






代码:https://github.com/ifzhang/FairMOT
论文讲解参考:https://blog.csdn.net/weixin_42398658/article/details/110873083
https://www.163.com/dy/article/H10AGKQM0552OFB6.html
https://zhuanlan.zhihu.com/p/393322545
损失函数
self.loss_stats, self.loss = self._get_losses(opt)
###IDLoss=crossentropy
###crit=focalloss
###crit_reg=l1loss
###crit_wh=l1loss
模型解码
with torch.no_grad():
output = self.model(im_blob)[-1]
hm = output['hm'].sigmoid_()
wh = output['wh']
id_feature = output['id']
id_feature = F.normalize(id_feature, dim=1)
reg = output['reg'] if self.opt.reg_offset else None
dets, inds = mot_decode(hm, wh, reg=reg, ltrb=self.opt.ltrb, K=self.opt.K)
id_feature = _tranpose_and_gather_feat(id_feature, inds) #(1,500,64)
id_feature = id_feature.squeeze(0) #(500,64)
id_feature = id_feature.cpu().numpy() #(500,64)
dets = self.post_process(dets, meta) #(500,5)
dets = self.merge_outputs([dets])[1] #(500,5)
remain_inds = dets[:, 4] > self.opt.conf_thres
dets = dets[remain_inds] #过滤完之后还剩的目标框(26,5)
id_feature = id_feature[remain_inds] #过滤完之后还剩的id特征(26,64)
if len(dets) > 0:
'''Detections'''
detections = [STrack(STrack.tlbr_to_tlwh(tlbrs[:4]), tlbrs[4], f, 30) for
(tlbrs, f) in zip(dets[:, :5], id_feature)]
else:
detections = []
''' Add newly detected tracklets to tracked_stracks'''
unconfirmed = []
tracked_stracks = [] # type: list[STrack]
for track in self.tracked_stracks:
if not track.is_activated:
unconfirmed.append(track)
else:
tracked_stracks.append(track)
''' Step 2: First association, with embedding'''
strack_pool = joint_stracks(tracked_stracks, self.lost_stracks)
# Predict the current location with KF
#for strack in strack_pool:
#strack.predict()
STrack.multi_predict(strack_pool)
dists = matching.embedding_distance(strack_pool, detections)
#dists = matching.iou_distance(strack_pool, detections)
dists = matching.fuse_motion(self.kalman_filter, dists, strack_pool, detections)
matches, u_track, u_detection = matching.linear_assignment(dists, thresh=0.4)
...
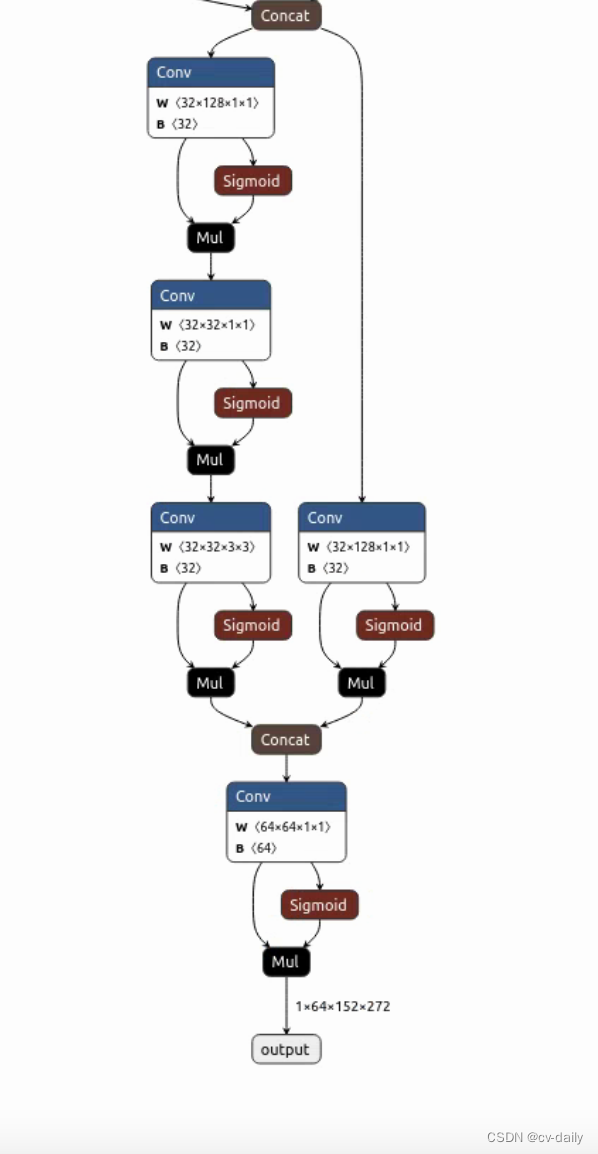
‘hm’:(1,1,152,272)
‘wh’:(1,4,152,272)
‘id’:(1,64,152,272),长度为64的特征
‘reg’:(1,2,152,272)
dets:(1,500,6)
id_feature:(1,500,64)
推理时间对比
##### FairMOT
t1 = time_sync()
output = self.model(im_blob)[-1]
t2 = time_sync()
#####yolov5s
t1 = time_sync()
pred = model(img,augment=augment,visualize=increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False)[0]
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
