






#工业缺陷检测中数据标注需要注意的几个事项
在工业场景中,网络结构决定了下限,数据决定着上限,要想模型有好的表现,数据是至关重要的。下面就这个项目来说一说,工业缺陷检测在标注数据时需要注意的几个事项:
1、离得比较近的缺陷就合并在一个框里

编辑
编辑
以上两个图里的缺陷都是可以合并的,一是为了保持缺陷的完整性,同一个缺陷被标注成好多个,会给神经网络造成误解,同时也避免出现多个小目标。
2、尽量不要有太细长的目标
神经网络的卷积基本上都是3*3的,而且先验框anchor在设计宽高比时一般也是在1左右,回归非常细长的目标,需要比较大的感受野和宽高比,不一定能做得很好。如图左边那块目标,可以合并一下,稍微标大一点,把长宽比例搞得居中一点。

编辑
3、不要打太小的目标,比如低于10x10像素的
模型一般都对小目标不敏感,除非采用比较好的trick,就拿YOLOv4来说,到第三次下采样的特征图才拿去后面做检测,也就是在原图上最小都有8个像素,才能在特征图上体现为1个像素。有人会杠了,那我的目标就是小目标啊,小哥,我说了,另外还有很多trick的,不在本文讨论范围,打标签这个环节你要么打大点,要么不要打,或者把局部区域放大成大图,再打标签,不然送到模型里头,也是没用的。这跟严谨不严谨没有任何关系。
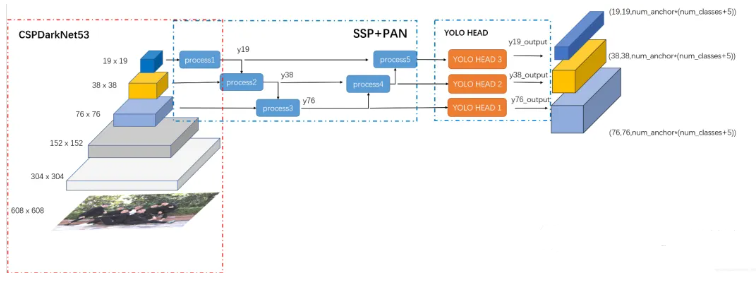
编辑
YOLOv4网络结构图
4、不要标注特别不明显的特征
这一条相信都能理解,特征连人都认不出来,哪个网络都不好识别吧。像这种标注框,恐怕谁都不好认吧。

编辑
5、框的位置尽量准确一点,把缺陷部分刚好框进去
像右下角那个框,完全可以打大点吧。

编辑
6、需要检测的缺陷在训练集中至少要出现一次相似的
另外,需要多说一句,跟标注无关的。就是虽然都是缺陷,但实际上也分很多种的,如果训练集里都没有出现过相似的,就基本上别指望测试时能够检测出来了。比如下图中,虽然只划分了一类缺陷,但是从特征的角度来说,实际上已经是好几类了,比如划痕、凸起、裂开。还是回到开头那句话:网络结构决定了下限,数据决定上限。目前的技术,不靠大量的数据喂,是训练不出很好的模型的。
#PGTFormer
首个视频人脸修复技术!让人脸细节更清晰!
本篇分享 IJCAI 2024 论文Beyond Alignment: Blind Video Face Restoration via Parsing-Guided Temporal-Coherent Transformer,西电、西南科大联合提出首个视频人脸修复技术!让人脸细节更清晰!
论文地址:https://arxiv.org/abs/2404.13640
论文主页:https://kepengxu.github.io/projects/pgtformer/
开源代码地址:https://github.com/kepengxu/PGTFormer
研究者主页:https://kepengxu.github.io
引言
视频人脸恢复结果。左侧是输入的低质量视频人脸,右侧是通过PGTFormer恢复后的高质量人脸。
在计算机视觉领域,视频人脸恢复一直是一个备受关注的研究方向。然而,大多数现有的方法主要针对静态图像,无法有效处理视频中的时序信息,往往需要繁琐的对齐操作,并且在面对长视频时,容易出现恢复结果不一致的问题。
针对这些挑战,研究者首创性地提出了PGTFormer(Parsing-Guided Temporal-Coherent Transformer),这是第一个专门为视频人脸恢复设计的方法。PGTFormer采用了端到端的设计,摒弃了传统方法中的复杂对齐步骤,实现了更加高效和连贯的视频人脸恢复。
方法介绍
设计动机

框架对比
图中展示了过去方案和PGTFormer在处理视频人脸恢复时的不同流程。(a)展示过去方案需要对齐操作的复杂流程,(b)展示PGTFormer的方法,完全省去了对齐步骤,直接实现了端到端的视频恢复。
现有的视频人脸恢复方法面临的主要问题在于时序一致性和对齐的复杂度。许多方法为了保持视频帧间的一致性,依赖于对帧进行精确对齐,这不仅增加了计算复杂度,还可能引入对齐误差,导致恢复效果不佳。
为了克服这些问题,研究者设计了PGTFormer。该方法通过引入解析引导和时序一致性建模,完全抛弃了对齐操作,实现了端到端的视频人脸恢复。这一创新设计大大简化了处理流程,同时显著提升了恢复结果的连贯性和视觉效果。
网络结构

