






GN层论文的实验结果做的非常非常的完善,真的是我看过所有论文里面图表给的最最最清晰的一个(毕竟Kaiming He的论文)。本篇博客在分析实验结果的同时也让自己从中学习到一些写作手法。因为这么简单的一篇论文,代码也就几句话,能发ECCV这跟实验结果完善也是分不开的。
论文:Group Normalization
作者:Kaiming He,Yuxin Wu
作者分别从CV的三个方向做了实验,分别是目标分类,目标检测和分割,视频分类。下面一一介绍
Image Classification in ImageNet
1.将BN,LN,IN,GN在ResNet50上做一个训练误差和验证误差对比。
如下图表所示(Batch_size=32)


这里训练误差GN是最小的,这说明了GN对优化问题非常的有效!超过了BN。这表明GN未来可以和更适合它的正则化方法一起训练获得更加好的性能。同时GN的验证误差是比BN大的,当然,作者认为这也是可解释的,GN确实在batch_size稍大的时候,丢失了一点正则化能力。这是因为BN的均值方差由于mini_batch采样引入一些随机性,这种随机性是模型更加鲁棒,从而使得BN在验证误差上表现的更好。但是其实也没有好到哪里,仅仅误差减少了0.5%,可以说是几乎是相当的。同时这是batch_size设置较大的理想情况,这并不是设计GN层的初衷。紧接着作者就分析了小batch_size上两者的比较。
2.将BN,GN在ResNet50上做一个训练误差和验证误差对比,如下图表所示(Batch_size=32,16,8,4,2)


其实第二张图左边的子图就说明了我自己实验存在的一些问题,不同的batch_size最终验证误差差距非常大,而GN呢?针对不同的batch_size,GN的验证集误差几乎没有差距。这也就说明了咱们的GN比BN在小batch_size下表现的更完美。
3.说完了GN在目标分类上获得的结果,作者又做了实验说这个Group,也就是将Channel分为几个Group和几个Channel为一个Group也做了实验。

将所有Channel分为32个Group,和每16个Channel为1个Group表现的最好。这里注意如果将所有Channel只分为1个Group则它就等价于LN(Layer Norm)。同理如果将1个Channel分为一个Group则它就等价于IN(Instance Norm)。可以注意到无论怎么将Channel进行分组,GN的效果总是优于IN和LN的。
4.更深的网络,ResNet-101
作者也在更深的网络上做了实验.作者在ResNet-101上也做了相同实验.当batch_size=32时,BN的验证误差为22.0%,GN的验证误差为22.4%,它们之间仅仅只差了0.4%。当batch_size=2时,BN的验证误差为31.9%,GN的验证误差为23.0%,之间相差了8.9%!这样就表明了咱们的GN同样适用于深层网络。
5.VGG models(这种原没有BN层和GN层的网络,作者这里是想证明下咱们的东西可移植性强不强。能不能同BN一样控制特征分布)

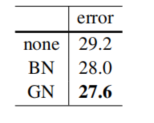
这个实验表明了对特征进行归一化对于控制特征分布是至关重要的,BN和GN都能起到相同的作用。即控制特征分布.同时使用GN的VGG16模型验证集误差要比使用BN的VGG16模型验证集误差要低。这意味着VGG16模型从BN中正则化效应中获益较小。而在GN中获益更大.
Object Detection and Segmentation in COCO
第二板块在coco数据集上目标检测和目标分割,模型使用Mask R-CNN
1.在backbone中加入GN层.,BN*代表BN层为FrozenBN,即采用在ImageNet上预训练的BN层参数,在COCO数据集上不更新BN层中的参数,作者尝试了微调BN层但在COCO数据集上表现的不好,所以直接忽视了这个消融实验,注意:以下两组实验的batch_size都为1,后面的batch_size也都是为1的.

客观上,GN在COCO数据集上表现要比BN*好,APbbox(检测评价指标)和APmask(分割评价指标)都得到了提升。但是在ImageNet数据集上,GN模型表现要比BN差(23.6%对24.1%)。这可能是因为BN在预训练和微调(冻结)之间造成了不一致。但GN在微调方面是优于BN的。这个实验说明了GN更适合于迁移学习。医学数据集的福音。
2.尝试将GN加在除了backbone以外的网络结构,这里我说一下我自己的看法,前面说过BN是控制特征分布的,检测网络的backbone就是进行特征提取的,而网络别的位置卷积层往往不是进行特征提取的。比如FPN网络中的特征融合?所以作者想尝试下加在这些卷积层看下效果

作者在这里就发现其实在网络其他位置加入GN层效果都是很好的,而不仅仅局限于特征提取的backbone中。
3.作者在第二点上获得启发,然后就将GN层加在Mask R-CNN中的backbone中,box head中,和mask head中。同时作者尝试了更多迭代次数。

这里根据上图和上上图的两个实验对比R50_GN(backbone,boxhead)AP:40.0
R50_GN(backbone,boxhead,mask_head) AP:40.3
又一次证明了GN加在其他的卷积结构中,对AP值也是有提高的
那么通过R50_GN和R50_GN_long对比,发现GN层可以从更多的迭代次数中获益。但是BN未能从较长的训练中获益。
4.从头开始训练
有数据集面临着迁移学习无用的情况,那么对于这种数据集就要重头训练,但是效果可能会出现在一个数据集上表现很好,在另一个数据集上表现很差的情况。那么作者实验用BN和GN分别在COCO数据集上进行从头训练。

作者进行了270k次迭代,达到41.0APbbox,与在ImageNet上预训练迁移来的效果(40.8APbbox)效果相当,甚至还要高?这也证明了GN从零开始训练也是效果很好的。
Video Classification in Kinetics
这个视频分类我没有接触过,这里就不多赘述了。















 7848
7848











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









