









神经网络早期发展
卷积神经网络的发展,最早可以追溯到 1962 年,Hubel 和 Wiesel 对猫大脑中的视觉系统的研究。
20 世纪 60 年代初,David Hubel 和 Torsten Wiesel 在论文《Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex》中提出了 Receptive fields(感受野) 的概念,因其在视觉系统中信息处理方面的杰出贡献,他们在 1981 年获得了诺贝尔生理学或医学奖。
1980 年,日本科学家福岛邦彦在论文《Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position》提出了一个包含卷积层、池化层的神经网络结构。他的工作被人们评价为深度神经网络基本结构的开创性探索,是当前人工智能领域的核心技术。
(1980)Neocognitron: A Self-organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position
福岛邦彦首次使用卷积神经网络实现了模式识别,他被认为是真正的卷积神经网络发明者。
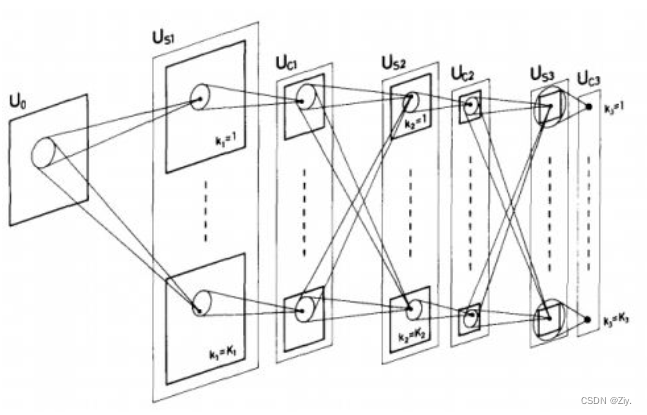
网络是模仿简单-复杂-简单-复杂的结构设计的。随着网络深度的增加,每个细胞的感受野变大,到最后一层,每个C细胞的感受野都达到输入U0尺寸的大小,最后网络能够将同一种形状的输入看作一种刺激,即形状不受位置和大小的影响。
Neocognitron的贡献:
- 将脑神经科学的结构做了计算机模拟
- 提出了现在CNN常用的step-by-step的filter
- 使用ReLU来给网络提供非线性
- 采用平均池化来做downsampling
- 保证了网络的平移不变性
- 实现了稀疏交互
而卷积运算的三个重要思想:稀疏交互,参数共享和等变表示中,该模型只有参数共享没有考虑到
(1989) Generalization and Network Design Strategies