网络结构
图中详细展示了PGTFormer的网络结构。图中还展示了TS-VQGAN与PGTFormer之间的协作关系,说明了两阶段训练的过程。
PGTFormer的网络结构旨在从根本上解决视频人脸恢复中的关键难题。其训练过程分为两个主要阶段:
- 第一阶段 - 训练TS-VQGAN(时空VQGAN):在这个阶段,研究者首先训练TS-VQGAN,该模型通过嵌入高质量的视频人脸先验信息,为PGTFormer后续的恢复任务提供了强大的基础。TS-VQGAN能够有效地捕捉和表示高质量人脸的空间和时间特征,生成与真实人脸非常接近的先验嵌入。这些嵌入在后续步骤中将作为PGTFormer的查询目标。
- 第二阶段 - 训练PGTFormer:在第二阶段,PGTFormer通过人脸解析模块和时空Transformer模块,利用第一阶段中训练得到的高质量视频人脸先验,完成视频人脸恢复任务。具体而言,PGTFormer首先解析输入的低质量视频帧,提取出关键的面部特征,然后通过时空Transformer模块,从TS-VQGAN生成的高质量人脸先验中查询相应的细节信息。最终,解码器将这些查询得到的高质量特征整合到原始视频中,输出高清且时序一致性强的恢复视频。
实验结果
为了验证PGTFormer的有效性,研究者在多个公开数据集上与其他最先进的方法进行了对比。以下是PGTFormer与其他方法在多个定量指标上的表现,涵盖了在对齐和非对齐人脸视频上的训练和测试结果。

定量实验结果
如表格所示,PGTFormer在多个关键指标上显著超越了现有的最先进方法,具体包括:
- PSNR(峰值信噪比):PGTFormer在对齐人脸视频和非对齐人脸视频上的PSNR值分别达到了30.74和29.66,明显高于其他方法,表明其在重建图像质量上的强大能力。
- SSIM(结构相似性):PGTFormer在SSIM指标上也展现了卓越的表现,在对齐和非对齐数据集上的SSIM值分别为0.8668和0.8408,远高于其他竞争方法,证明了PGTFormer在保持结构一致性方面的优势。
- LPIPS(感知相似度):PGTFormer在LPIPS指标上取得了最低值,分别为0.2095(对齐)和0.2230(非对齐),表明在主观视觉感受上,PGTFormer生成的图像与高质量图像的差异最小,具有更好的视觉效果。
- Deg、LMD、TLME、MSRL:在这些用于评价面部特征、扭曲程度、时间一致性和细节保留的指标上,PGTFormer也全面领先于其他方法,展现出极强的全方位恢复能力。
主观对比结果
除了定量评价外,研究者还进行了大量的主观视觉对比实验。主观结果清晰地展示了PGTFormer在恢复视频人脸时的卓越表现:

