







图片的批量下载 和 爬虫爬取图片数据集
1、图片的批量下载
数据集是深度学习的一切,没有数据集它什么也不是,现在你知道数据集很重要了吧
代码:
'''
项目名称:爬取公章数据
创建时间:20200514
百度图片检索地址:
https://image.baidu.com/search/acjson
参考:
https://blog.csdn.net/hujn3016/article/details/78614878 # 参考程序
https://www.cnblogs.com/hum0ro/p/9536033.html # 遇到错误参考,我没有安装依赖,再运行一次就没有报错了
公司章主要有:公章、财务章、法人章、合同专用章、发票专用章
下载公章数据:
搜索关键词:
公章:检索到的基本上是圆形章
发票专用章:检索到的基本上是椭圆形章
数据转换为灰度图:
circle_red: 前三百个数据保持红色,后面的都转换为灰度图
circle_red: 300
cicle_gray: 223
rectangle_red:53
rectangle_gray:53
fingeprint_red:48
fingeprint_gray:48
other:279
# 印章提取:
https://blog.csdn.net/u011436429/article/details/80453822
https://blog.csdn.net/wsp_1138886114/article/details/82858380
20200519 爬取胸牌数据、胡子数据
Keyword:
胸牌
Keyword:
亚洲人胡子、年轻人胡子
搜索一些亚洲名人:周杰伦胡子 刘德华胡子等 胡渣
20200525 爬取帽子数据
Keyword:
空姐、空姐服装、军人贝雷帽 鸭舌帽女生 鸭舌帽男生
20200703
Keyword:
女士工作布鞋
'''
__Author__ = "Shliang"
__Email__ = "shliang0603@gmail.com"
import requests
import re
import os
import cv2
from PIL import Image
def getIntPages(keyword, pages):
params = []
for i in range(30, 30*pages+30, 30):
params.append({
'tn':'resultjson_com',
'ipn': 'rj',
'ct':'201326592',
'is': '',
'fp': 'result',
'queryWord': keyword,
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'st': '-1',
'ic': '0',
'word': keyword,
'face': '0',
'istype': '2',
'nc': '1',
'pn': i,
'rn': '30'
})
url = 'https://image.baidu.com/search/acjson'
urls = []
for i in params:
content = requests.get(url, params=i).text
img_urls = re.findall(r'"thumbURL":"(.*?)"', content)#正则获取方法
urls.append(img_urls)
#urls.append(requests.get(url,params = i).json().get('data'))开始尝试的json提取方法
#print("%d times : " % x, img_urls)
return urls
def fetch_img(path,dataList):
if not os.path.exists(path):
os.mkdir(path)
x = 474
for list in dataList:
for i in list:
print("=====downloading %d/3000=====" % (x + 1))
ir = requests.get(i)
open(os.path.join(path, '%07d.jpg' % x), 'wb').write(ir.content)
x += 1
# 图片灰度化
# 注意,opencv读取图片的路径不要有中文,否则可能找不到
def BGR2GRAY(imgs_dir, save_dir):
imgs = os.listdir(imgs_dir)
# print(len(imgs[300:]), imgs[300:])
for i, name in enumerate(imgs):
print('name: ----> ', name)
img = cv2.imread(os.path.join(imgs_dir, name))
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
print("Saving img: ", name)
cv2.imwrite(os.path.join(save_dir, 'finge_gray%d'%i + ".jpg"), gray)
# 图片重命名
import shutil
def move_file(src_dir, dst_dir):
