






以太坊(Ethereum) 的执行交易性能瓶颈
失踪人口回归了。。已经好久没更新专栏了,之后开始更新的速度应该会上来吧,因为6月底刚从呆了一年的微众银行离职了,回到学校继续划水(划掉)一段时间,比较充裕。经过这段实习,对于以太坊分支的技能树基本点满了,收获很大,而另一方面,最近和一些人合作跑了一个原力eos的超级节点-eosgod(非主网eos),这之后会作为社区运营专栏《原力eos - eosgod 节点》,对应的,也会不断学习eos的代码。这样的话在将来我的区块链上的技能树就可以点满bitcoin,ethereum和eos三个大分支了。Haskell 的学习也在进行之中,积攒力量为后续学习Cardano和Dfinity。
那么今天这篇文章我先跳过系统的介绍ETH(以后会慢慢来),直接总结一下我在公司的第一个成果:ETH的性能瓶颈。这个成果在 ”2018 International Conference on Blockchain“这个会议上发表了,这个会议在西雅图开,本来从公司离职后应该去美国开这个会然后玩一圈的·· 但是结果签证一直被check直到会议都结束了才通过···在这里对川普反华政策表示强烈遣责。。
扯远了,这个成果的论文题目叫做:《A Method to Predict the Performance and Storage of Executing Contract for Ethereum Consortium Blockchain》,之后会收录到Blockchain-ICBC2018 中(当然因为还没正式发表,所以在本文中不会直接把论文贴上来,不过思路是会完整讲清楚的)。我个人认为我写的这篇文章是很水的,其实没什么特别深奥的东西,所以就在这篇文章里面描述出来,给有需要的人帮助。
更新:这篇文章于6月22日发表,链接如下:
A Method to Predict the Performance and Storage of Executing Contract for Ethereum Consortium-Blockchain
前言
这篇论文描述的是对于Ethereum的联盟链的性能分析,但是实际上就是指Ethereum,这里的性能不是说整个区块链网络的性能,而是指代单节点的性能。同理的分析可以分析任何以太坊体系的山寨币(从eth fork出来改改的),以太坊体系的联盟链(例如我司的fisco-bcos 或者迅雷的迅雷链等等)
然后呢,本文会涉及一些基础的Eth的知识,但是没有经过系统学习的话有些地方还是有点难理解吧我猜,我之后的文章会慢慢开始更新关于以太坊体系的知识内容,而本文中就集中关于以太坊性能分析。同时正因为以太坊的结构及以太坊采用的leveldb对随机读写的缺陷,若不考虑多链/侧链等技术,随数据量的增大,我对以太坊未来的性能表示担忧。
本文首发于我自己的知乎专栏 金狗喵喵喵的区块链研习
如需转载,需取得同意并标明出处!
