








第一次尝试论文翻译,多为逐字翻译,
暂时把专有名词及可能译不准的原文放在下方,词不达意之处恳请批评指正。
这是近期在NVIDIA的医学图像处理公开课上了解到的论文,自己读一下顺便分享给大家。
原文链接:
https://arxiv.org/abs/1810.06621v1
长文预警:最核心的部分是 Fig.1 和 四个loss function
------------------------------------------------------------------------------------------------------------------
摘要
引起医学图像退化的原因有很多,例如,金属植入会引起MRI扫描图像的局部混乱,这会使得后续的图像处理任务,例如衰减校准受到影响。在我们的工作中,提出了通过GAN进行图像修复的方法,该框架采用附加的两个基于补丁的判别器网络,和图像重建过程中,以详细现实和上下文连贯的方式呈现的缺失信息的感知器损失。( The proposed framework incorporates two patch-based discriminator networks with additional style and perceptual losses for the inpainting of missing information in realistically detailed and contextually consistent manner. )
该框架在双模态图像重建上的定性和定量表现都优于其他自然图像重建技术。
关键词:核磁成像,计算机断层扫描,医学图像重建,深度学习,GAN
1. introduction
医学图像是诊断的基础工具。然而,在扫描过程中造成图像信息缺失的原因多种多样,例如图像伪影,视野受限,已知数据的选择性重建,以及投影方法中的叠加外体( superposition of foreign bodies in projection methods)。丢失的信息不能在诊断的过程中被恢复,意味着真实的信息损失。然而,对于图像处理,填补扫描造成的信息损失也是研究热点。
例如PET/MRI中的衰减校正,MR数据被用于评估衰减系数。在这种情况下,需要的是整体特性而不是详细的局部特性;然而,用图像重建的方法去修复缺失的身体部分代价较大。与之相近的,图像重建可用于在放射性治疗中,在计算剂量分布之前调整图像伪影。通常,医学图像的实现是为目标服务的,无论图像分析的自动算法最后应用到哪里(分割或是分类),都需要一个完整的,无伪影的输入。因此,重建可以算作是医学图像数据管理(data curation)框架下的一部分。
当前的医学图像重建技术主要依赖于结构合成,插值,非局部均值和扩散等技巧。这些经典的技巧在重建更为复杂的图象时遇到困难。
从另一个角度看,自然图像的重建是计算机视觉研究领域的热点,尤其是在对GAN的研究中。上下文编码(Context Encoders, CE)是自然图像重建领域最常见的方法之一。这是基于以对抗方式训练一个编码-解码的判别器网络。然而,待重建的区域并不总是和周围环境上下文连续。全局和局部图像合成(GloballyandLocallyConsistentImageCompletion, GLCIC)在CE的基础上将判别器网络扩展为多模态。具体实现是在执行一个判别决策前,将一个基于全局特征的判别器网络和一些基于局部的网络融合。然而,为确保环境的连续性,需要更进一步的处理方法和漫长的训练过程。在[11]中,由分解两个判别网络,并用一个解析网络来加强重建效果。其他重建的方法包括利用文本注意力,感知器损失或超分辨率等。概述不在我们这篇文章的工作范围中。
在这项工作中,我们引入了用深度学习方法进行医学图像重建的话题。作为基准,我们用我们最近提出的MedGAN框架来实现医学图像转换任务。MedGAN是一个生成框架,组合了级联的U-net生成器框架(CasNet)和一个新的非对抗损失组合。然而,我们认为重建任务比风格转换任务更难。这是不仅是因为重建区域必须高保真,还因为重建区域必须保持和给定的上下文信息具有同质性(homogeneously)。受到自然图像处理技术的推进,我们扩展了MedGAN的附加局部判别网络来提高在重建上的表现。
我们的新模型,称为ip-MedGAN,能够生成全局连续的逼真结果,无需进一步加工处理。我们在不同的模态上(MRI和CT)上演示了我们的模型。更进一步地,我们定性和定量地和其他对抗重建方法做了对比。
2. Methods
我们的ip-MedGAN,是基于cGAN结构的,包括了一个基于补丁的局部判别器网络和附加的非对抗损失。图1是模型的框图。