imgs = os.listdir(src_dir)
print(len(imgs), imgs)
i = 1042
for img in imgs:
shutil.copyfile(os.path.join(src_dir, img), os.path.join(dst_dir, "%06d"%i+".jpg"))
i+=1
# 转换图片格式,并把图片从新命名
def convert_to_RGB(imgs_path, save_imgs_path, start=0):
imgs = os.listdir(imgs_path)
for img_name in imgs:
img = Image.open(os.path.join(imgs_path, img_name))
img_convert_RGB = img.convert("RGB")
img_convert_RGB.save(os.path.join(save_imgs_path, "%06d.jpg" % start))
start += 1
if __name__ == '__main__':
# 公章图片保存路径
stamps_path = r'D:/ZF/1_ZF_proj/2_YOLO/YOLO数据集相关/stamp_datasets'
# 胸牌图片保存路径
name_tags_path = r'D:\ZF\2_ZF_data\4_胸牌数据\name_tags'
# 胡子图片保存路径
beard_path = r'D:\ZF\2_ZF_data\5_胡子数据\胡茬'
# 帽子图片保存路径
hat_path = r'D:\ZF\2_ZF_data\6_帽子和头发数据\帽子数据收集\其他帽子\针织帽男生'
# 爬取女士布鞋 保存路径 关键词 女士布鞋
woman_cloth_shoes = r'D:\ZF\2_ZF_data\woman_cloth_shoes'
# 爬取抽烟数据集 关键词 男生抽烟 女生抽烟
smoke_path_boy = r'D:\ZF\2_ZF_data\16_抽烟数据集\spider_smoke\boy'
smoke_path_girl = r'D:\ZF\2_ZF_data\16_抽烟数据集\spider_smoke\girl'
#
# url = 'https://image.baidu.com/search/acjson'
# dataList = getIntPages('女生抽烟', 100) #依据蔬菜关键词获取50页的图片列表,每页30张图片
# fetch_img(smoke_path_girl, dataList) #存取图片
# img = cv2.imread('001324.jpg')
# gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# print("Saving img: ")
# cv2.imwrite('D:/ZF/2_ZF_data/3_stamp_data/res/000611.jpg', gray)
# 把图片转成灰度图片
# imgs_dir = 'D:/ZF/2_ZF_data/3_stamp_data/finge'
# save_dir = 'D:/ZF/2_ZF_data/3_stamp_data/'
# BGR2GRAY(imgs_dir, save_dir)
# 移动图片
# src_dir = r'D:\ZF\2_ZF_data\5_胡子数据\beard\JPEGImages_src'
# dst_dir = r'D:\ZF\2_ZF_data\5_胡子数据\beard\JPEGImages'
# src_dir = r'D:\ZF\2_ZF_data\woman_cloth_shoes'
# dst_dir = r'D:\ZF\2_ZF_data\shoes'
# move_file(src_dir, dst_dir)
# 转换图片格式,并把图片从新命名
imgs_path = r'D:\ZF\2_ZF_data\16_抽烟数据集\spider_smoke\boy'
save_imgs_path = r'D:\ZF\2_ZF_data\16_抽烟数据集\spider_smoke\boy_rename'
imgs_path2 = r'D:\ZF\2_ZF_data\16_抽烟数据集\spider_smoke\girl'
save_imgs_path2 = r'D:\ZF\2_ZF_data\16_抽烟数据集\spider_smoke\girl_rename'
imgs_path3 = r'D:\ZF\2_ZF_data\16_抽烟数据集\spider_smoke\boys_and_girls'
save_imgs_path3 = r'D:\ZF\2_ZF_data\16_抽烟数据集\spider_smoke\标注抽烟数据集\JPEGImages'
# convert_to_RGB(imgs_path, save_imgs_path)
# convert_to_RGB(imgs_path2, save_imgs_path2, start=241)
convert_to_RGB(imgs_path3, save_imgs_path3, start=111)
之前一直没有放代码,不要意思呀,让各位看官就等了!
可能会报错:requests.exceptions.TooManyRedirects: Exceeded 30 redirects.