影响以太坊性能的核心
在比特币体系中,在分析比特币tps低下的问题的时候,我们从来都不会去考虑比特币执行脚本的时间,主要是因为btc的脚本是非状态的(UTXO模型),且都十分的短(非图灵完备)。和10分钟的出块及网络同步时间相比,在1M块大小的限制下,这个时间实在是太短暂了。而以太坊是状态模型,且一开始就是打着图灵完备的特点提出的,合约可以写的很复杂。在我司的性能测试中,随着交易量的增大以太坊执行合约性能下降的很快。若是调整为1s一个块的话,这个时间占比就很巨大了(对联盟链),即使是对15s一个块的Ethereum公链,这个时间占比增加的影响相对于btc来说也完全成为了一个不可忽视的因素了。
而以太坊EVM执行合约耗费时间的长短,主要原因除了正常的计算的耗时外,其实另外一块大量的耗时是耗费在了“状态的读取”上,所对应的也就是IO。而以太坊使用的是“世界状态”(World State)去记录以太坊状态的变迁,由于这种独特的数据结构,随着已记录的交易量的增大,每读取一个特定的值产生访问数据库的次数就会以log(n)的次数增加,且这些访问都是离散随机的,而leveldb在面对这样大量的离散随机读取,性能表现十分低下,所以随着交易量增大后,执行交易(合约)的速度会越来越慢,而慢的速率的计算方式在后文给出。
而产生执行速率慢的原因, 就是和”世界状态“相关。
以太坊的世界状态
本文中不特别介绍世界状态的组成和运行机制,这块内容以后会专门独立出一片文章,毕竟这就是以太坊管理状态的核心。这里先介绍讨论文章所需要的知识。
以太坊的本质就是一个由交易触发的状态机变迁,只是这个状态机的所有变迁的”快照“情况都被”世界状态“树记录了下来,使得任何一个快照都可以进行回溯。而这个世界状态树的实现本质上就是和git的实现类似,若本身懂git原理的读者就已经不需要看这一段了。
以太坊实现世界状态树使用的数据结构叫做”the modified Merkle Patricia tree(trie)“(后文简称为MPT),这里不介绍它详细的实现方式与增减节点的步骤,我们从比较宏观的角度来看这个树:
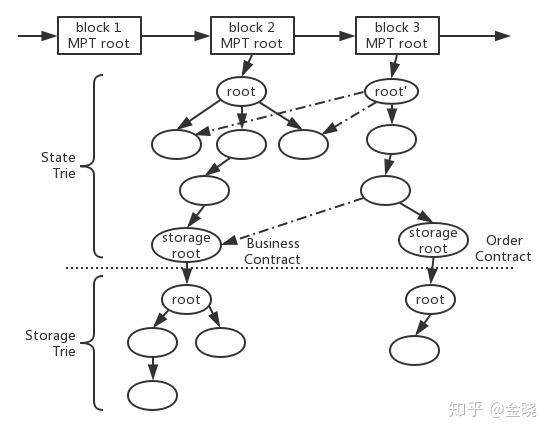
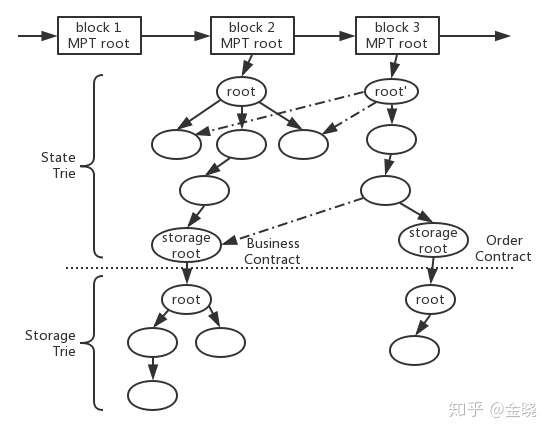
我们截取从block2开始的树开始,假设我们在block2对应的那个状态(也就是在block2这个时间刻的快照)对应的那棵状态树如上图所示。在以太坊的实现中,合约和账户(以太坊的账户体系在以后的文章介绍)的状态存储于世界状态的上层-状态树 State Trie(由MPT实现),也就是合约和账户都是上层状态树的叶子节点。而对于每一个合约来说,合约下面还会挂一棵MPT实现的存储树 Storage Trie用来存储这个合约的数据变化的历史状态。
