







 本文深入探讨了Hebb学习规则和Hopfield神经网络,阐述了它们在神经网络中的作用和关联。通过实例展示了如何用Python实现离散型Hopfield网络进行图像的记忆与联想恢复,揭示了网络稳定性、吸引子和能量函数等关键概念。实验表明,Hopfield网络在单一模式记忆时能有效进行联想,但在多模式记忆时可能出现联想错误或陷入局部极小值。
本文深入探讨了Hebb学习规则和Hopfield神经网络,阐述了它们在神经网络中的作用和关联。通过实例展示了如何用Python实现离散型Hopfield网络进行图像的记忆与联想恢复,揭示了网络稳定性、吸引子和能量函数等关键概念。实验表明,Hopfield网络在单一模式记忆时能有效进行联想,但在多模式记忆时可能出现联想错误或陷入局部极小值。
前言
本文简单介绍了一下Hebb学习规则和Hopfield神经网络,并讨论了二者的特性和意义,以及它们之间的联系。最后代码实现了一个简单Hopfield网络,能够记忆并联想回忆出一张图片。
Hebb学习规则
Hebb学习规则是一种神经网络连接权值的调整方法,它基于心理学家D.O.Hebb提出的“突触修正”假设。该假设指出当该突触前神经元和后神经元同时兴奋或抑制时,则该突触连接增强;反过来,若同一时刻两者状态相反,则突触连接减弱。神经元模型以及具体的调整公式如下:

Δ
W
j
=
η
f
(
W
j
T
X
)
X
\Delta W_j = \eta f (W_j^T X)X
ΔWj=ηf(WjTX)X
其中,
η
\eta
η为学习率,
f
(
W
j
T
X
)
f (W_j^T X)
f(WjTX)为神经元 j 的输出,
f
(
)
f()
f()为激活函数,一般为
s
g
n
(
)
sgn()
sgn()函数,即大于某一阈值输出值为1,否则输出值为-1。
使用这个规则更新突触连接权值后,当突触前神经元再次发出同样的刺激时,后神经元更容易兴奋或抑制。具体可参考巴甫洛夫的条件反射实验,通过同时刺激狗相应的听觉和控制分泌唾液腺体的神经元,人为地增强了两者的连接。通过重复刺激,最后就在两个原本毫不相干的神经元中建立了很强的突触连接,制造出了全新地条件反射。
Hopfield神经网络
Hopfield网络是一种单层反馈神经网络,具有联想记忆的功能。在使用时通过灌输式学习的方法对其进行训练,即完成记忆,然后在推理阶段通过反馈机制对网络状态进行更新,最后就可以实现联想的功能。Hopfield神经网络可分为离散型(DHNN)和连续型(CHNN)两种,这里主要介绍DHNN。
离散型Hopfield神经网络
离散型Hopfield神经网络(DHNN)的状态是随其迭代的轮数而改变的,所以其状态在时间轴上是离散的,这与下面的CHNN不同。其网络结构如下:

