






1. one-hot
Onehot转换
def convert_to_one_hot(Y, C):
Y = np.eye(C)[Y.reshape(-1)]
return Y2. 词和index以及词向量的转换
def read_glove_vecs(glove_file):
with open(glove_file, 'r', encoding='utf8') as f:
words = set() # 集合避免重复
word_to_vec_map = {} # 词到词向量
for line in f: # 默认按行读取
line = line.strip().split() # strip移除字符串头尾指定的字符序列,默认为空格
curr_word = line[0] # 取出单词
words.add(curr_word) # 添加单词
word_to_vec_map[curr_word] = np.array(line[1:], dtype=np.float64) # 用字典建立索引
i = 1
words_to_index = {}
index_to_words = {}
for w in sorted(words): # sorted可以对所有可迭代对象进行排序操作,返回一个新的list
words_to_index[w] = i
index_to_words[i] = w
i += 1
return words_to_index, index_to_words, word_to_vec_map3. 加载训练好的词向量
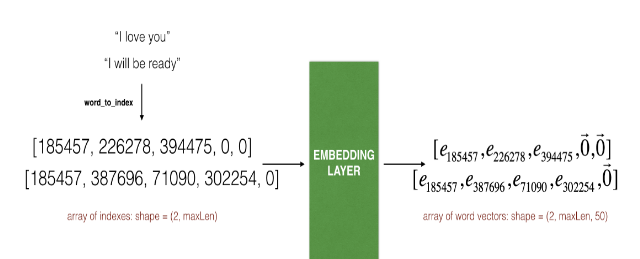
Embedding层
- 经过下面函数,完成了
I love you ---> [185457, 2262788, 394475, 0, 0]的转换
def sentences_to_indices(X, word_to_index, max_len):
m = X.shape[0] # 有多少个句子
x_indices = np.zeros(shape=(m, max_len))
for i in range(m):
sentence_words = (X[i].lower()).split()
j = 0
for w in sentence_words:
X_indices[i, j] = word_to_index[w] # 将每句话中的单词索引为index
j +=1
return x_indices加载之前训练好的词向量
def pretrained_embedding_layer(word_to_vec_map, word_to_index): vocab_len = len(word_to_index) + 1 # 词的数量 emb_dim = word_to_vec_map["cucumber"].shape[0] # 单个词向量的维度=50 embedding_layer = Embedding(input_dim=vocab_len, out_dim=emb_dim, trainable=False) # input_dim词汇表大小,即最大整数Index+1 out_dim:词向量维度 # 设置权重 emb_matrix = np.zeros(shape=(vocab_len, emb_dim)) for word, index in word_to_index.items(): # 循环单词和索引 emb_matrix[index, :] = word_to_vec_map[word] # 设置嵌入层权重之前,需要build嵌入层 embedding_layer.build((None,)) embedding_layer.set_weights([emb_matrix]) return embedding_layer
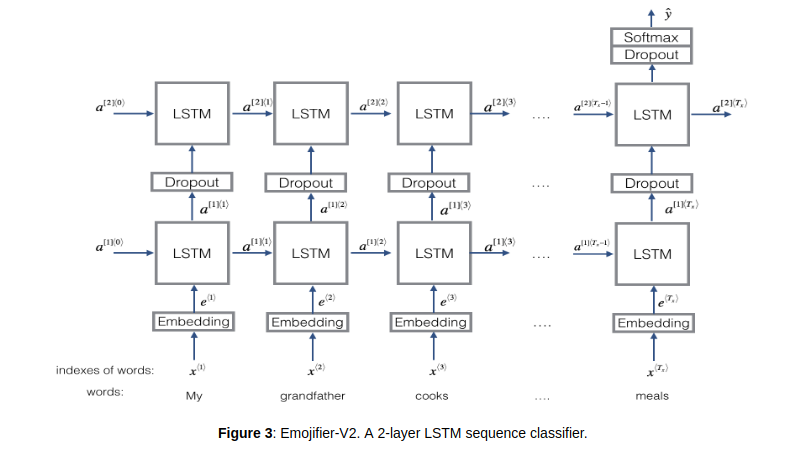
4 第一个模型
def Emjify_V2(input_shape, word_to_vec_map, word_to_index):
"""
input_shape -- shape of the input, usually (max_len,)
"""
sentence_indices = Input(shape=input_shape, dtype='int32')
embedding_layer = pretrained_embedding_layer(word_to_vec_map, word_to_index)
embeddings = emedding_layer(sentence_indices) # 自定义的Layer对象的方法,第二个括号可以传递入张量
X = LSTM(units=128, return_sequence=True)(embeddings) # return_sequence是否全部接受
X = Dropout(0.5)(X)
X = LSTM(units=128, return_sequences=False)(X)
X = Dropout(0.5)(X)
X = Dense(units=5)(X)
X = Activation('softmax')(X)
model = Model(inputs=sentence_indices, outputs=X)
return model













 290
290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