2.1 条件生成对抗网络
cGAN由两个卷积网络组成:生成器G和全局判别器D。在该框架中,上下文图像y,作为G的输入。y是一张256*256的2D图像,随机剪出一个64*64的区域,即缺失部分占整幅图像的1/16。生成器利用给定的上下文信息重建缺失的部分,形成生成图像。另一方面,判别器接收没有信息损失的目标图像x或者生成图像
作为输入。利用二进制的交叉熵损失函数来分类哪一张输入图像是生成器G的生成的,记为
,哪一张是真实的分布,记为
。通过博弈理论训练网络,即生成器试图骗过判别器,使之错将
认为是真实图片;同时判别器不断提高性能避免被骗。以下是训练过程中的优化任务:
![]()
其中是对抗损失函数。
对于生成网络来说,CasNet结构用于级联U-net网络,以端到端的方式批规范化和跳跃连接。这被用于把生成任务分配到更广泛的网络中,因而生成更精确的输出。CasNet被证明是一个有效的方法,不但能够提高网络的表现能力,同时可以稳定训练过程,避免梯度消失或参量指数增长等深度相关的问题发生。更多的结构细节在[16]中。
判别器网络与[19]中的网络相同。它是一个补丁判别器,将输入图像分成重叠的70*70的小块,再判断每个小块的真假。计算所有小块的分数并作平均,得到最后的分类结论。我们认为这是一个全局的判别器网络,因为它将整幅图像(而不是重建部分或目标块)作为输入。通过集中于一个个小块(这些小块是从整幅图像中提取的),全局判别器能确保重建区域与给定的上下文信息同质。
2.2 基于补丁(Patch-Based)的局部判别器
受最近自然图像重建技术的启发,MedGAN包括了一个附加的判别器网络:局部判别器。与全局判别器相比,
只接收重建
或目标区域
。这允许了局部判别器集中于重建区域的细节,而不是整幅图像中全局的上下文信息。
也是一个基于补丁的网络,将图像分成34*34的相互重叠的输入域用于分类。判别器以对抗的方式训练,与Eq.1类似。
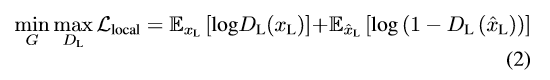
2.3 非对抗损失
为了提高重建质量,用附加的非对抗损失训练生成网络。首先,是风格重建损失,它将引导生成器匹配目标输出和生成输出之间的风格和纹理。该损失由预训练网络中提取出的中间特征图来计算。本文使用了一个VGG-19网络在ImageNet上的预训练模型。提取出的特征图被用于计算Gram矩阵。和
分别代表了目标输出和生成输出在空间特征上的联系。风格重建损失由下式给出,即Gram矩阵Frobenius范数的加权平均的平方(the weighted average of squared Frobenius norm of the Gram matrices):
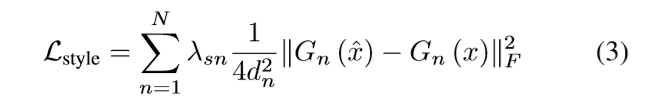
和
分别代表第n层特征提取网络的空间深度和权值,N是总的层数。
在该框架中运用的第二个非对抗损失是感知器损失。它专注于最小化像素之间的差异,使得两幅图像间的感知差异最小化,它能保证更具备全局连续性的生成图像。为了评估感知损失,我们会计算两幅图像的绝对平均误差(mean absolute error, MAE),以及从全局判别器网络提取出的中间的特征图。因而,感知器损失是MAE的加权平均数:
![]()
和
分别是从全局判别器的第n层提取出的权值和特征图。B是全局判别器的总层数,
表示未加工的输入图像。
2.4 ip-MedGAN的框架
总而言之,ip-MedGAN包含了一个CasNet生成器和一个全局判别器,保证了重建区域与周围上下文信息的同质性。该框架附加了一个局部判别器来增强重建输出在细节上的表现。生成器同时最小化了感知器和对纹理和感知优化的风格重建损失。最终的损失函数如下:
![]()
3.数据集和实验
略..

4.结论和探讨
定量和定性的对比分别见表1和图2。

从图中可以看出,CE的重建缺乏同质性,GLCIC的重建图像在全局上表现较好,但是比较模糊,缺乏锐化。MedGAN在局部锐化和全局连续性上都表现较好,但是缺乏细节,并存在不真实的倾斜伪影。ip-MedGAN超越了MedGAN的纹理质量和重建区域的细节。对应地,ip-MedGAN在定量评价上也表现较好。
从另一个角度来看,ip-MedGAN也不是没有局限,训练过程中,局部判别器需要缺失区域的位置信息。但是,这在生成器网络推理中是不必要的。实际中位置信息往往是不具备的,除非有附加的分割网络作为预处理步骤。此外,我们只考虑了随机区域固定大小的区域的情况,而在现实情况中,由于金属植入及其他类似情况造成的形变都是任意形状的。
5. Conclusion
在我们的工作中,我们介绍了一种医学图像重建手段,来填补缺失或形变的信息。这对图像的后续处理是很有帮助的。我们引入了一个对抗框架,包含了两个基于补丁的判别器网络,和附加的非对抗损失。这保证了重建结果与给定的上下文信息在局部和全局上的连续性。我们提出的框架在定性和定量上的表现都优于其他技术。
未来,我们计划引入分割网络来省去人工标注缺失区域的步骤。更进一步地,我们计划测试该模型在任意缺失形状上的泛化性能。最后,重建结果在未来临床后期处理上是否表现良好,还需要与其他传统方法进行比较。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









