









1. 创建新的conda环境
# 在命令行输入以下命令,创建名为paddle_env的环境
# 此处为加速下载,使用清华源
conda create --name paddle_env python=3.8 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ # 这是一行命令
2. 激活刚创建的conda环境
# 激活paddle_env环境
conda activate paddle_env
# 查看当前python的位置
where python
3. 安装PaddlePaddle
1. CUDA9或CUDA10
python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
2. CPU
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
4. 安装PaddleOCR whl包
pip install "paddleocr>=2.0.1" # 推荐使用2.0.1+版本
5. 代码使用
paddleocr默认使用PP-OCRv4模型,具体版本说明如下:
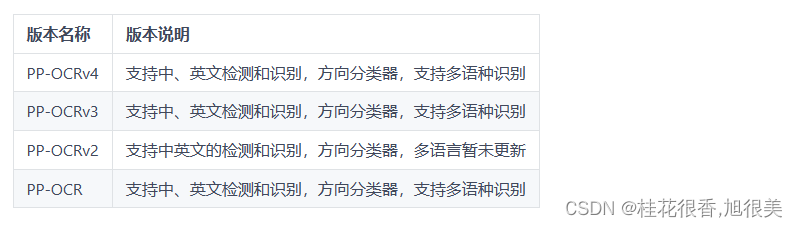
如需新增自己训练的模型,可以在paddleocr中增加模型链接和字段,重新编译即可。
5.1 检测+方向分类器+识别全流程
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持中英文、英文、法语、德语、韩语、日语,可以通过修改lang参数进行切换
# 参数依次为`ch`, `en`, `french`, `german`, `korean`, `japan`。
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
img_path = 'PaddleOCR/doc/imgs/11.jpg'
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
# 显示结果
from PIL import Image
result = result[0]
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='/path/to/PaddleOCR/doc/fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
结果是一个list,每个item包含了文本框,文字和识别置信度
[[[24.0, 36.0], [304.0, 34.0], [304.0, 72.0], [24.0, 74.0]], ['纯臻营养护发素', 0.964739]]
[[[24.0, 80.0], [172.0, 80.0], [172.0, 104.0], [24.0, 104.0]], ['产品信息/参数', 0.98069626]]
[[[24.0, 109.0], [333.0, 109.0], [333.0, 136.0], [24.0, 136.0]], ['(45元/每公斤,100公斤起订)', 0.9676722]]
......
结果可视化

5.2 检测+识别
from paddleocr import PaddleOCR, draw_ocr
ocr = PaddleOCR() # need to run only once to download and load model into memory
img_path = 'PaddleOCR/doc/imgs/11.jpg'
result = ocr.ocr(img_path, cls=False)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
# 显示结果
from PIL import Image
result = result[0]
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='/path/to/PaddleOCR/doc/fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
结果是一个list,每个item包含了文本框,文字和识别置信度
[[[24.0, 36.0], [304.0, 34.0], [304.0, 72.0], [24.0, 74.0]], ['纯臻营养护发素', 0.964739]]
[[[24.0, 80.0], [172.0, 80.0], [172.0, 104.0], [24.0, 104.0]], ['产品信息/参数', 0.98069626]]
[[[24.0, 109.0], [333.0, 109.0], [333.0, 136.0], [24.0, 136.0]], ['(45元/每公斤,100公斤起订)', 0.9676722]]
......
结果可视化

5.3 方向分类器+识别
from paddleocr import PaddleOCR
ocr = PaddleOCR(use_angle_cls=True) # need to run only once to download and load model into memory
img_path = 'PaddleOCR/doc/imgs_words/ch/word_1.jpg'
result = ocr.ocr(img_path, det=False, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
结果是一个list,每个item只包含识别结果和识别置信度
['韩国小馆', 0.9907421]
5.4 单独执行检测
from paddleocr import PaddleOCR, draw_ocr
ocr = PaddleOCR() # need to run only once to download and load model into memory
img_path = 'PaddleOCR/doc/imgs/11.jpg'
result = ocr.ocr(img_path, rec=False)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
# 显示结果
from PIL import Image
result = result[0]
image = Image.open(img_path).convert('RGB')
im_show = draw_ocr(image, result, txts=None, scores=None, font_path='/path/to/PaddleOCR/doc/fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
结果是一个list,每个item只包含文本框
[[26.0, 457.0], [137.0, 457.0], [137.0, 477.0], [26.0, 477.0]]
[[25.0, 425.0], [372.0, 425.0], [372.0, 448.0], [25.0, 448.0]]
[[128.0, 397.0], [273.0, 397.0], [273.0, 414.0], [128.0, 414.0]]
......
结果可视化

