







 该博客详细探讨了泰坦尼克号上乘客的生存率,包括数据总览、年龄、性别、船舱等级、家庭成员数量以及票价对存活率的影响。发现女性和儿童的存活率更高,而家庭成员多的乘客生存机会较大,高票价乘客生存概率也较高。最后,利用KNN模型进行预测,清洗后的训练和测试样本分别为714和331个。
该博客详细探讨了泰坦尼克号上乘客的生存率,包括数据总览、年龄、性别、船舱等级、家庭成员数量以及票价对存活率的影响。发现女性和儿童的存活率更高,而家庭成员多的乘客生存机会较大,高票价乘客生存概率也较高。最后,利用KNN模型进行预测,清洗后的训练和测试样本分别为714和331个。
泰坦尼克号生存率分析
1. 数据总览
Titanic 生存模型预测,其中包含了两组数据:train.csv 和 test.csv,分别为训练集合和测试集合。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
import time #导入事件模块
import warnings
warnings.filterwarnings('ignore')#不发出警告
2. 观察前几行源数据
train_data=pd.read_csv('train.csv')
test_data=pd.read_csv('test.csv')
train_data.head()
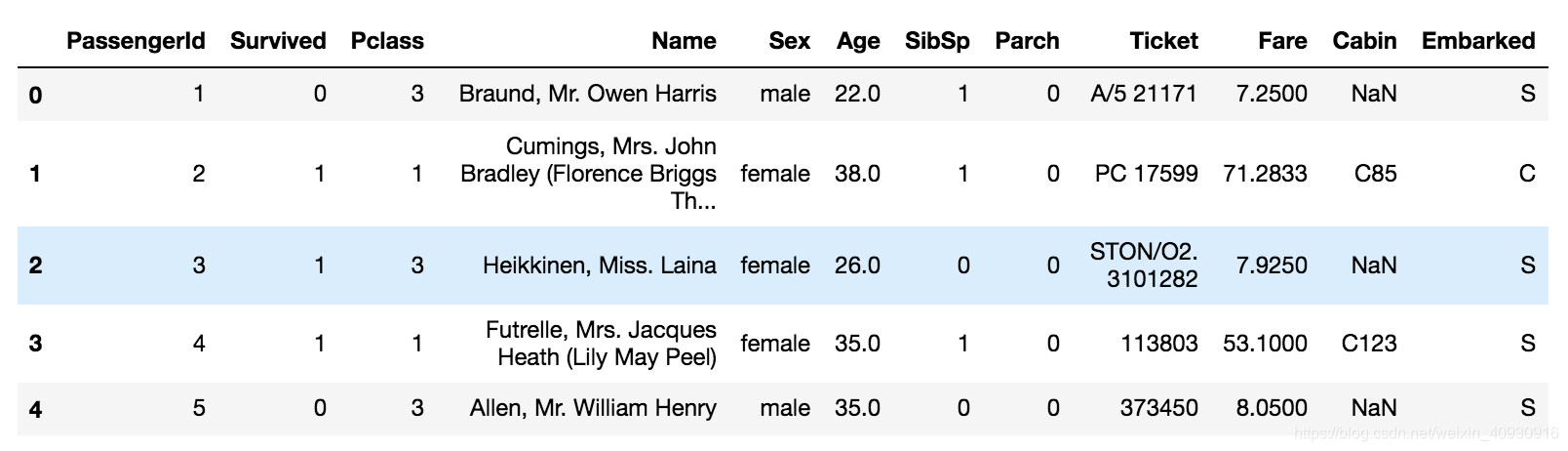
3. 绘制存活比例
sns.set_style('ticks')
plt.axis('equal')
train_data['Survived'].value_counts().plot.pie(autopct='%1.2f%%')
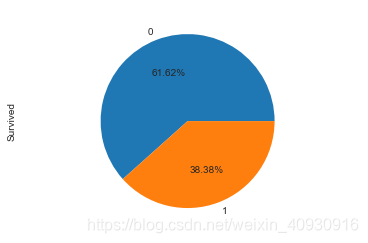
4. 结合性别和年龄数据,分析幸存下来的人群特征
① 年龄数据的分布情况
train_data_age = train_data[train_data['Age'].notnull()]
plt.figure(figsize=(12,5))
plt.subplot(121)
train_data_age['Age'].hist(bins=70)
plt.xlabel('Age')
plt.ylabel('Num')
plt.subplot(122)
train_data.boxplot(column='Age',showfliers=False)
print('总体年龄分布: 去掉缺失值后样本有714,平均年龄约为30岁,标准差14岁,最小年龄0.42,最大年龄80.')
train_data_age['Age'].describe()
 总体年龄分布: 去掉缺失值后样本有714,平均年龄约为30岁,标准差14岁,最小年龄0.42,最大年龄80.
总体年龄分布: 去掉缺失值后样本有714,平均年龄约为30岁,标准差14岁,最小年龄0.42,最大年龄80.
② 男性和女性存活情况
train_data[['Sex','Survived']].groupby(['Sex']).mean().plot.bar()
survive_sex = train_data.groupby(['Sex','Survived'])['Survived'].count()
print(survive_sex)
print('女性存活率为%.2f%%,男性存活率为%.2f%%' %
(survive_sex.loc['female',1]/survive_sex.loc['female'].sum()*100,survive_sex.loc['male',1]/survive_sex.loc['male'< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4952
4952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