视觉结果
图中展示了PGTFormer与其他方法在视觉效果上的差异。可以看到PGTFormer在细节保留、伪影去除以及及面部自然度上明显优于其他方法。
主观视觉对比结果表明,PGTFormer能够有效恢复面部细节,如眼睛、嘴巴的轮廓和纹理。与其他方法相比,PGTFormer生成的面部更加生动,色彩还原度更高,几乎没有伪影和不自然的过渡。
结论
PGTFormer作为第一个专门为视频人脸恢复设计的方法,在该领域中开创了一个新的方向。其端到端的设计彻底解决了传统方法中对齐操作复杂且易引入误差的问题,同时通过解析引导和时序一致性建模,实现了高效、自然的视频人脸恢复。
未来,研究者计划进一步优化网络结构,并将其应用到更广泛的视频增强任务中,期待PGTFormer能够在更多实际场景中展现出卓越的性能。
#自动驾驶场景下面向真实世界布局的转变
本文提出一种新颖的多模态场景适应方法DCF,被ACM Multimedia 2024提名为口头报告(Oral Presentation,3.97%)。本方法通过手工设计的基于深度感知的类别过滤器,手动将自动驾驶场景的物体分类为近景,中景,远景,并且将不符合预先定义分布的数据进行过滤,实现由虚拟到真实世界分布的转变。提出的方法显著提高了小物体类别的性能,并能灵活地迁移到不同模型,取得SOTA结果。
论文一作陈牧是来自澳大利亚悉尼科技大学ReLER Lab的在读博士,导师为杨易教授。近两年在视觉及多媒体领域顶级会议发表多篇一作论文,并担任T-PAMI等ACM/IEEE顶级期刊和会议审稿人。主要研究兴趣为计算机视觉,包括视觉场景理解、视频分割、领域自适应、以人为中心的场景交互等。更多信息见个人主页:https://chen742.github.io
引用:
论文地址:https://arxiv.org/abs/2311.12682
代码地址:https://github.com/chen742/DCF
作者主页:https://chen742.github.io
Abstract通过无监督领域自适应(UDA)进行场景分割,可以将从源合成数据中获得的知识转移到现实世界的目标数据,从而大大减少了在目标领域中手动标注像素级别的需求。为了促进领域不变特征的学习,现有的方法通常通过简单地复制和粘贴像素,将源领域和目标领域的数据混合。这种简单的方法通常是次优的,因为它们没有考虑混合的布局与现实场景的匹配程度。现实场景具有固有的布局特征。我们观察到,诸如人行道、建筑物和天空等语义类别,显示出相对一致的深度分布,并且在深度图中可以清晰地区分。由于不合理的混合,模型在预测目标领域时会出现混淆。例如,将近处的“行人”像素直接粘贴到远处的“天空”区域是没有意义的。基于这一观察,我们提出了一个深度感知框架,显式利用深度估计来混合类别,并在端到端的方式中促进两个互补任务,即分割和深度学习。特别地,该框架包含一个用于数据增强的深度引导上下文过滤器(DCF)和一个用于上下文学习的跨任务编码器。DCF模拟了现实世界的布局,而跨任务编码器进一步自适应地融合了两个任务之间的互补特征。此外,几个公共数据集没有提供深度标注,因此我们利用现成的深度估计网络来获取伪深度。大量实验表明,我们的方法即使使用伪深度,也能取得具有竞争力的性能。
Introduction
语义分割是机器视觉中的一项基本任务,支持着众多视觉应用。在过去的几年里,语义分割取得了显著的进展。值得注意的是,现有的主流模型通常需要大规模的高质量标注数据集,例如ADE20K,才能获得良好的性能。然而,在现实世界中,获取像素级别的标注数据通常代价高昂且耗时。一种直接的解决方案是使用合成数据进行网络训练,因为合成数据的像素级别标注相对容易获得。然而,由于天气、光照和道路设计等多种因素,使用合成数据训练的网络在实际应用中表现出较差的可扩展性。因此,研究人员转向无监督领域自适应(UDA)以应对不同领域间的差异。UDA方法的一个分支试图通过对齐领域分布来减轻领域偏移。另一种可能的范式是自训练,它通过递归地优化目标伪标签来逐步减少领域偏移。更进一步,最近的DACS方法及其后续工作结合了自训练和ClassMix方法,在源域和目标域之间混合图像。通过这种方式,这些方法能够创建高度扰动的样本,以促进两个领域之间共享知识的学习,从而辅助训练。具体而言,跨域混合的目标是将某些类别的对应区域从源域图像中复制并粘贴到未标注的目标域图像中。然而,我们注意到,这种简单的策略会导致将大量对象粘贴到不合理的深度位置。这是因为每个类别在深度分布上都有其特定的位置。例如,背景类如“天空”和“植被”通常出现在较远的位置,而占用像素较少的类别如“交通志”和“电杆”通常出现在较近的位置。这种合成的训练数据会损害上下文学习,导致特别是在小物体的定位预测性能上表现不佳。为了解决这些局限性,我们观察了现实世界中的深度分布,发现语义类别在深度图中可以轻松分离(解耦),因为在特定场景(例如城市场景)下,它们遵循相似的分布。因此,我们提出了一个新的深度感知框架,该框架包含深度上下文过滤器(DCF)和一个跨任务编码器。具体而言,DCF利用深度信息去除与现实世界目标训练样本不匹配的非现实类别。另一方面,多模态数据可以提高深度表示的性能,因此有效利用这些深度多任务特征以提高最终预测的准确性显得尤为关键。我们提出的跨任务编码器包含两个特定的头部,用于为每个任务生成中间特征,并且包含一个自适应特征优化模块(AFO)。AFO鼓励网络通过端到端的方式来优化融合的多任务特征。具体来说,所提出的AFO采用了一系列Transformer模块来捕捉区分不同类别所需的关键信息,并为区分性特征分配高权重,反之亦然。
我们的主要贡献如下:
(1)我们提出了一个简单的深度引导上下文过滤器(DCF),以显式利用深度图中隐藏的关键语义类别分布,增强跨域信息混合的现实性,并优化跨域布局混合。
(2)我们提出了一个自适应特征优化模块(AFO),使跨任务编码器能够利用区分性的深度信息,并将其嵌入到视觉特征中,从而共同促进语义分割和伪深度估计。
(3)尽管方法简单,但通过广泛的消融实验验证了我们提出的方法的有效性。尽管使用的是伪深度,我们的方法在两个常用的场景自适应基准上仍然取得了具有竞争力的准确性,即在GTA→Cityscapes任务上达到77.7 mIoU,在Synthia→Cityscapes任务上达到69.3 mIoU。
Method 1. Problem Formulation在一般的 UDA 设置中, 标签丰富的合成数据被用作源域 , 而标签稀缺的真实世界数据被视为目标域 。例如,我们在源域中从源域数据 采样 个标记的训练样本 , 其中 是第 i 个样本数据, 就是对应的语义分割真实标签, 是深度估计任务的标签。相应的,我们有 m 个从目标域数据采样的未标记目标图像 , 被标记为 , 其中 是目标域中第 i 个的未标记样本, 是深度估计任务的标签。由于公共数据集不支持深度信息标注, 因此我们采用了现成模型可以简单生成的伪深度图。
2. Depth-guided Contextual Filter在UDA中,最近的工作通过混合像素的策略来生成跨域增强样本。典型的混合是从源域图像复制一组像素,并将这些像素粘贴到目标域图像的一组像素。由于源和目标领域数据之间的不同布局,要想制作高质量的跨领域混合样本进行训练对这种普通方法具有挑战性。为了减少噪声信号并使用真实世界的布局模拟增强的训练样本,我们提出了Depth-guided Contextual Filter来减少跨域混合的噪声像素。