而我们在这里注意MPT树的性质(也就是git的原理),例如我们只看上半部的StateTrie,当更新叶子节点的数据之后,实际上等于插入了一个新的节点,然后这个新节点到根节点的一系列路径全部重新生成新节点,在生成的新节点会包含之前节点的“引用”,使得新生成的增量可以通过这些引用找到没有修改过的节点。具体的实现和设计不在本文描述,只用理解到每更改一个新的状态,需要从叶子到树根全部生成新的节点就可以。而对于下层的StorageTrie同理,同时要注意,对于以太坊来说,如果动了下层的storagetrie,那么不止引起当前合约的存储树的更新,同样引起这个合约节点的更新,导致上层的StateTrie同样也更新。
那所以问题就很简单了,因为随着交易量的增大,这个树肯定会越来越庞大,那么只需要弄清楚更新(插入)树的次数和树的高度的关系,而又因为每次更新需要从叶子到树根,那么就可以使用交易量估计更新树的次数,推断此时世界状态树大致的高度,从而估计新节点的个数,从而推断出性能/存储相关的信息。
注:这里之所以要用 估计这个词,是因为 在以太坊公链中是难以预估到底哪些合约会被调用,交易量规模会有多大的,所以是 无法准确获得较准确数字的推断,而 在联盟链中,这两方面基本可以预估,所以这个推断就准确的多也有用的多。这也是我的论文是针对联盟链的原因,不过对于公链来说,获得一个大概的预估也足够了
MPT 与 PATRICIA trie (Patricia tree)
MPT本质上是把hash与Patricia tree 结合后产生的新的数据结构,在这里对其他各种科普文直接把以太坊的MPT叫做Merkel Tree和bitcoin的Merkel Tree去类比表示强烈谴责。。这两个数据结构差距巨大,直接这样说是一种误导。
Patricia tree 就是压缩前缀树,因为传统的前缀树每个字符一个节点,存在很多空间浪费的情况,所以提出了把只有连续单字符的节点压缩为同一个节点的数据结构,就是patricia tree。因为MPT树去除hash的属性后其实就是Patricia tree,所以我们这里的问题为Patricia tree 在随机插入中插入数据的数量n与树高的期望(平均值)或者最大值之间的关系,只是MPT比起Patricia trie 在节点生成的过程中考虑其他事情,但是和树高无关。
事实上因为插入的随机性导致节点压缩的随机性,是无法像传统的比如二叉树这类的数据结构能够准确的预测树高的。我一开始考虑的时候是把问题简化为一个求“随机插入字串到一个字串集合,求这个新插入字串与集合已有字串的最长公共前缀长”的问题(具体原因当讨论过MPT的数据结构后就可知了),所幸在检索了很多论文后,已经有前人对这个问题展开了深入的探讨,其中以 Pittel 为首的,从1985年到1999年的一系列论文为探讨随机插入的数量与树高之间的关系为基础,例如“Asymptotical growth of a class of random trees”,“On the height of PATRICIA search tree”等等,随后Luc Devroye在2005年发表的一篇 “Universal Asymptotics for Random Tries and PATRICIA Trees”对前人的很多文章做了总结,并提出的一些关键性的结论。我这里的依据就从这篇论文中来。
