









1. 介绍
光学字符识别(Optical Charater Recognition, OCR) 是针对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。
2. OCR思路
- 文字检测:解决的问题是哪里有文字,文字的范围有多少。
- 文字识别:对定位好的文字区域进行识别,主要解决问题是每个文字是什么,将图像中的文字区域进行转化为字符信息。
2.1 图像预处理
动机
常见图片存在文字布局多样,扭曲,模糊,光线不均等问题,如果不做处理,直接使用,容易丢失大量有效信息,从而导致识别效果低下。
常用图像处理
- 几何变形(透视、扭曲、旋转等)
- 畸形矫正
- 去除模糊
- 图像增强
- 光线矫正
图像预处理方法
传统方法
- 介绍:基于数字图像处理和传统机器学习等方法对图像进行处理和特征提取
- 常用方法: HoG
- 优点:有利于增强简单场景的文本信息
- 缺点:对于图像模糊、扭曲等问题鲁棒性很差,对于复杂场景泛化能力不佳
深度学习方法
- 介绍:基于深度学习的神经网络作为特征提取手段
- 常用方法:基于CNN的神经网络
- 优点:CNN强大的学习能力,配合大量的数据可以增强特征提取的鲁棒性,面临模糊、扭曲、畸变、复杂背景和光线不清等图像问题均可以变现良好的鲁棒性
- 缺点:需要大量标注数据
2.2 文字检测
- 动机:常见的图片不仅包含有用的文字,还存在大量的背景信息,这些背景信息对于模型容易存在误导作用;
- 介绍:文字检测即检测文本的所在位置和范围及其布局,即识别哪里有文字,文字的范围有多大等问题
- 预处理方法:Faster R-CNN、FCN、RRPN、Text Boxes、DMPNet、CTPN、SegLink等
2.3 文本识别
- 动机:最然知道图像中文字的具体位置,但是如何知道这些文字是什么呢?
- 介绍:在文本检测的基础上,对文本内容进行识别,将图像中的文本信息转化为文本信息;
- 图像预处理方法:CNN+Softmax、CNN+RNN+CTC、CNN+RNN+Attention等;
3. OCR 处理流程
3.1 传统算法(积分投影、腐蚀膨胀、旋转等)
标准处理流程:图像预处理、文本行检测、单字符检测、单字符识别、后处理。

图像预处理主要针对图像的成像问题进行修正,包括几何变换(透视、扭曲、旋转等),去模糊、光线矫正等;文本检测通常使用连通域、滑动窗口两个方向;字符识别算法主要包括图像分类、模板匹配等
3.2 深度学习OCR
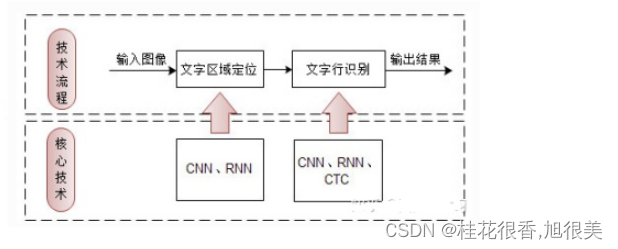
3.2.1 思路
- 首先检测图像中的文本行
- 接着进行文本识别
4. 开源项目
- Tesseract
- PaddleOCR
- EasyOCR
- chineseocr
- chineseocr_lite
- TrWebOCR
- cnocr
- hn_ocr
4.1 Tesseract (谷歌开发并开源 \ python)
优势:
- github上的star非常多,项目非常活跃
- 识别语言和文字非常多
劣势:
- 不是专门针对中文场景
- 相关文档抓要是英文
- 学习成本高
- 源码较多,并且部分是C++,学习难度大
4.2 PaddleOCR (百度开源的中文OCR)
优势:
- star非常多,项目非常活跃
- 模型只针对中文进行训练
- 相关中文文档齐全
- 识别精度比较高
劣势: - 目前使用的训练模型是基于百度自己的PaddlePaddle框架,对于小公司来说不主流(对比于tf与pytorch),所使用的深度学习框架为后续其他深度学习无法做很好的铺垫
- 项目整体比较复杂,学习成本较高
4.3 EasyOCR (pyton \ 支持80多种语言)
优势:
- star也很多,但最近不是很活跃
- 支持80多种语言
- 识别的精度尚可
劣势:
- 从官方页面体验来说识别速度较慢
- 识别的文字种类多,学习难度较高
- 相关文档基于英文,学习难度大
4.4 chineseocr
优势:
- star也比较多
- 专门针对中文进行学习和训练的模型
- 相关文档比较多,上手比较容易
劣势:
- 没有大厂背书,有些bug
- 对于复杂场景下效果不佳
- 模型是现成的,如果要新训练模型难度比较高
4.5 chineseocr_lite
优势:
- star比较多
- 专门针对中文进行学习和训练
- 相关中文文档比较多,上手容易
- 轻量级,部署比较方便
4.6 TrWebOCR ( -基于开源项目Tr 构建)
优势:
- 部署简单
- 使用简单
- 有对应的web页面,测试方便
- 有对应的http接口,方便调用
劣势:
- 核心模块不开源,无法进行再学习
- 无法进行后续训练
- 必须联网才能使用
- 精度识别一般
- 项目不是很活跃
4.7 cnocr
python3下的文字识别工具包,支持简体中文、繁体中文(部分模型)、英文和数字的常见字符识别,支持竖排文字的识别。自带20+个训练好的模型,适用于不同的场景,安装后即可直接使用。同时,CnOCR也提供简单的训练命令供使用者训练自己的模型。
优势:
- 使用简单
- 文档齐全
- 代码全部开源,可以进行修改
- 预定义的模型较多
- 便于学习和模型重新训练
劣势:
- 精确度不高
- 没有对应的web界面和接口
- 需要配合cnstd 进行使用
4.8 hn_ocr
惠农网基于cnstd + cnocr + tronado构建的web服务,提供了http接口,便于微服务体系中其他服务调用,也便于前端页面进行调用。
优势:
- 中文检测(基于cnstd)
- 中文识别(基于cnocr)
- web接口(基于 tronado)
- 返回的文字按坐标,从上至下,从左往右
- 返回检测文字的坐标















 7490
7490











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