基于大多数语义类别通常属于有限深度范围的假设,我们引入DCF,将目标深度图划分为几个离散的深度区间。DCF的实现在Algorithm中用伪代码表示如下:
Algorithm

DCF的实现被表示为Algorithm 1中的伪代码,其中图像 和对应的语义标签 是从源域数据中采样的。图像 和深度标签 来自目标域数据。然后生成伪标签 :

对于给定真实世界目标输入图像 , 我们有对应的伪标签 和目标域的深度图 组合。在每个深度间隔 中,对于每个类 都是可以预先计算。例如,深度间隔 处的类别 i 的密度值被计算为 。所有的密度值构成目标域图像中的深度分布。然后我们随机选择源图像上的一半类别。在实际过程中,我们应用二进制掩码 来表示相应的像素。然后, 朴素跨域混合图像 和混合标签 可以公式化为:

⊙表示掩模和图像之间的逐元素乘法, 图 2 显示了原始混合图像。可以观察到, 由于两个域之间的深度分布差异, "Building"类别的像素从源域混合到目标域的过程中, 产生了不真实的图像。使用这样的训练样本进行训练将损害上下文学习。因此, 我们建议对混合图像中与深度密度分布不匹配的像素进行过滤。初始混合后, 我们在每个深度区间重新计算每一类的密度值。例如 处的类 i 的新密度值表示为 , 然后,我们计算每个粘贴类别的深度密度分布差异,并将深度间隔 处的类别 i 的差异表示为 旦 超过该类别 的阈值,这些粘贴的像素就会被删除。执行 DCF 后,我们确认最终要混合的真实像素并构造一个深度感知的根据当前目标图像的深度布局动态变化的二进制掩模 ,
然后生成过滤后的混合样本。在实践中,我们直接应用更新过的深度感知掩模来替换原始掩模。因此,新的混合样本和标签如下:

过滤后的样本如图2所示。由于“sky”和““terrain””等大物体通常聚集并占据大量像素,而小物体在一定深度范围内只占据少量像素,因此我们设置不同的像素。每个类别的过滤阈值。因为没有可用的真实label的基本事实,所以DCF对目标域使用伪语义标签。由于早期标签预测不稳定,我们采用warmup策略在10000次迭代后执行DCF的时候。输入图像、简单混合样本和过滤样本的示例如图2所示。经过DCF模块处理后的样本具有来自源域的像素与目标域的深度分布相匹配,帮助网络更好地处理域差距。
3. Multi-task Scene Adaptation Framework为了利用分割和深度学习之间的关系,我们引入了一个多任务场景适应框架,包括高分辨率语义编码器和具有特征优化模块的跨任务共享编码器,如图3所示。框架整合并优化了深度信息的融合,以改进最终的语义预测。

High Resolution Semantic Prediction. 大多数监督方法使用高分辨率图像进行训练,但常见的场景适应方法通常使用全分辨率一半的图像随机裁剪。为了减少场景适应和监督学习之间的域差距,同时保持GPU内存消耗,我们采用高分辨率编码器来编码全分辨率一半的图像。为了缩小场景适应和监督学习之间的领域差距,同时保持GPU内存消耗,我们采用高分辨率编码器将HR图像作物编码为深度HR特征。然后使用语义解码器生成HR语义预测。这里,我们采用交叉熵损失进行语义分割:

这里 和 都是高分辨率语义预测的结果。 是源域的 one-hot 语义标签, 是深度感知融合域的 one-hot 伪标签。
Adaptive Feature Optimization. 除了高分辨率编码器之外,我们还使用另一个跨任务编码器来编码两个任务共享的输入图像。深度图富含空间深度信息,但是深度信息直接与视觉信息的简单串联会造成一些干扰,例如相似深度位置的类别已经可以通过视觉信息很好地区分,注意力机制可以帮助网络选择多任务信息中的关键部分。在所提出的多任务学习框架中,视觉语义特征和深度特征分别由视觉头和深度头生成。如图 3 所示,应用批量归一化后,自适应特征优化模块将归一化的输入视觉特征和输入深度特征连接起来,以创建融合的多任务特征:

CONCAT(,)表示串联操作。融合的特征被输入到一系列转换器块中,以捕获两个任务之间的关键信息。注意力机制自适应地调整深度特征嵌入视觉特征的程度。

是transformer参数。Transformer blocks的学习输出是权重图γ,它乘回到输入视觉特征和深度特征,从而为每个任务产生优化的特征。

表示卷积参数, 表示卷积运算, 表示 sigmoid 函数。权重矩阵 执行多任务特征的自适应优化。然后将融合后的特征 输入不同的解码器以预测不同的最终任务,即视觉和深度任务。输出特征本质上是包含关键深度信息的多模态的特征。