可以发现,每个神经元的输出都将作为所有神经元的输入,即当下任何一个神经元的状态(输出)都将影响所有神经元的下一个状态。有时候DHNN中的神经元没有自反馈,这在具体实现时直接将权重矩阵中对角线上的元素置为0即可。在实际测试中发现,对简单任务有无自反馈连接并不影响DHNN的功能和最终结果。
每个神经元的输出有1和-1两种情况,分别对应着神经元的兴奋和抑制状态,而整个网络的状态由所有神经元的状态决定,因此该网络总共就有
2
n
2^n
2n种状态,其中
n
n
n为神经元个数。
DHNN功能的实现分为两个阶段:记忆阶段和联想阶段。在记忆阶段输入想要记忆的模式,通过特定的规则调整连接权值,然后在联想阶段给出相似的输入,网络通过迭代能够逐渐收敛于已经记忆的模式,就实现了联想的功能。
DHNN的稳定性
由网络工作状态的分析可知,DHNN实质上是一个离散的非线性动力学系统。网络从初态 X ( 0 ) X(0) X(0)开始,若经有限次迭代后,其状态不再发生变化,即 X ( t + 1 ) = X ( t ) X(t+1) = X(t) X(t+1)=X(t),则称该网络是稳定的。
吸引子和能量函数
网络达到稳定时的状态
X
X
X,称为网络的吸引子。一个动力学系统的最终行为是由它的吸引子决定的。吸引子即为DHNN实现信息存储与联想回忆功能的基础。若把需要记忆的样本信息存储于网络不同的吸引子,当输入含有部分记忆信息的样本时,网络的演变过程便是从部分信息寻找全部信息,即联想回忆的过程。DHNN中有个能量函数的概念,公式如下:
E
=
−
1
2
X
T
W
X
+
X
T
T
E = - \frac{1}{2}X^TWX + X^TT
E=−21XTWX+XTT
其中
T
T
T为每个神经元的激活阈值,简单起见,在后续的实验中直接全部设为0。 随着迭代轮数的增加,能量函数最终会收敛于最小值,即吸引子。 注意,这里迭代过程中改变的是网络的状态,即每个神经元的输出(1或-1),并不是权值矩阵。权值矩阵在记忆阶段已经设置好了,之后就不需要调整了。并且能量函数的最小值是在状态空间中寻找的,并不是在权值空间,这与Back-propagation算法中寻找损失函数的最小值不同。
DHNN在联想阶段状态的调整方式有两种:同步式和异步式。同步式即在一次迭代中,调整所有神经元的输出状态;异步式则是在一次迭代中,随机或按一定顺序只调整一个神经元的状态。同步式调整计算速度快,能够充分发挥硬件平台的并行计算能力,但保证网络能够收敛到吸引子的条件会更加苛刻,异步式调整则正好相反。
每个DHNN记忆的容量有限,当只记忆一个模式时,若全值矩阵满足一定条件,联想阶段就可以保证网络能够收敛到所记忆的模式。但当需要记忆多个模式时,若记忆模式不两两正交,则在设置权值矩阵时每个样本之间会产生干扰,具体表现为在状态空间的能量函数可能会出现局部极小值,这就会导致在联想阶段网络无法收敛到吸引子。
对于记忆了多个模式的DHNN,在联想阶段网络最终收敛到哪一个吸引子不仅与其初始状态有关,也与神经元状态调整的顺序(即整个系统状态改变的路径)有关。
网络权值的设计与Hebb规则
权值矩阵的设置公式如下:
W
=
∑
p
=
1
p
η
[
X
p
(
X
p
)
T
]
W = \sum_{p = 1}^{p} \eta[X^p(X^p)^T]
W=p=1∑pη[Xp(Xp)T]
或将神经元的自连权值设为0,取消自反馈连接:
W
=
∑
p
=
1
p
η
[
X
p
(
X
p
)
T
−
I
]
W = \sum_{p = 1}^{p} \eta[X^p(X^p)^T - I]
W=p=1∑pη[Xp(Xp)T−I]
式中 p p p为需要记忆的模式的数量, η \eta η为学习率。这个权值设置方法其实并不符合上面公式中Hebb学习规则的定义,因为 Δ W \Delta W ΔW并不是网络输入与输出的乘积。但它所达到的效果与Hebb规则是一致的,都能让在记忆阶段输入的样本信息保留在权值矩阵中,并在之后的联想阶段输入同样的样本时,每个神经元更容易兴奋或抑制,即整个网络更容易变成记忆的状态。只不过在这个应用中我们希望DHNN直接输出输入数据,因此上述公式中将 f ( W T X ) f(W^TX) f(WTX)变为 X X X。
连续型Hopfield神经网络
连续型Hopfield神经网络(CHNN)的基本结构与DHNN相似,但CHNN中个输入输出量均是随时间连续变化的模拟量,一般使用常系数微分方程或模拟电子线路来描述。具体实现涉及到硬件电路方面的设计与分析,这里就不再展开了。
代码实现与实验结果
接下来实现了一个简单的DHNN,并对其进行了一些简单的测试。网络的功能很简单,就是在记忆阶段输入一张或几张图片,然后将其遮盖住一部分后再输入网络,让网络在联想阶段恢复原图。
代码实现
#创建一个DHNN类
class DHNN():
def __init__(self, n, iter):
self.n = n #神经元个数
self.iter = iter #联想阶段迭代次数
def memory(self, X, epoch=10, lr=0.1): #记忆
self.W = np.zeros((self.n, self.n))
for _ in range(epoch):
for x in X:
x = np.reshape(x, (self.n, 1))
xT = np.reshape(x, (1, self.n))
# self.W += lr * (x * xT) #神经元有自反馈
self.W += lr * (x * xT - np.eye(self.n)) #神经元无自反馈
def recall(self, x): #联想
x = np.reshape(x, (self.n, ))
energy_list = [-0.5 * np.sum(self.W.dot(x) * x)]
# for iter in range(self.iter): #同步调节方式
# ilf = self.W.dot(x)
# x[ilf>0] = 1
# x[ilf<0] = -1
# energy = -0.5 * np.sum(self.W.dot(x) * x)
# energy_list.append(energy)
for iter in range(self.iter): #异步调节方式
for _ in range(NET_SIZE):
i = np.random.randint(NET_SIZE)
ilf = self.W[i,:].dot(x)
if ilf > 0:
x[i] = 1
elif ilf < 0:
x[i] = -1
energy = -0.5 * np.sum(self.W.dot(x) * x)
energy_list.append(energy)
return np.reshape(x, (int(self.n**0.5), int(self.n**0.5))), energy_list
在这个Demo中,神经元的个数即为输入输出图像像素点的个数,即每个像素点对应一个神经元。神经元的两种输出状态对应像素点的颜色:1为白,-1为黑,因此此网络只能记忆联想二值图像。
实验结果
记忆阶段和联想阶段输入的图像如下:

联想阶段迭代不同的次数,输出图像如下:

能量函数随迭代次数变化如下:
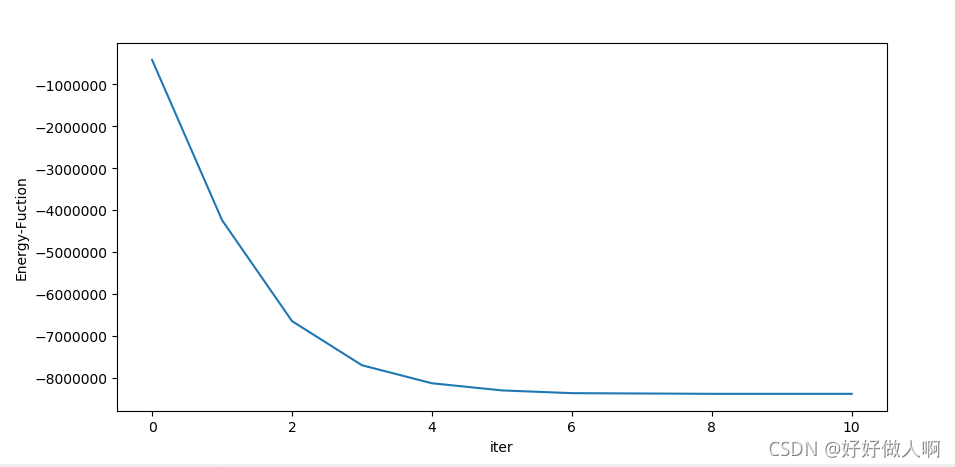
可见随着迭代轮数的增加,能量函数逐渐下降并最终于收敛于最小值(对应吸引子),相应的输出图像也越来越趋近于记忆图像。
问题与讨论
上述实验中DHNN只记忆了一个模式,即整个系统只有一个吸引子,发现网络在回忆阶段能够收敛到吸引子,实验结果很好。但当DHNN记忆了多个模式时,在记忆阶段设置权值矩阵时由于样本之间会有相互干扰,因此在联想阶段网络往往会陷入局部极值,即无法收敛到任一吸引子,这种情况在实验中很常见。此外,当记忆的两个模式相似度较大时,DHNN也有可能发生联想错误,产生串扰。这些问题需要引入玻尔兹曼机和受限玻尔兹曼机来解决。
参考文献
韩力群, 施彦. 人工神经网络理论及应用[M]. 北京: 机械工业出版社, 2016.

















 4653
4653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