在这篇论文里,作者总结提出了对于二叉Patricia tree来说,它的树高的期望,树高的最大值和插入数量之间的关系为:
树高的最大值
而对于MPT树来说,因为在以太坊的实现中是使用的16进制的字符串做key,所以在以太坊中使用的MPT实现的世界状态时一个16叉的patricia tree。那么仿照论文中的推断思路,我们就可以得到16叉的patricia tree 的树高期望和最大树高相关关系为:
当我们拥有这个结论的时候,那核心的问题就已经解决了。接下来要预测性能的时候就是相当于把交易量和MPT的插入量做挂钩,把MPT的树高和新节点的增量,每一个新增节点消耗的性能代价做挂钩就好了。
其实若是只关心以太坊的性能的话要是已经看懂了上面的东西,接下来自己进行推断就可以得到预测了。不过呢下文我会提出一些针对于以太坊联盟链的一些结论,同时给出我们测试的一些结果。从这些结果可以大概预测下以太坊公链的效率
对以太坊联盟链
我的论文之所以要针对的以太坊联盟链,核心原因就是在联盟链中往这个链上部署的合约是用来实现业务逻辑的,是可控的(可分析的),或者是可以构造一些在公链上无法(或者是不恰当)构造的合约。
因为在上文已经提到过了,世界状态可以分成上层的状态树,和下层的存储树两层。在以太坊公链中大部分所谓dapp实际上都是只指代一个合约,即使会使用合约生成合约也不会广泛的使用,否则不好管理。但是对于联盟链来说,这个限制不存在。我们来以下面的例子解释这个问题:
假设现在我的业务逻辑为:我有很多的订单Order,我希望使用以太联盟链来记录我的订单,并处理一些业务逻辑。那么对于Solidity的写法来说,在联盟链的场景下,可以使用不同的写法来完成相同的业务逻辑:
比如第一种:
// 一个新合约
contract Order {
uint256 private order_no;
func Order(uint256 _no) { _no = order_no; }
func doOrder() { ... }
}
contract Business {
uint256 private version;
func createOrder(uint256 _no) returns(address) {
Order o = new Order(_no); // 使用合约创建合约,并把合约地址返回,没有在合约内部存储,而是使用一个新合约保存数据
o.doOrder();
return o;
}
}
第二种:
contract Business {
struct Order {} // a struct data 不创建合约,使用struct结构体来保存Order,这个是合约内部的数据
mapping (uint256 => Order) orders;
func createOrder(uint256 _no) {