其中⊙表示逐元素乘法。然后,优化的视觉和深度特征被输入多模通信模块进行进一步处理。多模态通信模块通过迭代使用 transformer blocks 来细化两个任务之间关键信息的学习。在特征优化完成后, 推断仅仅基于视觉输入。最终的语义预测 和深度预测 可以通过视觉头和深度头根据最终视觉特征 和深度特征 生成。与高分辨率预测类似, 这里我们使用交叉熵损失进行语义损失计算:

我们还在源域使用berHu损失进行深度回归:

其中, 和 分别是预测的和真实语义标签图。根据SPIGAN[61]和Suman Saha[63]的工作,我们采用了反向Huber损失函数[71],其定义为:

其中H是正阈值,我们将其设置为最大深度残差的0.2。最后,总损失函数为:

其中超参数 深度是损失重量。考虑到我们的主要任务是语义分割, 深度估计是辅助任务, 我们经验地得出 , 我们还设计了消融研究, 以改变深度任务的权重 参数的数量级为 或 。
Experiment Implementation Details数据集。 我们在两个场景适应设置上评估了所提出的框架,即,GTA→Cityscapes和SYNTHIA→Cityscapes。GTA5数据集是从视频游戏收集的合成数据集,其包含由19个类注释的24966个图像。对于深度估计,我们采用了由Monodepth 2模型生成的深度信息,该模型仅在GTA图像序列上训练。SYNTHIA是一个包含9400个训练图像和16个类别的合成城市场景数据集。这里直接使用SYNTHIA所提供的模拟深度信息。GTA和SYNTHIA作为源域数据集。目标域数据集是Cityscapes,它是从真实世界的街景图像中收集的。Cityscapes包含2975个未标记的训练图像和500个验证图像。Cityscapes的分辨率为2048×1024,通用协议将尺寸缩小到1024 × 512以节省存储器。我们利用并集交集(IoU)来计算每个类的性能,并利用所有类的并集交集平均值(mIoU)来报告结果。该代码基于Pytorch。我们将使我们的代码开放源代码,以重现所有实验结果。
实验设置。 我们采用DAFormer网络和MiT-B5骨干网实现高分辨率编码器,采用DeepLabV 2网络和ResNet-101骨干网实现跨任务编码器,来减少内存消耗。所有主干均使用ImageNet预训练进行初始化。我们的训练过程基于具有跨域混合的自训练方法,并通过我们提出的深度引导上下文过滤器来增强。输入图像分辨率对于跨任务编码器是全分辨率的一半,对于高分辨率编码器是全分辨率。我们使用相同的数据增强,例如,颜色抖动和高斯模糊,并根据经验设置伪标签阈值0.968。我们在Tesla V100 GPU上设置batch size大小为2训练网络,进行40000次迭代。
Comparison with SOTAGTA→城市景观结果。
我们在GTA到Cityscapes的数据集迁移上展示了我们的实验结果。表1中显示了GTA到Cityscapes的结果,并用粗体标出了最佳成绩。可以看出,我们的方法相比于最先进的MIC[1]方法,在平均交并比(mIoU)上从75.9提升到了77.7,表现出了显著的性能改进。通常情况下,占据像素较少的类别较难适应,并且通常具有相对较低的IoU性能。然而,我们的方法在大多数类别上表现出有竞争力的IoU提升,特别是在小物体上,例如,““Rider”,”提高了+5.7,“Fence”提高了+5.4,“Wall”提高了+5.2,““Traffic Sign”提高了+4.4,“Pole”提高了+3.4。这一结果表明了所提出的上下文过滤器和跨任务学习框架在上下文学习中的有效性。我们的方法同样也对那些占据图像大量像素的大类别的mIoU性能有所提高,但提升幅度较小,比如“Pedestrain”提高了+1.8,“Bike”提高了+1.1,这可能是因为丰富的纹理和颜色信息已经具备了识别这些相对容易的类别的能力。上述观察也在图4中定性地反映出来,在该图中我们展示了所提出的方法与之前强大的基于变换器的方法HRDA[23]和MIC[1]的分割结果对比。用白色虚线框突出显示的定性结果表明,所提出的方法在挑战性的“Traffic Sign”和大类别“Terrain”上的预测质量有了大幅度的改善。

Synthia→城市景观的结果。
我们在表1中展示了我们在SYNTHIA→cityscape上的结果,结果表明我们的方法的性能得到了持续的改进,与最先进的方法MIC[1]相比,从67.3增加到69.3 (+2.0 mIoU)。特别是我们的方法将具有挑战性的“SideWalk”区块的IoU性能从50.5提高到63.1 (+12.6 mIoU)。同样值得注意的是,我们的方法在分割大多数个体类别方面仍然具有竞争力,并且在“Road”上获得+6.8,“Bus”上获得+6.6,“Pole”上获得+3.9,“Road”上获得+3.7,“Wall”上获得+3.2,“Truck”上获得+2.9。