t2 = time_sync()
2个1080ti
u版yolov5s模型推理+nms, 640640,一张图片耗时6ms
yolov5s FairMOT模型推理,1088608,一张图片耗时10ms
FairMOT yolov5s转onnx
"""Export a YOLOv5 *.pt model to TorchScript, ONNX, CoreML formats
Usage:
$ python path/to/export.py --weights yolov5s.pt --img 640 --batch 1
"""
import argparse
import sys
import time
from pathlib import Path
import torch
import torch.nn as nn
from torch.utils.mobile_optimizer import optimize_for_mobile
from lib.models.model import create_model, load_model
from lib.models.yolo import Detect
from lib.models.common import Conv
FILE = Path(__file__).absolute()
sys.path.append(FILE.parents[0].as_posix()) # add yolov5/ to path
def colorstr(*input):
# Colors a string https://en.wikipedia.org/wiki/ANSI_escape_code, i.e. colorstr('blue', 'hello world')
*args, string = input if len(input) > 1 else ('blue', 'bold', input[0]) # color arguments, string
colors = {'black': '\033[30m', # basic colors
'red': '\033[31m',
'green': '\033[32m',
'yellow': '\033[33m',
'blue': '\033[34m',
'magenta': '\033[35m',
'cyan': '\033[36m',
'white': '\033[37m',
'bright_black': '\033[90m', # bright colors
'bright_red': '\033[91m',
'bright_green': '\033[92m',
'bright_yellow': '\033[93m',
'bright_blue': '\033[94m',
'bright_magenta': '\033[95m',
'bright_cyan': '\033[96m',
'bright_white': '\033[97m',
'end': '\033[0m', # misc
'bold': '\033[1m',
'underline': '\033[4m'}
return ''.join(colors[x] for x in args) + f'{string}' + colors['end']
def export_onnx(model, img, file, opset_version, train, dynamic, simplify):
# ONNX model export
prefix = colorstr('ONNX:')
import onnx
print(f'\n{prefix} starting export with onnx {onnx.__version__}...')
f = file.with_suffix('.onnx')
torch.onnx.export(model, img, f, verbose=False, opset_version=opset_version,
training=torch.onnx.TrainingMode.TRAINING if train else torch.onnx.TrainingMode.EVAL,
do_constant_folding=not train,
input_names=['images'],
output_names=['output'],
dynamic_axes={'images': {0: 'batch', 2: 'height', 3: 'width'}, # shape(1,3,640,640)
'output': {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
} if dynamic else None)
# Checks
model_onnx = onnx.load(f) # load onnx model
onnx.checker.check_model(model_onnx) # check onnx model
# print(onnx.helper.printable_graph(model_onnx.graph)) # print
# Simplify
if simplify:
try:
import onnxsim
print(f'{prefix} simplifying with onnx-simplifier {onnxsim.__version__}...')