参考:https://blog.csdn.net/weixin_39015449/article/details/80128711
1、打开URL页面
2、按F12打开开发者工具页面,然后Ctrl+R就可以看到下面的也买你的域名地址
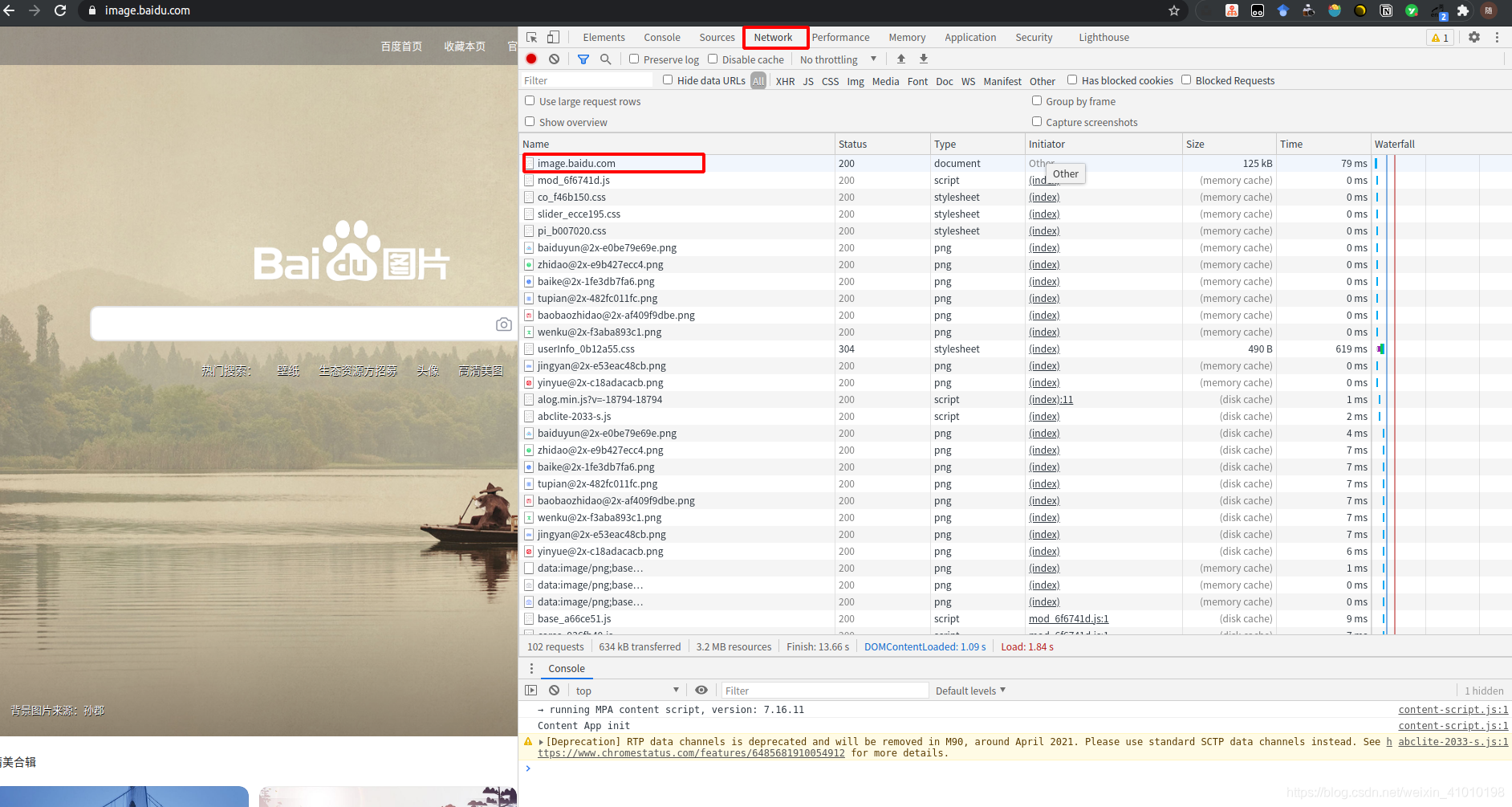
3、点进入就可以看到[User-Agent]='用户代理编码'















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