我们将我们的方法与GTA→Cityscapes上的不同场景适应架构相结合。表4显示我们的方法在不同网络架构的不同方法中实现了一致且显着的改进。首先,我们的方法将最先进的性能提高了+1.8 mIoU。然后,我们在基于Transformer Backbone的两种强大方法上评估所提出的方法,在DAFormer和HRDA上分别产生+3.2 mIoU和+2.3 mIoU性能提升。其次,我们在具有ResNet-101主干的DeepLabV2架构上评估我们的方法。我们表明,我们将基于CNN的跨域混合方法(即 DACS)的性能提高了+4.1 mIoU。消融研究验证了我们的方法在利用深度信息来增强跨域混合方面的有效性,不仅在基于Transformer的网络上,而且还在基于CNN的架构上。
Ablation Study on Different Components of theProposed Method为了验证我们提出的组件的有效性,我们训练了从M1到M4的四种不同模型,结果如表3所示。“ST Base”是指具有语义分割分支和深度回归分支的自训练基线。“Naive Mix”表示跨域混合策略。“DCF”代表所提出的深度感知混合(深度引导上下文过滤器)。“AFO”表示提出的自适应特征优化模块,我们使用两种不同的方法来执行AFO。首先,我们利用通道注意力(CA),它可以沿着通道维度选择有用的信息来执行特征优化。在该方法中,融合特征由SENet [78] 自适应优化,输出是一个加权向量,乘以视觉和深度特征。我们用“AFO(CA)”来表示这种方法。其次,我们利用变压器块的迭代使用来自适应优化多任务特征。在这种情况下,变压器块的输出是加权图。然后使用多模态通信(MMC)模块来整合来自深度预测的丰富知识。我们将此方法表示为“AFO(Trans + MMC)”。M1是基于DAFormer架构的深度回归自训练基线。M2 添加了跨域混合策略进行改进,并显示出76.0 mIoU的竞争结果。M3是带有深度引导上下文滤波器的模型,将性能从76.0 mIoU 提高到77.1 mIoU (+1.1 mIoU),这证明了在深度信息的帮助下将混合训练图像转移到真实世界布局的有效性。M4添加了多任务框架,利用通道注意力(CA)机制将判别深度特征融合到视觉特征中。分割结果小幅增加(+0.2 mIoU),这意味着CA可以在一定程度上帮助网络自适应地学习聚焦或忽略来自辅助任务的信息。M5 是我们提出的深度感知多任务模型,具有深度引导上下文过滤器和自适应特征优化(AFO)模块。与M3相比,M5的mIoU增加了+0.6,从77.1增加到77.7,这表明使用Transformer 进行多模态特征优化以促进上下文学习的有效性。

在这项工作中,我们引入了一个新的深度感知场景自适应框架,有效地利用深度的指导,以增强数据增强和上下文学习。提出的框架不仅通过激励真实世界布局的深度分布指导明确地优化跨领域混合,还引入了一个跨任务编码器,自适应优化多任务特征并专注于有助于上下文学习的具有区分性的深度特征。通过将我们的深度感知框架集成到现有的基于Transformer或CNN的自训练方法中,我们在两个广泛使用的基准测试中实现了最先进的性能,并在小规模类别上取得了显着的改进。大量的实验结果验证了我们将训练图像转移到真实世界布局的动机,并证明了我们的多任务框架在提高场景适应性能方面的有效性。
#CamoTeacher
玩转半监督伪装物体检测,双旋转一致性动态调整样本权重论文提出了第一个端到端的半监督伪装目标检测模型CamoTeacher。为了解决半监督伪装目标检测中伪标签中存在的大量噪声问题,包括局部噪声和全局噪声,引入了一种名为双旋转一致性学习(DRCL)的新方法,包括像素级一致性学习(PCL)和实例级一致性学习(ICL)。DRCL帮助模型缓解噪音问题,有效利用伪标签信息,使模型在避免确认偏差的同时可以获得充分监督。广泛的实验验证了CamoTeacher的优越性能,同时显著降低了标注要求。
论文地址: https://arxiv.org/abs/2408.08050
Introduction伪装物体检测(COD)旨在识别在其环境中完全融入的物体,包括动物或具有保护色彩并具有融入周围环境能力的人造实体,这一任务由于低对比度、相似纹理和模糊边界而变得复杂。与一般物体检测不同,COD受到这些因素的挑战,使得检测变得格外困难。现有的COD方法严重依赖于大规模的像素级注释数据集,其创建需要大量的人力和成本,从而限制了COD的进展。

为了缓解这一问题,半监督学习作为一种有希望的方法出现,利用标记和未标记数据。然而,由于复杂的背景和微妙的物体边界,其在COD中的应用并不直接。半监督学习在COD中的有效性受到伪标签中存在的大量噪声的严重影响,伪标签的噪声有两种主要类型:像素级噪声,表明在单个伪标签内的变化,以及实例级噪声,显示不同伪标签之间的变化。这种区分是至关重要的,因为它指导了如何改进伪标签质量以提高模型训练的方法。(1)像素级噪声的特点是在伪标签的各个部分内部的标注不一致。如图1a中所示,在第一行中,壁虎的尾部在视觉上比头部更难以识别。由SINet生成的伪标签在其尾部区域中的准确性较低(由红色框标出)。这一观察结果强调了对伪标签内的所有部分统一处理的不当性。(2)实例级噪声指的是不同伪标签之间噪声水平的变化。如图1a所示,第三行的伪标签与第二行相比不太准确,因为第三行中的伪装对象更难以检测。这些差异表明每个伪标签对模型训练的贡献是不同的,强调了需要对整合伪标签信息采取细致差异的方法。

