










前一篇文章介绍了TensorFlow的基础知识,主要是张量的基本操作,这篇文章主要介绍有些张量的进阶操作,譬如合并、分割、范数统计、填充、限幅等。
tf2.0这些也重要(二)——高级知识
2.1 合并与分割
2.1.1 合并
合并是指将多个张量,按照某一维度进行合并,称为一个张量。
合并还分为拼接和堆叠两种操作。
拼接在TensorFlow中用 tf.concat(tensor_list, axis) 实现。
a = tf.random.normal([4, 32, 32, 3])
b = tf.random.normal([3, 32, 32, 3])
tf.concat([a, b], axis=0).shape
TensorShape([7, 32, 32, 3])
上例中,a和b分别代表4张RGB图片和3张RGB图片,concat操作后变成一个张量,代表7张RGB图片。
堆叠是另一种合并操作,在合并数据时会创建一个新的维度,用 tf.stack 实现。
a = tf.random.normal([32, 32, 3])
b = tf.random.normal([32, 32, 3])
tf.stack([a, b], axis=0).shape
TensorShape([2, 32, 32, 3])
上例中,a 和 b 分别代表两张RGB图片,由于没有batch_size维度,说明两个张量都只代表了一个图片,stack操作以后,新增了batch_size维度,且变成了一个张量。
2.1.2 分割
分割就是合并操作的逆操作。通过 tf.split(x, num_or_size_splits, axis) 实现。
- x:待分割的张量
- num_or_size_splits:如果为单个数值n时,表示分成等长的n份;如果为list时,list中的每个元素表示每分的长度。
- axis:分割的维度的索引号。
a = tf.random.normal([10, 32, 32, 3])
b, c, d, e = tf.split(a, [1, 2, 3, 4], axis=0)
b.shape
TensorShape([1, 32, 32, 3])
c.shape
TensorShape([2, 32, 32, 3])
2.2 数据统计
神经网络中经常需要统计数据的各种属性,最值,最值索引,均值,范数等等。
2.2.1 张量范数
向量范数是表征向量长度的一种度量方法,范数的概念也可以扩展到张量上。
- L1范数:
∥ x ∥ 1 = ∑ i ∣ x i ∣ \begin{aligned} \left\|x\right\|_1 = \sum_i |x_i| \end{aligned} ∥x∥1=i∑∣xi∣ - L2范数
∥ x ∥ 2 = ∑ i ∣ x i ∣ 2 \begin{aligned} \left\|x\right\|_2 = \sqrt{\sum_i |x_i|^2} \end{aligned} ∥x∥2=i∑∣xi∣2 -
∞
\infty
∞范数
∥ x ∥ ∞ = max ( x i ) \begin{aligned} \left\|x\right\|_\infty = \max(x_i) \end{aligned} ∥x∥∞=max(xi)
在TensorFlow中可以用 tf.norm(x, ord) 实现求范数操作
x = tf.ones([2, 2])
# L1范数
tf.norm(x, ord=1)
<tf.Tensor: shape=(), dtype=float32, numpy=4.0>
# L2范数
tf.norm(x, ord=2)
<tf.Tensor: shape=(), dtype=float32, numpy=2.0>
# ∞范数
tf.norm(x, ord=np.inf)
<tf.Tensor: shape=(), dtype=float32, numpy=1.0>
2.2.2 最值、均值、和
通过 tf.reduce_max、tf.reduce_min、tf.reduce_mean、tf.reduce_sum 函数可以求解张量在某个维度上的最大、最小、均值、和,也可以求全局最大、最小、均值、和信息。
x = tf.random.normal([4, 10])
# axis=0,结果为行维度的最大值
tf.reduce_max(x, axis=0)
<tf.Tensor: shape=(10,), dtype=float32, numpy=
array([ 1.0879955 , 1.6843221 , 0.2854478 , 1.9314889 , 2.994305 ,
0.5753196 , 0.2807909 , -0.04533401, 0.35265848, 0.70773816],
dtype=float32)>
# 当不指定axis是,默认取全局的最大值
tf.reduce_max(x)
<tf.Tensor: shape=(), dtype=float32, numpy=2.994305>
# tf.argmax
x = tf.random.normal([2, 10])
x = tf.nn.softmax(x, axis=1)
tf.argmax(x, axis=1)
<tf.Tensor: shape=(2,), dtype=int64, numpy=array([7, 5])>
tf.argmax如果不指定axis时,默认为0
*tf.reduce_如果不指定axis时,则默认取全局结果
2.3 张量比较
常用于预测结果于真是结果的比较中:
pred = tf.random.normal([100, 10])
pred = tf.nn.softmax(pred, axis=1)
pred = tf.argmax(pred, axis=1)
y = tf.random.uniform([100], dtype=tf.int64, maxval=10)
out = tf.equal(pred, y)
out
<tf.Tensor: shape=(100,), dtype=bool, numpy=
