







最近在做 NER 任务的时候,需要处理最长为 1024 个字符的文本,BERT 模型最长的位置编码是 512 个字符,超过512的部分没有位置编码可以用了
处理措施:
- 将bert的位置编码认为修改成(1*1024),前512维使用原始的 (1*512)初始化,后512维随机初始化
- 将bert的位置编码认为修改成(1*1024),前512维使用原始的 (1*512)初始化,后512维依旧使用原始的(1*512)进行初始化
- 苏剑林:层次分解位置编码,让BERT可以处理超长文本 - 科学空间|Scientific Spaces
- 使用longformer
- 对文本进行切割
下面介绍如何强制改变位置编码
采用1,2所表述的方式,强制改变位置编码,由512 扩展到 1024,具需要在 modeling_bert.py 的 BertEmbeddings class中,新声明一个 (1*1024)的position_embedding,并且将forward 函数中的 position_embedding替换成新声明的这个位置编码。
在load 完模型之后,会警告说,新的位置编码并不在原始的模型参数中,所以是随机初始化的,这里注意,原始的位置编码还是要保留的,用于将原始的位置编码加载进来。当模型加载结束后,我们将原始的 位置编码和新的位置编码单独取出,并用原始的位置编码替换掉新位置编码的部分参数(前 512 维)。
1024 中后一半的位置编码同样使用 原始的 512 维进行初始化,这样就相当于将两个 512 的位置编码拼接到了一起。
用transformer库 具体操作
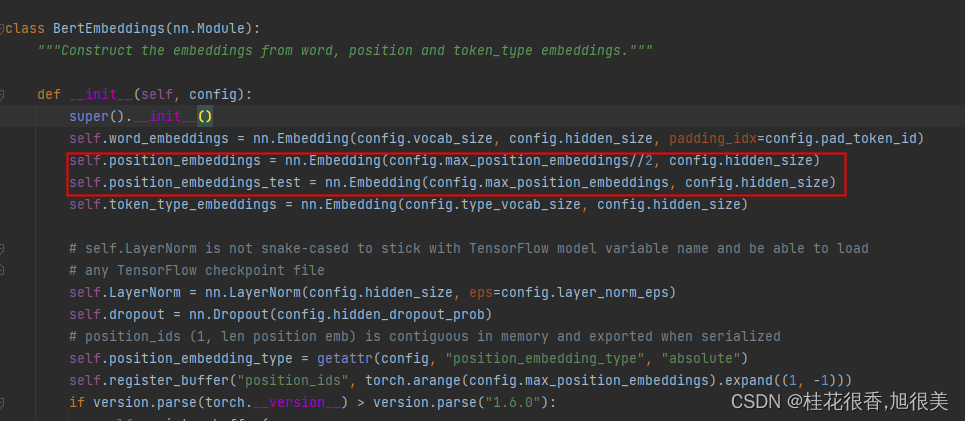
1,修改 /home/wws/miniconda3/envs/ner/lib/python3.7/site-packages/transformers/models/bert/modeling_bert.py (大概在 172行)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
在下面添加一个
self.position_embeddings_test = nn.Embedding(config.max_position_embeddings, config.hidden_size)
再把原来的position 修改一下
self.position_embeddings = nn.Embedding(config.max_position_embeddings//2, config.hidden_size)
区别在于第一个参数 //2
然后在 forward 函数里面 将原来的 position_embeddings 替换成 position_embeddings_test
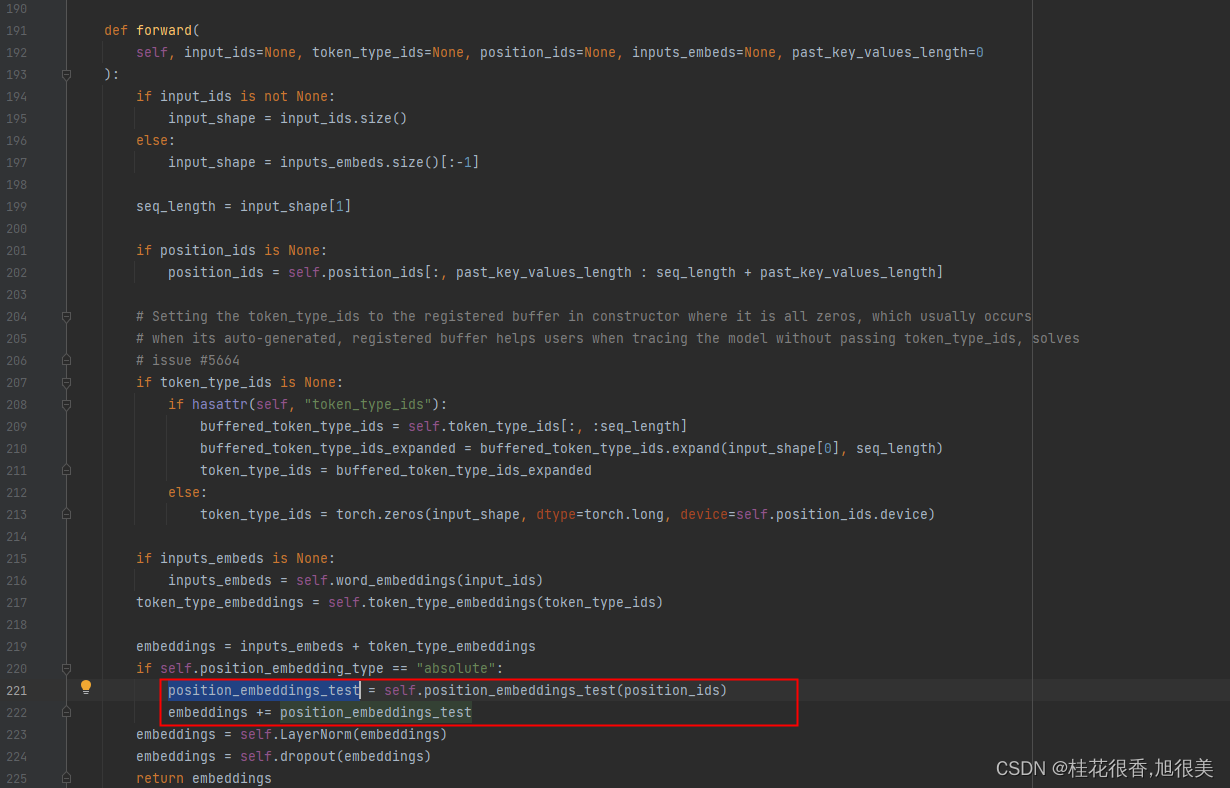
训练的代码中,加载完模型参数后添加
add_position_embeddings = torch.tensor(model.bert.embeddings.position_embeddings_test.weight)
add_position_embeddings[:512] = torch.tensor(model.bert.embeddings.position_embeddings.weight)