1. 监督网络的泛化性能
- 网络的泛化性能取决于假设空间的大小(即网络中自由参数的数量) 和 训练样本的大小,减小网络中自由参数的数量、增加训练样本的数量能有效提高网络的泛化性能
- 将具体任务的先验知识加入到网络设计中,通常能够有效地减少网络的自由参数数量,达到较好的泛化性能
2. 提高网络泛化性能的常用方式
文中提到三种减小网络中自由参数的数量来提升泛化性能的方法
- 在网络训练过程中动态删除一些无用连接。这可以通过在损失函数中增加一项,用于惩罚那些拥有过多参数的网络来实现,即正则化思想。
- 使用单个参数控制多个连接,即权重共享。权重共享可以被解释为在这些连接强度上施加相同的限制。
- 权重共享的泛化,即权重空间转换(Weight-Space Transformation,WST)。学习过程中,模型参数优化不一定要在权重空间中执行,可以在任何适合该优化任务的参数空间中执行,只要该权重空间可以由该参数空间通过已知的转换公式计算得到,同时该转换公式的雅可比矩阵已知(因为该雅可比矩阵在反向传播计算损失函数关于参数空间的梯度时需要用到)。
3. 具体问题举例:数字识别
-
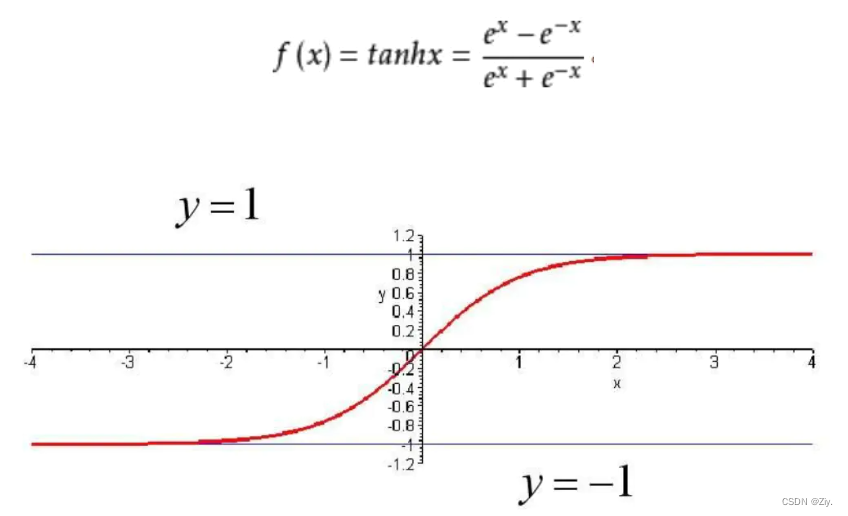
激活函数:双曲正切函数
-
损失函数:均方误差
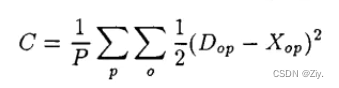
其中P为图像数量大小, D o p D_{op} Dop为p正确的分类, X o p X_{op} Xop为p的输出分类 -
设计的三种网络:
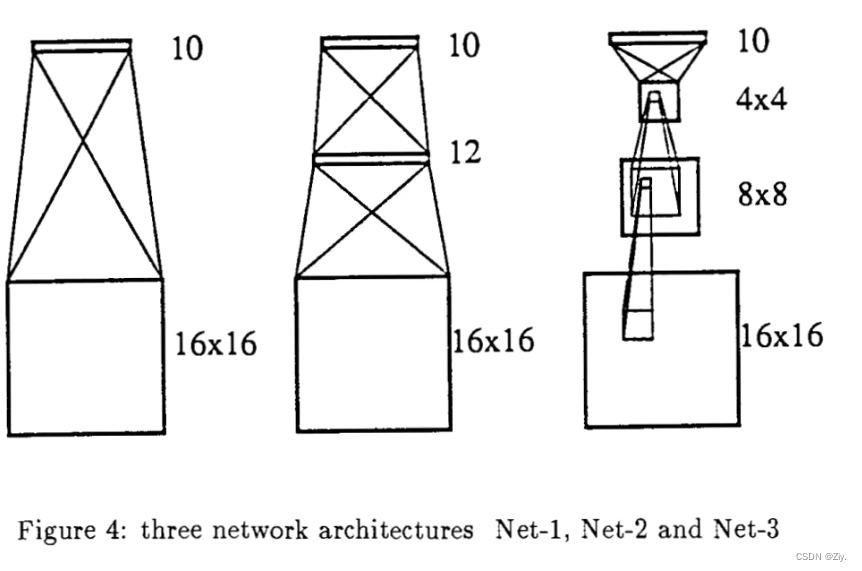
对于图像识别这类任务,可以先提取局部特征,然后将其结合成更高级的特征。因此,对于数字识别的问题,网络的隐藏层可以先提取输入图像的局部特征,然后进一步结合成更高级特征,即将数字识别任务的先验知识加入到Net-3的设计中- 单层网络Net-1:输入向量和权重向量经过点积运算之后再接一个激活函数得到输出结果,实质上为线性模型。包含 16×16×10+10 = 2570 个参数,其中10为图中已标注的权重组数,最后加的10为bias