model_onnx, check = onnxsim.simplify(
model_onnx,
dynamic_input_shape=dynamic,
input_shapes={'images': list(img.shape)} if dynamic else None)
assert check, 'assert check failed'
onnx.save(model_onnx, f)
except Exception as e:
print(f'{prefix} simplifier failure: {e}')
def select_device(device='', batch_size=None):
device = str(device).strip().lower().replace('cuda:', '') # to string, 'cuda:0' to '0'
cpu = device == 'cpu'
cuda = not cpu and torch.cuda.is_available()
return torch.device('cuda:0' if cuda else 'cpu')
class SiLU(nn.Module): # export-friendly version of nn.SiLU()
@staticmethod
def forward(x):
return x * torch.sigmoid(x)
class Hardswish(nn.Module): # export-friendly version of nn.Hardswish()
@staticmethod
def forward(x):
# return x * F.hardsigmoid(x) # for torchscript and CoreML
return x * F.hardtanh(x + 3, 0., 6.) / 6. # for torchscript, CoreML and ONNX
def run(weights='', # weights path
img_size=(640, 640), # image (height, width)
batch_size=1, # batch size
device='cpu', # cuda device, i.e. 0 or 0,1,2,3 or cpu
include=('torchscript', 'onnx', 'coreml'), # include formats
half=False, # FP16 half-precision export
inplace=False, # set YOLOv5 Detect() inplace=True
train=False, # model.train() mode
optimize=False, # TorchScript: optimize for mobile
dynamic=False, # ONNX: dynamic axes
simplify=False, # ONNX: simplify model
opset_version=12, # ONNX: opset version
arch='',
head_conv=-1,
model_path='',
ltrb=True,
reid_dim=64,
):
if opt.head_conv == -1: # init default head_conv
opt.head_conv = 256 if 'dla' in opt.arch else 256
num_classes = 1
heads = {'hm': num_classes,
'wh': 2 if not ltrb else 4,
'id': reid_dim}
heads.update({'reg': 2})
t = time.time()
include = [x.lower() for x in include]
img_size *= 2 if len(img_size) == 1 else 1 # expand
file = Path(weights)
# Load PyTorch model
device = select_device(device)
assert not (device.type == 'cpu' and half), '--half only compatible with GPU export, i.e. use --device 0'
model = create_model(arch, heads, head_conv)
model = load_model(model, model_path)
# Input
# gs = int(max(model.stride)) # grid size (max stride)
# img_size = [check_img_size(x, gs) for x in img_size] # verify img_size are gs-multiples
img = torch.zeros(batch_size, 3, *img_size).to(device) # image size(1,3,320,192) iDetection
# Update model
if half:
img, model = img.half(), model.half() # to FP16
model.train() if train else model.eval() # training mode = no Detect() layer grid construction
for k, m in model.backbone.named_modules():
if isinstance(m, Conv): # assign export-friendly activations
if isinstance(m.act, nn.Hardswish):
m.act = Hardswish()
elif isinstance(m.act, nn.SiLU):
m.act = SiLU()
elif isinstance(m, Detect):
m.inplace = inplace
m.onnx_dynamic = dynamic
# m.forward = m.forward_export # assign forward (optional)
# Exports
# if 'torchscript' in include:
# export_torchscript(model, img, file, optimize)
if 'onnx' in include:
export_onnx(model.backbone, img, file, opset_version, train, dynamic, simplify)
# Finish
print(f'\nExport complete ({time.time() - t:.2f}s). Visualize with https://github.com/lutzroeder/netron.')
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='../exp/mot/all_yolov5s/model_60.pth', help='weights path')
parser.add_argument('--img-size', nargs='+', type=int, default=[608, 1088], help='image (height, width)')
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--include', nargs='+', default=['torchscript', 'onnx', 'coreml'], help='include formats')
parser.add_argument('--half', action='store_true', help='FP16 half-precision export')
parser.add_argument('--inplace', action='store_true', help='set YOLOv5 Detect() inplace=True')
parser.add_argument('--train', action='store_true', help='model.train() mode')
parser.add_argument('--optimize', action='store_true', help='TorchScript: optimize for mobile')
parser.add_argument('--dynamic', action='store_true', help='ONNX: dynamic axes')
parser.add_argument('--simplify', action='store_true', help='ONNX: simplify model')
parser.add_argument('--opset-version', type=int, default=12, help='ONNX: opset version')
parser.add_argument('--arch', default='yolo',
help='model architecture. Currently tested'
'resdcn_34 | resdcn_50 | resfpndcn_34 |'
'dla_34 | hrnet_18')
parser.add_argument('--head_conv', type=int, default=-1,
help='conv layer channels for output head'
'0 for no conv layer'
'-1 for default setting: '
'256 for resnets and 256 for dla.')
parser.add_argument('--model_path', default='FairMOT-master/exp/mot/all_yolov5s/model_60.pth',
help='path to pretrained model')
parser.add_argument('--ltrb', default=True,
help='regress left, top, right, bottom of bbox')
parser.add_argument('--reid_dim', type=int, default=64,
help='feature dim for reid')
opt = parser.parse_args()
return opt
def main(opt):
run(**vars(opt))
if __name__ == "__main__":
opt = parse_opt()
main(opt)
但是目前转出来的模型还有点问题,转出来的模型不包括4个检测头,只到特征部分,还差4个头的conv没有包含进去。

















 567
567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









