










PyTorch常用学习率调整策略
- 1. torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=- 1, verbose=False)
- 2.torch.optim.lr_scheduler.MultiplicativeLR(*optimizer*, *lr_lambda*, *last_epoch=- 1*, *verbose=False*)
- 3. torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=- 1, verbose=False)
- 4. torch.optim.lr_scheduler.MultiStepLR(*optimizer*, *milestones*, *gamma=0.1*, *last_epoch=- 1*, *verbose=False*)
- 5.torch.optim.lr_scheduler.ExponentialLR(*optimizer*, *gamma*, *last_epoch=- 1*, *verbose=False*)
- 6. torch.optim.lr_scheduler.CosineAnnealingLR(*optimizer*, *T_max*, *eta_min=0*, *last_epoch=- 1*, *verbose=False*)
- 7. torch.optim.lr_scheduler.ReduceLROnPlateau(*optimizer*, *mode='min'*, *factor=0.1*, *patience=10*, *threshold=0.0001*, *threshold_mode='rel'*, *cooldown=0*, *min_lr=0*, *eps=1e-08*, *verbose=False*)
神经网络在进行参数优化的过程中,经常需要对学习率进行动态调整。那么PyTorch的torch.optim.lr_scheduler接口提供了很多策略实现动态调整。我们选取一些常用的进行介绍。
1. torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=- 1, verbose=False)
Sets the learning rate of each parameter group to the initial lr times a given function.
这个策略也比较简单,就是每次调用scheduler.step()之后,新的lr会乘以lr_lambda的结果。举例如下,其中network可以换成我们要优化的模型:
optim = torch.optim.Adam(network.parameters(), lr=0.001)
lf = lambda x: ((1 + math.cos(x * math.pi / num_epochs)) / 2) * (1 - 0.2) + 0.2
scheduler = torch.optim.lr_scheduler.LambdaLR(optim, lr_lambda=lf)
for epoch in range(10):
optim.step()
scheduler.step()
print(scheduler.get_last_lr())
输出结果如下:
[0.0009804226065180616]
[0.0009236067977499791]
[0.0008351141009169894]
[0.0007236067977499789]
[0.0006000000000000001]
[0.00047639320225002107]
[0.00036488589908301085]
[0.0002763932022500211]
[0.00021957739348193862]
[0.0002]
可以看到每次调用step之后,lr = lr * lr_lambda(epoch)。
2.torch.optim.lr_scheduler.MultiplicativeLR(optimizer, lr_lambda, last_epoch=- 1, verbose=False)
Multiply the learning rate of each parameter group by the factor given in the specified function.
这个方法跟LambdaLR 类似,都是乘lambda_lr,不同的是MultiplicativeLR是用上一步得到的lr,而LambdaLR 用的始终是初始的lr。
optim = torch.optim.Adam(network.parameters(), lr=0.001)
scheduler = torch.optim.lr_scheduler.MultiplicativeLR(optim, lambda epoch: 0.5)
for epoch in range(10):
optim.step()
scheduler.step()
print(scheduler.get_last_lr())
结果如下:
[0.0005]
[0.00025]
[0.000125]
[6.25e-05]
[3.125e-05]
[1.5625e-05]
[7.8125e-06]
[3.90625e-06]
[1.953125e-06]
[9.765625e-07]
3. torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=- 1, verbose=False)
Decays the learning rate of each parameter group by gamma every step_size epochs.
每间隔step_size个epoch,对lr执行一次乘 gamma操作。
optim = torch.optim.Adam(network.parameters(), lr=0.001)
scheduler = torch.optim.lr_scheduler.StepLR(optim, step_size=5, gamma=0.1)
for i, epoch in enumerate(range(20)):
optim.step()
scheduler.step()
print(i, scheduler.get_last_lr())
结果如下:
0 [0.001]
1 [0.001]
2 [0.001]
3 [0.001]
4 [0.0001]
5 [0.0001]
6 [0.0001]
7 [0.0001]
8 [0.0001]
9 [1e-05]
10 [1e-05]
11 [1e-05]
12 [1e-05]
13 [1e-05]
14 [1.0000000000000002e-06]
15 [1.0000000000000002e-06]
16 [1.0000000000000002e-06]
17 [1.0000000000000002e-06]
18 [1.0000000000000002e-06]
19 [1.0000000000000002e-07]
4. torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=- 1, verbose=False)
Decays the learning rate of each parameter group by gamma once the number of epoch reaches one of the milestones.
StepLR是等间隔的调整lr, 而MultiStepLR是根据指定间隔进行调整,milestones即为自定义的间隔。
optim = torch.optim.Adam(network.parameters(), lr=0.001)
scheduler = torch.optim.lr_scheduler.MultiStepLR(optim, milestones=[2,6], gamma=0.1)
for i, epoch in enumerate(range(10)):
optim.step()
scheduler.step()
print(i, scheduler.get_last_lr())
结果如下,可以看到分别在第二步和第六步进行了两次学习率的调整。
0 [0.001]
1 [0.0001]
2 [0.0001]
3 [0.0001]
4 [0.0001]
5 [1e-05]
6 [1e-05]
7 [1e-05]
8 [1e-05]
9 [1e-05]
5.torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=- 1, verbose=False)
Decays the learning rate of each parameter group by gamma every epoch.
简单讲就是按照如下规则进行lr的更新: lr=lr∗gamma∗∗epoch
6. torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=- 1, verbose=False)
余弦退火策略。以余弦函数为周期,并在每个周期最大值时重新设置学习率。以初始学习率为最大学习率,以2∗Tmax 为周期,在一个周期内先下降,后上升。
其中eta_min指一个周期内的最小学习率。
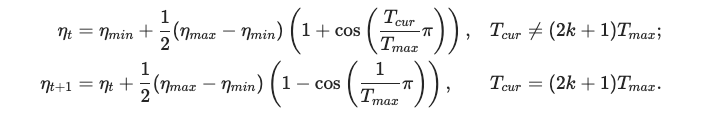
7. torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode=‘min’, factor=0.1, patience=10, threshold=0.0001, threshold_mode=‘rel’, cooldown=0, min_lr=0, eps=1e-08, verbose=False)
这是个超级实用的学习率调整策略。他会监测一个指标,当这个指标不在下降或提高是,进行学习率更新,否则保持学习率不变。每次step需要传入要监测的指标。
Reduce learning rate when a metric has stopped improving.
val_loss = validate(…)
scheduler.step(val_loss)
这里要注意的是step的参数,如果是越小越好,如loss,需要将mode设置成’min’,如果是越大越好的指标,如Accuracy,需要将mode设置成’max’。














 3418
3418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