array([False, False, True, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
True, False, False, False, False, False, True, False, False,
False, False, False, False, False, True, False, False, False,
False, False, False, False, False, False, True, False, False,
False, True, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, True, False, False, False, False, False, False,
False, False, True, False, False, False, False, False, True,
False, False, False, False, False, False, True, False, False,
False, False, False, True, False, False, False, False, False,
False])>
out = tf.cast(out, dtype=tf.int64)
correct = tf.reduce_sum(out)
correct
<tf.Tensor: shape=(), dtype=int64, numpy=11>
其他比较函数如下表所以:
| 函数 | 逻辑 |
|---|---|
| tf.math.greater | 𝑎>𝑏 |
| tf.math.less | 𝑎<𝑏 |
| tf.math.greater_equal | 𝑎≥𝑏 |
| tf.math.less_equal | 𝑎≤𝑏 |
| tf.math.not_equal | 𝑎≠𝑏 |
| tf.math.is_nan | 𝑎 = nan |
T e n s o r F l o w 中 常 用 的 比 较 函 数 \begin{aligned} TensorFlow中常用的比较函数 \end{aligned} TensorFlow中常用的比较函数
2.4 填充与复制
2.4.1 填充
在文本或信号领域,不同数据的维度长度可能是不一样的,这时为了方便进行并行计算,我们一般把不同长度的数据填充成相同的长度,用0填充。
填充操作可以用***tf.pad(x, paddings)***实现,其中paddings是包含了多个
[Left Padding, Right Padding]的嵌套方案 List。
如[[0,0], [2,1], [1,2]]表示第一个维度不填充,第二个维度左边(起始处)填充两个单元,右边(结束处)填充一个单元,第三个维度左边填充一个单元,右边填充两个单元。
a = tf.constant([1,2,3,4,5,6])
b = tf.constant([7, 8, 1, 6])
# 左边为0,不进行填充;右边为2,填充2个0
b = tf.pad(b, [[0, 2]])
b
<tf.Tensor: shape=(6,), dtype=int32, numpy=array([7, 8, 1, 6, 0, 0], dtype=int32)>
在自然语言处理中,经常会遇到长短不一的句子,有的很短,有的很长,我们希望将不同大小的句子填充/截取成相同的大小。
可通过***tf.keras.preprocessing.sequence.pad_sequences***函数实现:
# 将句子填充或截断到相同长度 80,设置为末尾填充和末尾截断方式
maxlen = 80
x_train = tf.keras.preprocessing.sequence.pad_sequences(
x_train, maxlen=maxlen, truncating='post', padding='post'
)
2.4.2 复制
通过***tf.tile(x, multiples)***实现,在之前的文章中已经介绍过
b = tf.constant([1, 2])
b = tf.expand_dims(b, axis=0)
b.shape
TensorShape([1, 2])
b = tf.tile(b, multiples=[2,1])
b
<tf.Tensor: shape=(2, 2), dtype=int32, numpy=
array([[1, 2],
[1, 2]], dtype=int32)>
2.5 数据限幅
在 TensorFlow 中,可以通过 tf.maximum(x, a)实现数据的下限幅,即𝑥 ∈ [𝑎,+∞);可以通过 tf.minimum(x, a)实现数据的上限幅,即𝑥 ∈ (−∞, 𝑎]
x = tf.range(9)
tf.maximum(x, 2)
<tf.Tensor: shape=(9,), dtype=int32, numpy=array([2, 2, 2, 3, 4, 5, 6, 7, 8], dtype=int32)>
2.6 高级操作
TensorFlow还有很多比较复杂的高级操作。
2.6.1 tf.gather
***tf.gather***可以实现根据索引号收集数据的目的。以图片举例,假设有10张图片,现在想拿出第0,2,4张图片,可用如下方式:
x = tf.random.uniform([10, 32, 32, 3], maxval=100, dtype=tf.int32)
tf.gather(x, [0, 2,4], axis=0).shape
TensorShape([3, 32, 32, 3])
上述方式与切片的主要区别是,只能提取连续的图片,而gather方式可以提取不不连续的图片。
2.6.2 tf.gather_nd()
通过 tf.gather_nd() 可以实现对指定采样点的多为坐标来实现采样多个点的目的。假设有10个班,每个班有35个学生,每个学生有8门成绩。我们希望抽查第2个班的第二个同学的所有成绩,第3个班的第3个同学的所有成绩,可以用如下方式实现。