- 两层全连接网络Net-2:在Net-1基础上增加包含了12个神经单元的隐藏层H1。包含3240个参数。Net-2在测试集上的准确率比Net-1高,但泛化性能的标准偏差比Net-1大许多,即Net-2模型太大,拥有太多自由的参数,处于欠定状态。
- 三层全连接网络Net-3:包含两个单通道隐藏层H1,H2,实质为不共享权重的卷积操作。其中H1采用3×3卷积核,得到8×8特征图((16-3+2×1) // 2+1),H2采用5×5卷积核得到4×4特征图((8-5+2×2)//2+1)。最后一层为包含10个神经元的输出层,整个模型包含1226个参数。相较于Net-1和Net-2,Net-3参数更少,速度更快。同时Net-3的泛化标准偏差比Net-2也小很多。
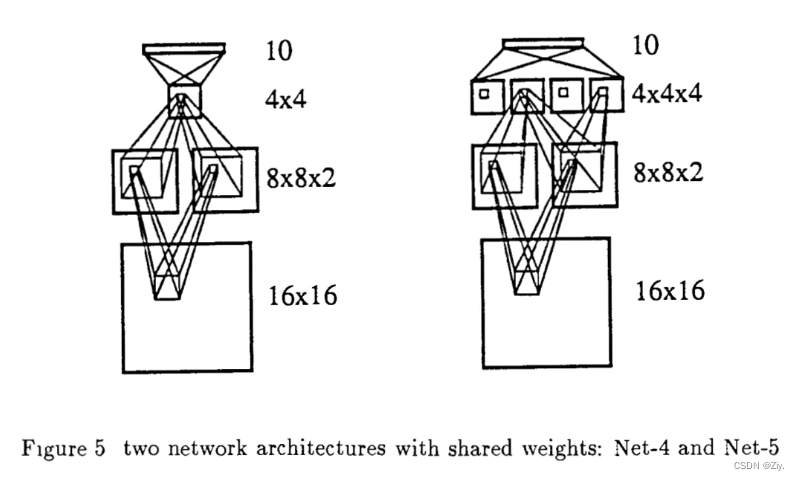
- 约束网络Net-4:每个卷积层都进行下采样操作,以保留特征大致信息位置,而且随着每一层特征图减小,全连接层的权重参数量会大大减小,有助于提升网络泛化性能。每个卷积层的卷积核和特征图大小与Net-3相同。但Net-4在H1中使用了两组权重共享的卷积分别得到两组特征图来捕获图像不同特征,H2中的卷积不共享权重(即两个8×8特征图分别使用自己的权重卷积得到4×4特征图)。Net-4有1132个参数,比前三个网络参数量都少,准确率也比前三个网络的高。说明权重共享和多组特征检测器的效果不错。
- 多层级特征提取器网络Net-5: H2和H4都采用权重共享,其中H2使用2个特征图,H4使用4个特征图,网络总参数为1060,准确率比前四个网络都要高,训练速度更快。说明多层级、多组权重共享的特征检测器效果相当不错。
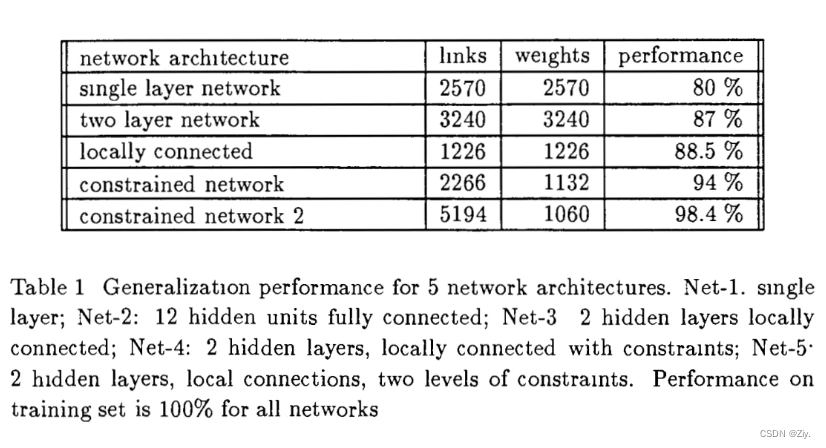
通过以上对5个网络的信息总结图中可以发现,从Net-1到Net-5的网络结构设计变换,网络中的连接变多了,通过使用权重共享,网络参数变少了,防止了模型过拟合,准确率提升了。