Order o = Order();
doOrder(o)
orders[no] = o;
}
func doOrder(Order o) { … }
}以上两种写法的合约都可以达到相同的目的,但是由于合约树和存储树的关系,会使得Order数据分布的方式不同。对于合约/账户来说,只会分布到状态树上,而对于合约的数据则会分布到这个合约下的存储树中。
所以对于相同的业务逻辑,我们可以改变合约的写法得到下面这些设计的模型:
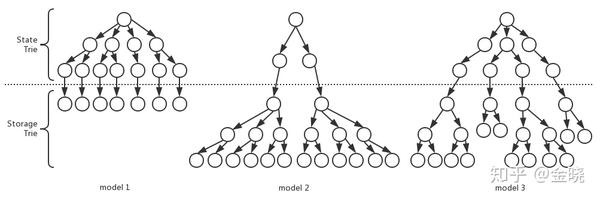
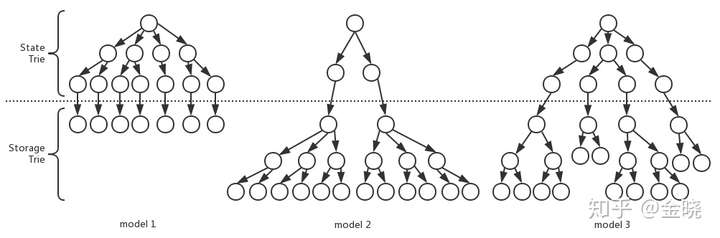
其中model1就是对应的第一种合约的写法,而model2对应的就是第二种合约的写法。而model3实际上就是考虑一些取舍,把数据能够既分布到状态树上又分布到存储树上。
那么假如仅针对第一种model1的写法来说,当我们已知部署的合约和未来的可能的交易量大小的时候,就可以推断出未来的性能和存储占据的大小了。
简单来说就是通过分析合约,获得一笔交易在合约中需要执行sload和sstore指令的次数,那么就可以得到当第n笔交易的时候已经发生了多少次sload和sstore指令,那么就可以根据上面的公式获得此时状态树的树高,从而获得新节点的个数从而预计耗费的时间和存储增量。
实验数据
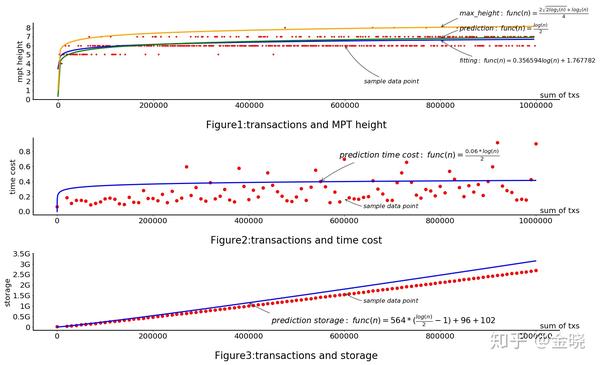
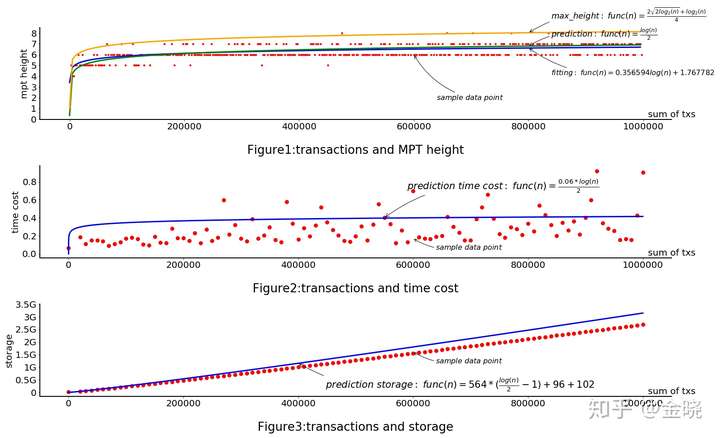
上图就是针对model1使用实验测试得到的数据。先抛开后两个,我们可以看到根据公式得到的结果,执行的交易数和状态树的树高基本是吻合的。所以这个思路是没问题。
但是针对后面两个要详细说明,因为在实际实现中,eth在执行合约的时候会有各种缓存,这里的实验是等价于剔除缓存后的结论,真实情况下要考虑实现上缓存的问题。然后对于存储来说,最终存储下来的是经过leveldb的压缩,实际的存储空间应该会比要存进去的数量小1/2~1/3左右。
除此之外,要提一个和leveldb相关相当严重的问题:
对于图2来说,我使用的是一个leveldb读取的平均值来绘制的图线,但是实际上leveldb的表现要比平均的差。问题在于leveldb是key-value数据库,而对于世界状态树来说,为了读取一个数据,实际上会产生树高次数的对数据库的访问,而且必须是读出上一个数据后才能知道下一个数据应该读什么。没法像传统的数据库一样select * from xxx一次批量的读出来减少数据库的io。而另一方面,对于leveldb来说,离散的读取会表现得很差,对于连续的读取表现非常好,而不幸的是,对于MPT树来说,因为所有的节点都是靠hash去查找,这些hash是完全离散的,所以当数据量一庞大了之后,leveldb的表现就显的相当差劲了:
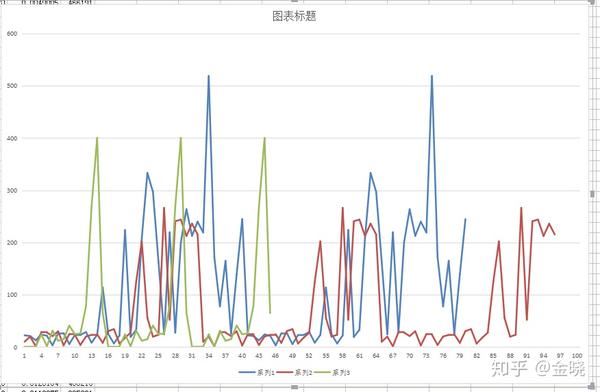
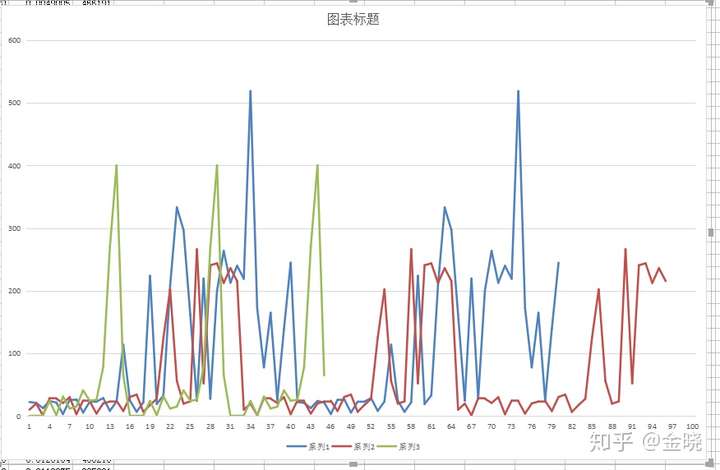