# 10个班,每个班有35个学生,每个学生有8门成绩。
x = tf.random.uniform([10, 35, 8], maxval=100, dtype=tf.int32)
tf.gather_nd(x, [[1, 1], [2, 2]])
<tf.Tensor: shape=(2, 8), dtype=int32, numpy=
array([[ 9, 37, 18, 2, 44, 73, 80, 90],
[53, 77, 64, 31, 53, 56, 95, 30]], dtype=int32)>
上述代码获取了两个学生的全部成绩。
2.6.3 tf.boolean_mask()
除了上边的给定索引号的方式采样数据,还可以通过掩码(Mask)的方式进行采样。
x = tf.random.uniform([4, 32, 8])
tf.boolean_mask(x, [True, False, False, True], axis=0).shape
TensorShape([2, 32, 8])
**掩码长度必须与采样维度的长度一致。**这里的 tf.boolean_mask 的用法其实与 tf.gather 非常类似,只不过一个通过掩码 方式采样,一个直接给出索引号采样。
2.6.4 tf.where
通过 tf.where(cond, a, b) 操作,可以根据cond条件的真假,决定从a或b读取数据。
a = tf.ones([3,3])
b = tf.zeros([3,3])
cond = tf.constant([[True,False,False],[False,True,False],[True,True,False]])
tf.where(cond, a, b)
<tf.Tensor: shape=(3, 3), dtype=float32, numpy=
array([[1., 0., 0.],
[0., 1., 0.],
[1., 1., 0.]], dtype=float32)>
条件规则判断如下:
o
i
=
{
a
i
cond
i
为 True
b
i
cond
i
为 False
\begin{aligned} o_{i}=\left\{\begin{array}{ll} a_{i} & \text { cond }_{i} \text { 为 True } \\ b_{i} & \text { cond }_{i} \text { 为 False } \end{array}\right. \end{aligned}
oi={aibi cond i 为 True cond i 为 False
2.6.5 tf.scatter_nd
***tf.scatter_nd(indices, updates, shape)***可以高效的刷新张量的部分数据,但这个函数只能在全0的白板张量上进行刷新操作。indices为需要刷新的数据索引好,updates为新数据,shape为白板的形状。
indices = tf.constant([[4], [3], [1], [7]])
updates = tf.constant([4.4, 3.3, 1.1, 7.7])
tf.scatter_nd(indices, updates, [8])
<tf.Tensor: shape=(8,), dtype=float32, numpy=array([0. , 1.1, 0. , 3.3, 4.4, 0. , 0. , 7.7], dtype=float32)>
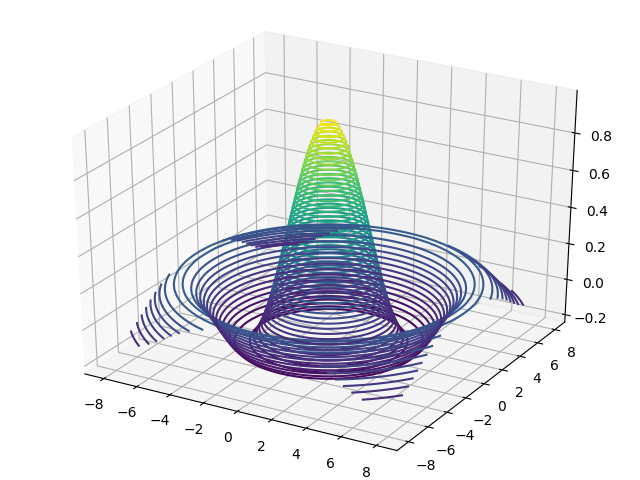
2.6.6 tf.meshgrid
通过 tf.meshgrid 函数可以方便地生成二维网格的采样点坐标,方便可视化等应用场合。
x = tf.linspace(-8.,8,100) # 设置 x 轴的采样点
y = tf.linspace(-8.,8,100) # 设置 y 轴的采样点
x,y = tf.meshgrid(x,y) # 生成网格点,并内部拆分后返回
z = tf.sqrt(x**2+y**2)
z = tf.sin(z)/z # sinc函数实现
import matplotlib
from matplotlib import pyplot as plt
# 导入3D坐标轴支持
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax = Axes3D(fig) # 设置 3D 坐标轴 # 根据网格点绘制 sinc 函数 3D 曲面
ax.contour3D(x.numpy(), y.numpy(), z.numpy(), 50)
plt.show()
2.7 经典数据集加载
tf.keras.datasets 模块提供了常用经典数据集的自动下载、管理、加载 与转换功能。Dataset.from_tensor_slices 可以将训练部分的数据图片 x 和标签 y 都转换成 Dataset 对象。
(x, y), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
train_db = tf.data.Dataset.from_tensor_slices((x, y))
2.7.1 随机打散
train_db = train_db.shuffle(10000)
会将dataset中的x和y打散,并保持对应。
2.7.2 批训练
train_db = train_db.batch(128)
128为batch_size,表示一个批训练中的样本量。
2.7.3 预处理
train_db = train_db.map(preprocess)
其中preprocess为预处理函数,表示对train_db中的每个样本进行preprocess操作。
2.7.4 循环训练
for step, (x,y) in enumerate(train_db):
pass














 1881
1881











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