4. 总结
设计监督学习模型时,该文章的主要观点:处理实际问题时,当针对该问题的先验知识被加入到监督模型的设计中时,设计出的模型通常能在该问题上获得更好的泛化性能。
但搞清楚一个问题的先验知识具体指什么,该如何将先验知识设计到模型中不是一个简单的问题。
但该文章证明了针对图像识别任务,大神Yan LeCun成功将图像识别任务的先验知识(即先提取局部特征再进一步结合成更高级特征这一先验知识)加入到网络结构的设计中,即实验中的Net-3,Net-4和Net-5,并获得了优秀的泛化性能。
该论文中出现的专业术语如权重共享、感受野、激活函数、反向传播算法、损失函数、训练集、测试集、数据增强等一直被沿用至今。
(1989) Backpropagation applied to handwritten zip code recognition
这篇论文中,作者延续上一篇论文的思路,但其使用的数据集为美国邮局提供的手写邮政编码。
网络设计
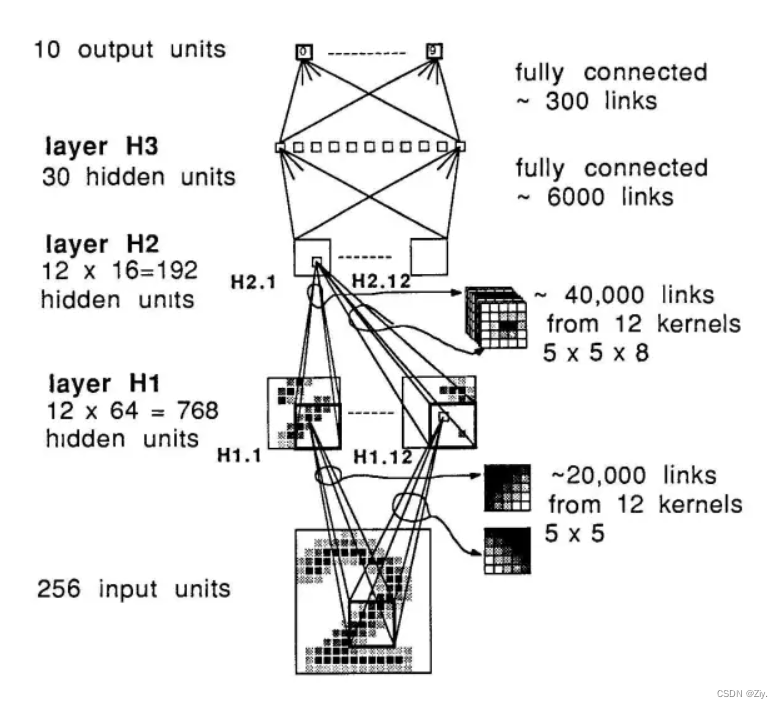
- H1和H2隐含层都含有12个特征图用于提取图像不同特征,卷积核大小都为5×5,且H1和H2中的所有卷积操作都采用了权重共享,但没有共享bias。但注意H2的输入只用了H1的12个特征图中的8个。其中H1和H2包含的特征图数量是通过实验确定的,即使用12个特征图时网络的泛化性能最优。全连接层H3含有30个神经元。
- 激活函数采用双曲正切,损失函数采用的均方误差。
(1990) Handwritten digit recognition with a back-propagation network
该论文是《Generalization and Network Design Strategies 》和《Backpropagation applied to handwritten zip code recognition》中提出模型的进一步扩展,数据集还是使用的手写邮政编码