为了解决在没有未标记GT的数据的情况下评估伪标签噪声的挑战,论文提出了基于两个旋转视图的像素级不一致性和实例级一致性的两种新策略。具体来说,对于像素级噪声,论文观察到通过比较两个旋转视图的伪标签计算出的像素级不一致性,可以反映相对于GT的实际误差,如图2a所示。这种关系显示了不同部分之间平均像素级不一致性与平均绝对误差(MAE)之间的正相关性,如图2b的折线所示。因此,具有较高像素级不一致性的区域更容易出现不准确性,表明在训练过程中需要减弱这些区域的重要性。

对于实例级噪声,跨旋转视图具有更大相似性的伪标签展示了更低的噪声水平,如图3a所示。伪标签和GT计算的SSIM之间的实例级一致性与正相关性进一步支持了这一观察结果,如图3b所示。因此,表现出更高实例级一致性的伪标签可能具有更高质量,并应在学习过程中优先考虑。
通过这些观察结果,论文提出了一种名为CamoTeacher的半监督伪装物体检测框架,该框架结合了一种名为Dual-Rotation Consistency Learning(DRCL)的新方法。具体而言,DRCL通过两个核心组件来实现其策略:像素级一致性学习(PCL)和实例级一致性学习(ICL)。PCL通过考虑不同旋转视图之间的像素级不一致性,创新地为伪标签中的不同部分分配可变权重。同时,ICL根据实例级一致性调整各个伪标签的重要性,实现细致、噪声感知的训练过程。
论文采用SINet作为基础模型来实现CamoTeacher,并将其应用于更经典的伪装物体检测(COD)模型,即基于CNN的SINet-v2和SegMaR,以及基于Transforme的DTINet和FSPNet。在四个COD基准数据集(即CAMO,CHAMELEON,COD10K和NC4K)上进行了大量实验,结果显示CamoTeacher不仅在与半监督学习方法相比方面达到了最先进的水平,而且与已建立的全监督学习方法相媲美。具体来说,如图1b所示,仅使用了20%的标记数据,它几乎达到了在COD10K上全监督模型的性能水平。
论文的贡献可以总结如下:
引入了第一个端到端的半监督伪装物体检测框架CamoTeacher,为未来半监督伪装物体检测的研究提供了一个简单而有效的基准。
为解决半监督伪装物体检测中伪标签中大量噪声的问题,提出了Dual-Rotation Consistency Learning(DRCL),其中包括Pixel-wise Consistency Learning(PCL)和Instance-wise Consistency Learning(ICL),允许自适应调整不同质量伪标签的贡献,从而有效利用伪标签信息。
在COD基准数据集上进行了大量实验,相较于完全监督设置,取得了显著的改进。
Methodology Task Formulation半监督伪装物体检测旨在利用有限的标记数据训练一个能够识别与周围环境无缝融合的物体的检测器。由于物体与背景之间的对比度较低, 这个任务本身具有挑战性。给定一个用于训练的伪装物体检测数据集 , 含 个标记样本的标记子集表示为 , 含 个未标记样本的未标记子集表示为 , 其中 和 表示输入图像, 表示标记数据的相应注释掩码。通常, 只占整个数据集 的很小一部分, 这突出了 的半监督学习场景。对于 的强调, 强调了半监督学习中的挑战和机遇: 通过利用末标记数据 尚未发掘的潜力来提升检测能力,而这远远超过了标记子集 。
Overall Framework
如图 4 所示, 采用 Mean Teacher 作为初步方案, 以实现端到端的半监督伪装物体检测框架。该框架包含两个具有相同结构的 COD 模型, 即教师模型和学生模型, 分别由参数 和 参数化。教师模型生成伪标签, 然后用于优化学生模型。整体损失函数 可以定义为:

其中, 和 分别表示有监督损失和无监督损失, 是平衡损失项的无监督损失权重。按照经典的 COD 方法, 使用二元交叉嫡损失 用于训练。 在训练过程中,采用弱数据增强 和强数据增强 策略的组合。弱数据增强应用于有标记数据以减轻过拟合,而无标记数据在强数据增强下经历各种数据扰动,以创造同一图像的不同视角。有监督损失的定义如下:

其中, 表示模型 对第 张图像在增强 下的检测结果。对于无标记的图像, 首先应用弱数据增强 , 然后将其传递给教师模型。这一初始步骤对于在不显著改变图像核心特征的变化下生成可靠的伪标签 至关重要。这些伪标签作为学生模型的一种软监督形式。接下来, 相同的图像经过强数据增强 后传递给学生模型。这个过程引入了更高层次的变异性和复杂性, 模拟更具挑战性的条件, 以适应学生模型。学生模型基于这些经过强增强的图像生成预测 , 利用伪标签 作为无标记数据学习的指导。可以将其形式化为:

因此,无监督损失可以表示为:

最后,学生模型通过总损失 进行密集训练,该损失包含了半监督框架中有监督和无监督学习的两个方面。这种方法确保学生模型从有标记和伪标记数据中受益,提高其检测能力。同时,教师模型通过指数移动平均(EMA)机制进行系统更新,有效地提取学生知识并防止噪音干扰,具体表述为:

其中,是一个超参数,表示保留的比例。
Dual-Rotation Consistency Learning由于物体的伪装性质,伪标签中包含大量噪音,直接使用它们来优化学生模型可能会损害模型的性能。为解决这个问题,最直观的一个可能方法是设置一个固定的高阈值来过滤高质量的伪标签,但这会导致召回率较低,并使得难以充分利用伪标签的监督信息。为此,论文提出了双旋转一致性学习(DRCL),以动态调整伪标签的权重,减少噪音的影响。
对图像 进行两个独立的随机旋转, 其中 在之前已进行了翻转和随机调整大小, 得到两个不同的旋转视图 和 。

其中, 表示将输入图像 旋转 度。将获得的旋转视图输入到教师模型中, 得到相应的预测值, 即 。随后, 对预测值进行 的相反旋转, 使其返回到原始的水平方向, 得到 和 , 以便在不同的旋转视图下计算预测不一致性。

请注意,旋转会引入黑色的边界区域,这些区域不参与DRCL的计算过程。
由于伪标签的不同区域和不同伪标签之间的噪声水平不同,引入PCL和ICL动态调整不同像素在伪标签内部和各个伪标签之间的贡献。
Pixel-wise Consistency Learning
在像素级别上对水平预测 和 进行减法运算, 得到像素级别的不一致性 。

不同视图之间的像素级不一致性反映了伪标签的可靠性。然而,在两个旋转视图的预测值都接近0.5的情况下,无法有效区分它们。这些预测表现出高度的不确定性,意味着不能明确将它们分类为前景或背景,并且很可能代表嘈杂的标签。因此,有必要通过降低它们的权重来减弱它们的影响。因此,计算水平预测值的平均值,

其中,表示计算两个像素级别输入的平均值,并使用其与0.5的L2距离作为调整权重的一个组成部分。
因此,根据不同旋转视图之间的像素级别不一致性,推导出像素级别一致性权重,如下所示:

其中, 是一个超参数, 。这个动态的像素级一致性权重 会给与不同旋转视图间预测一致的区域分配更高的权重, 而对于预测不一致的区域则分配较小的权重。
总而言之, 将 PCL 损失函数 表述为:

自适应地调整每个像素的权重,以确保对学生模型进行全面监督,同时避免带来偏见。
- Instance-wise Consistency Learning
不同图像之间的伪装程度会有所不同,导致伪标签质量在图像之间存在显著变化。平等地对待所有伪标签是不合理的。不幸的是,对于未标记的图像,评估伪标签质量是具有挑战性的,因为没有可用的GT标签。论文呢观察到两个旋转视图的实例一致性和伪标签质量之间存在正相关,由SSIM量化。基于此,引入ICL来调整具有不同质量的伪标签的贡献。将实例级一致性权重表示如下:

其中,是一个超参数,用于调整实例级一致性和伪标签质量之间的分布关系。 使用交并比(IoU)损失作为实例级限制,因此,ICL损失可以表示为:

因此, 最终的总损失 由三个部分组成: 有监督损失 损失 和 ICL 损失 , 可以表示为:

其中, 是超参数。
Experiment- Dataset
在四个基准数据集CAMO、CHAMELEON、COD10K和NC4K上评估了CamoTeacher模型。在CAMO数据集中,共有2500张图像,包括1250张伪装图像和1250张非伪装图像。CHAMELEON数据集包含76张手动注释图像。COD10K数据集由5066张伪装图像、3000张背景图像和1934张非伪装图像组成。NC4K是另一个包含4121张图像的大规模COD测试数据集。根据先前的工作中的数据划分,使用COD10K的3040张图像和CAMO的1000张图像作为实验的训练集。剩余的图像来自这两个数据集,被用作测试集。在训练过程中,采用了半监督分割的数据划分方法。我们从训练集中随机采样了1%、5%、10%、20%和30%的图像作为有标签的数据,剩余的部分作为无标签的数据。
- Evaluation Metrics参考先前的工作, 在 COD 中使用了 6 个常见的评估指标来评估我们的 CamoTeacher 模型,包括 S-measure ( )、加权 F-measure ( )、平均 E-measure ( )、最大 E-measure ( )、平均 F-measure ( )和平均绝对误差 。
- Implementation Details
提出的CamoTeacher模型使用PyTorch进行实现。采用SINet作为COD模型的基线。使用带有动量0.9的SGD优化器和多项式学习率衰减,初始学习率为0.01,来训练学生模型。训练周期设置为40个周期,其中前10个周期为burn-in阶段。批量大小为20,有标签数据和无标签数据的比例为1:1,即每个批次包含10个有标签和10个无标签的图像。在训练和推断过程中,每个图像被调整为的大小。通过EMA方法更新教师模型,动量为0.996。弱数据增强包括随机翻转和随机缩放,而强数据增强涉及颜色空间转换,包括Identity、Autocontrast、Equalize、Gaussian blur、Contrast、Sharpness、Color、Brightness、Hue、Posterize、Solarize,从这个列表中随机选择最多3个。
Results



















 269
269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









