet的创造性不在于它的卷积结构,而在于它的残差学习:

如图,普通的神经网络(CNN也好,DNN也好)都是一层连一层,而resnet除了相邻层之间有连接,隔一层的不相邻层还有连接,相当于添加了一个捷径。
VGG
我个人很喜欢VGG,网络简单,效果还不错。

代码实现
LeNet:
from keras import backend as K
from keras.models import Sequential
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers.core import Activation
from keras.layers.core import Flatten
from keras.layers.core import Dense
from keras.datasets import mnist
from keras.utils import np_utils
from keras.optimizers import SGD, RMSprop, Adam
class LeNet(object):
@staticmethod
def build(input_shape, classes):
model = Sequential()
model.add(Conv2D(20, kernel_size=5, padding='same', input_shape=input_shape))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2), strides=(2,2)))
model.add(Conv2D(50, kernel_size=5, border_mode='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2), strides=(2,2)))
# flatten
model.add(Flatten())
model.add(Dense(500))
model.add(Activation('relu'))
model.add(Dense(classes))
model.add(Activation('softmax'))
return modelVGG-16:
import pandas as pd
from keras.models import Sequential
from keras.layers import Dense,Activation,Flatten, Dropout
from keras.layers.convolutional import Conv2D, MaxPooling2D, ZeroPadding2D
from keras.optimizers import SGD
from keras.utils import np_utils
def myModel(weights_path = None):
model = Sequential()
model.add(ZeroPadding2D((1,1), input_shape=(28,28,1)))
model.add(Conv2D(64, (3,3),padding='same', activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(64, (3,3),padding='same', activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(128, kernel_size=3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(128, kernel_size=3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(256, kernel_size=3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(256, kernel_size=3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(256, kernel_size=3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(512, kernel_size=3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(512, kernel_size=3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(512, kernel_size=3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
return model














 2925
2925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