- 输入图像大小由原先的16×16扩展为28×28。网络包含了四个隐含层,H1为5×5卷积核,步长为1的卷积层,得到4个24×24大小的特征图;H2为2×2卷积核,步长为2的平均池化层,得到4个12×12大小的特征图;H3为5×5卷积核,步长为1的卷积层,得到12个8×8大小的特征图,注意H3每个特征图卷积输入并不是H2中所有的4个特征图,而是只使用了其中的1-2个特征图(如下图所示)。
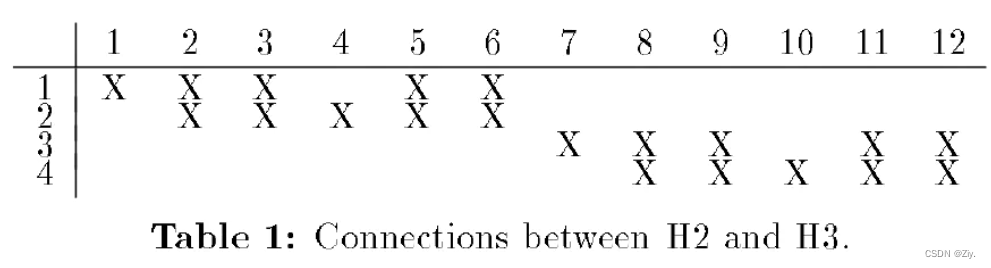
- H4为2×2卷积核,步长为2的平均池化层,得到12个4×4大小的特征图.H4直接通过一个全连接到输出层,丢掉了之前论文网络的全连接隐藏层
- H1和H3都是卷积层,H2和H4都是下采样层。
总结:它简化了卷积操作,便于将反向传播应用到CNN上
(1998, LeNet-5) Gradient-Based Learning Applied to Document Recognition
1. 文档识别系统通常由4个模块组成:
- 文本定位:找到目标文本所在位置,用矩形框框住
- 分割:将定位后的文本分割为多个单字符图像块
- 单字符识别:对分割后的单字符图像进行识别(LeNet-5所完成的工作)
- 语言模型:对多个识别结果选取结果最好的
2. 网络结构
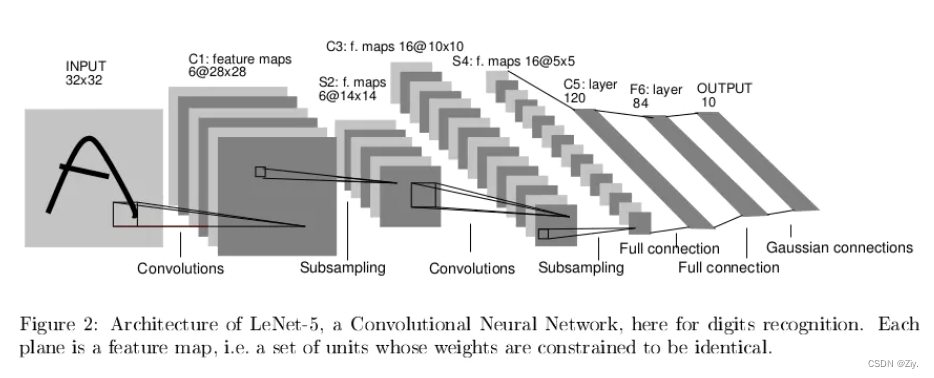
网络结构的解说参考链接的文章说的很清楚
注意从S2到C3的特征图并非一一映射,而是由S2中3-5个不同的特征图来做C3中每个特征图的输入。这样做的两个好处在于
- 打破网络对称性,让每个特征图获得不同的输入。保持各个特征图和而不同有利于其表征的鲁棒性。
- 这种非完全连接方式减小了一部分的网络连接数量,即降低了 模型的时间复杂度,加快模型训练速度
3. 数据集
构造了著名的mnist数据集


















 7272
7272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