如果后半部分也是用 原始的位置编码初始化那就吧下面的代码也加上
add_position_embeddings[512:] = torch.tensor(model.bert.embeddings.position_embeddings.weight)
最后将改好的位置编码放回去
model.bert.embeddings.position_embeddings_test.weight = nn.Parameter(add_position_embeddings)
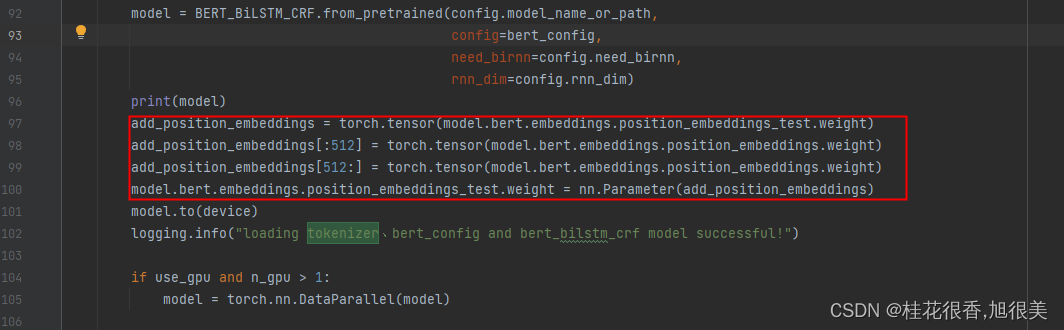
但是运行时提示用sourceTensor.clone().detach() 或者sourceTensor.clone().detach().requires_grad_(True) 代替上面的torch.tensor(**)

现在position_embeddings 长度就可以使1024了
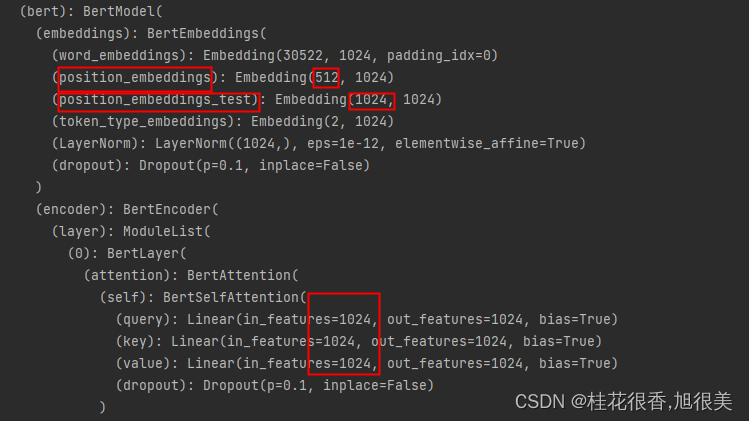
后面接nn.linear和crf就可以做ner了
PS:
BertConfig {
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 1024,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1",
"2": "LABEL_2",
"3": "LABEL_3",
"4": "LABEL_4",
"5": "LABEL_5",
"6": "LABEL_6",
"7": "LABEL_7",
"8": "LABEL_8",
"9": "LABEL_9",
"10": "LABEL_10",
"11": "LABEL_11",
"12": "LABEL_12",
"13": "LABEL_13",
"14": "LABEL_14"
},
"initializer_range": 0.02,
"intermediate_size": 4096,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1,
"LABEL_10": 10,
"LABEL_11": 11,
"LABEL_12": 12,
"LABEL_13": 13,
"LABEL_14": 14,
"LABEL_2": 2,
"LABEL_3": 3,
"LABEL_4": 4,
"LABEL_5": 5,
"LABEL_6": 6,
"LABEL_7": 7,
"LABEL_8": 8,
"LABEL_9": 9
},
"layer_norm_eps": 1e-12,
"max_position_embeddings": 1024,
"model_type": "bert",
"num_attention_heads": 16,
"num_hidden_layers": 24,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"transformers_version": "4.9.0",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 30522
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