5.5 单独执行识别
from paddleocr import PaddleOCR
ocr = PaddleOCR() # need to run only once to download and load model into memory
img_path = 'PaddleOCR/doc/imgs_words/ch/word_1.jpg'
result = ocr.ocr(img_path, det=False)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
结果是一个list,每个item只包含识别结果和识别置信度
['韩国小馆', 0.9907421]
5.6 单独执行方向分类器
from paddleocr import PaddleOCR
ocr = PaddleOCR(use_angle_cls=True) # need to run only once to download and load model into memory
img_path = 'PaddleOCR/doc/imgs_words/ch/word_1.jpg'
result = ocr.ocr(img_path, det=False, rec=False, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
结果是一个list,每个item只包含分类结果和分类置信度
['0', 0.9999924]
6. 自定义模型
当内置模型无法满足需求时,需要使用到自己训练的模型。 首先,参照模型导出将检测、分类和识别模型转换为inference模型,然后按照如下方式使用
6.1 代码使用
from paddleocr import PaddleOCR, draw_ocr
# 模型路径下必须含有model和params文件
ocr = PaddleOCR(det_model_dir='{your_det_model_dir}', rec_model_dir='{your_rec_model_dir}',
rec_char_dict_path='{your_rec_char_dict_path}', cls_model_dir='{your_cls_model_dir}',
use_angle_cls=True)
img_path = 'PaddleOCR/doc/imgs/11.jpg'
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
# 显示结果
from PIL import Image
result = result[0]
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='/path/to/PaddleOCR/doc/fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
6.2 通过命令行使用
paddleocr --image_dir PaddleOCR/doc/imgs/11.jpg --det_model_dir {your_det_model_dir} --rec_model_dir {your_rec_model_dir} --rec_char_dict_path {your_rec_char_dict_path} --cls_model_dir {your_cls_model_dir} --use_angle_cls true
7. 使用网络图片或者numpy数组作为输入
7.1 网络图片
7.1.1
from paddleocr import PaddleOCR, draw_ocr, download_with_progressbar
# Paddleocr目前支持中英文、英文、法语、德语、韩语、日语,可以通过修改lang参数进行切换
# 参数依次为`ch`, `en`, `french`, `german`, `korean`, `japan`。
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
img_path = 'http://n.sinaimg.cn/ent/transform/w630h933/20171222/o111-fypvuqf1838418.jpg'
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
# 显示结果
from PIL import Image
result = result[0]
download_with_progressbar(img_path, 'tmp.jpg')
image = Image.open('tmp.jpg').convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='/path/to/PaddleOCR/doc/fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
7.1.2 命令行模式
paddleocr --image_dir http://n.sinaimg.cn/ent/transform/w630h933/20171222/o111-fypvuqf1838418.jpg --use_angle_cls=true
7.2 numpy数组
import cv2
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持中英文、英文、法语、德语、韩语、日语,可以通过修改lang参数进行切换
# 参数依次为`ch`, `en`, `french`, `german`, `korean`, `japan`。
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
img_path = 'PaddleOCR/doc/imgs/11.jpg'
img = cv2.imread(img_path)
# img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY), 如果你自己训练的模型支持灰度图,可以将这句话的注释取消
result = ocr.ocr(img, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
# 显示结果
from PIL import Image
result = result[0]
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='/path/to/PaddleOCR/doc/fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
8. PDF文件作为输入
8.1 命令行模式
可以通过指定参数page_num来控制推理前面几页,默认为0,表示推理所有页。
paddleocr --image_dir ./xxx.pdf --use_angle_cls true --use_gpu false --page_num 2
8.2 代码使用
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, lang="ch", page_num=2) # need to run only once to download and load model into memory
img_path = './xxx.pdf'
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
# 显示结果
import fitz
from PIL import Image
import cv2
import numpy as np
imgs = []
with fitz.open(img_path) as pdf:
for pg in range(0, pdf.pageCount):
page = pdf[pg]
mat = fitz.Matrix(2, 2)
pm = page.getPixmap(matrix=mat, alpha=False)
# if width or height > 2000 pixels, don't enlarge the image
if pm.width > 2000 or pm.height > 2000:
pm = page.getPixmap(matrix=fitz.Matrix(1, 1), alpha=False)
img = Image.frombytes("RGB", [pm.width, pm.height], pm.samples)
img = cv2.cvtColor(np.array(img), cv2.COLOR_RGB2BGR)
imgs.append(img)
for idx in range(len(result)):
res = result[idx]
image = imgs[idx]
boxes = [line[0] for line in res]
txts = [line[1][0] for line in res]
scores = [line[1][1] for line in res]
im_show = draw_ocr(image, boxes, txts, scores, font_path='doc/fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result_page_{}.jpg'.format(idx))
参数说明



参考:
版面分析–OCR神奇PAddleOCR
PaddlePaddle / PaddleOCR
PaddleOCR 运行环境准备
PaddleOCR 快速开始
版面分析–OCR开源项目记录(备用)
paddleocr package使用说明
通过OCR实现验证码识别
基于图片相似度的图片搜索















 1492
1492











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