大概会像这个样子,也就是会出现很多的“毛刺”。
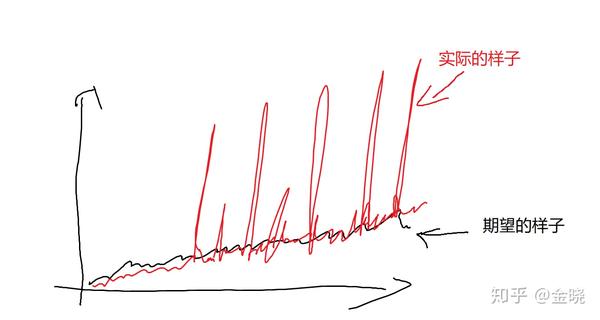

也就是说随着数据量增大,那么读取的时间增加这点是完全能够接受的,也就是上图“期望的样子”,但是在实际上leveldb加上世界状态的设计后,真实的leveldb的表现随着数据量的增加后表现得其实是像上图红色线的“实际的样子”。这些“毛刺”读取的时间是平均读取时间的好几倍甚至是好几十倍,瞬间拖慢了执行速度,而这些“毛刺”的出现又是完全无法预料的。所以当数据量增大后,会发现交易执行的效率急剧下降,而且下降的方式还是有时快有时慢。这会导致出块的效率变得很不稳定,特别是当出块时间缩短到很短的时候,比如是1s(我司区块链的默认设置),这个影响就相当大了,导致出块变得很不稳定,总是不按规律的超时。
这里给出我们的一个大概的数据:
对于一个统一的合约,从空白的链开始执行交易,当达到千万条级别的时候:
- 执行效率:一开始假设能在200-300tps左右,千万条交易后大概就只能到50tps左右
- 存储空间:假设一条交易大概是100B大小,最后实际的存储空间达到了700G,也就是说数据与存储的转化比达到了1/700左右。
对于后一条存储的占据,实际上在上文的讨论我们可以发现,最终的数据实际上是存储到叶子节点上的,但是为了维护追溯历史的功能,需要叶子到树根一系列的节点,而且随着数据量的增大,需要维护的节点就越多。而且这些节点和叶子节点的大小相比并小不了多少,甚至还更大。所以造成了为了追溯历史,需要付出比原来存储大好多倍的存储代价。
这也就是为什么现在以太坊公网的存储空间会占据这么大的原因,相比较于比特币,同样是存储世界上所有的交易,目前比特币也就是达到了170G左右,而以太坊比比特币运行的晚,但是它的存储空间已经后来居上,甚至在2017年(好像是,记不住了)就已经超过了比特币的存储空间,把比特币甩在了身后--。
以上就是我对以太坊公网在交易量变得庞大以后对其未来的性能表示担忧的原因。
我司的fisco-bcos一直在这方面很困扰,虽然我们都承认“世界状态”的这个设计很是精妙,让人叹服,但是架不住它在工程上表现得差劲。所以为了克服这个问题,微众银行的区块链高级架构师莫楠开创性的提出了“分布式存储的概念”,从底层上抛弃了“世界状态”的设计,从另一个角度去解决以太坊的存储/性能问题。这种方式从合约到底层上一并修改,引导用户更改一些使用合约的方式,从而适应分布式存储的概念,从而克服以太坊的这个核心问题。该部分将会在2018年8月份开源,目前已经在某公司的产品中上线。详情请访问fisco-bcos的github网址。
更新:
当前该部分已经全部开源,详情请见链接:
FISCO BCOS 2.0原理解析篇2: 分布式存储架构设计















 9456
9456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









