







本文整理自云杉网络 DeepFlow 产品负责人向阳在 QCon 2023 的演讲分享,主题为 “基于 eBPF 的云原生可观测性深度实践”。
分享从四个方面展开。第一部分回顾分布式追踪的十四年历史,剖析云原生时代下的新痛点。第二部分讲解 AutoTracing —— DeepFlow 基于 eBPF 的一项颠覆性创新,零代码修改实现分布式追踪。第三部分讲解如何结合 OpenTelemetry,发挥两项新技术的特长,实现全栈、全链路的分布式追踪。第四部分展望 DeepFlow 开源社区的未来,开启高度自动化的可观测性新时代。
01|前言
相信大家都有感受,eBPF 最近一年突然火了起来,特别是在可观测性领域。但实际上追溯起来,它的前身 BPF 技术已经有 30 年历史了。我们基于这项有着悠久历史的「新」技术,在它之上做出了一些非常令人激动人心的创新,特别是对 Distributed Tracing 问题给出了一种全新的解法。我相信即使是从世界范围上来讲,我今天分享的内容也能称得上是颠覆性的改变。
今天早上准备演讲时,我还问了一下 ChatGPT,基于它更新到 2021 年的知识体系,我问它 eBPF 能否用于实现 Distributed Tracing?它像模像样的编了一大堆话,不过最终得出了否定的结论,并建议我使用 OpenTracing。
在开始之前我先做一个自我介绍,我从清华大学毕业之后就来到了云杉网络,目前负责云原生可观测性产品 DeepFlow。这个产品其实有些年头了,它诞生于 2016 年,并已经走进了上百个金融、能源、运营商行业的 500 强客户中。去年我们把产品的内核进行了开源,希望它能被更多其他行业、其他国家的用户所知晓。目前开源的时间还不长,7 月份刚有了第一个社区版的 Release,在这里也欢迎大家加入我们的开源社区。
DeepFlow 希望利用以 eBPF 为代表的自动化技术,去降低实现可观测性的复杂度,为开发同学带来自由,促进开发和运维的和睦相处。今天我分享的主角是 eBPF,它带来的安全、灵活的内核可编程能力可以做很多事情,但我今天会聚焦在如何利用它来创新的解决分布式追踪问题上。
首先我会先回顾一下分布式追踪的历史,然后聚焦介绍 DeepFlow 利用 eBPF 做出的酷炫特性,即 AutoTracing,它不用修改任何代码就能实现分布式追踪,然后介绍我们如何将 eBPF 和 OpenTelemetry 这两项技术结合形成令人激动的全栈、全链路分布式追踪方案,最后简单看看 DeepFlow 作为一个可观测性平台的其它能力。
02|分布式追踪:回顾十四年历史,剖析云原生时代的新痛点
相信大家非常熟悉分布式追踪,追踪数据是可观测性三大支柱之一。
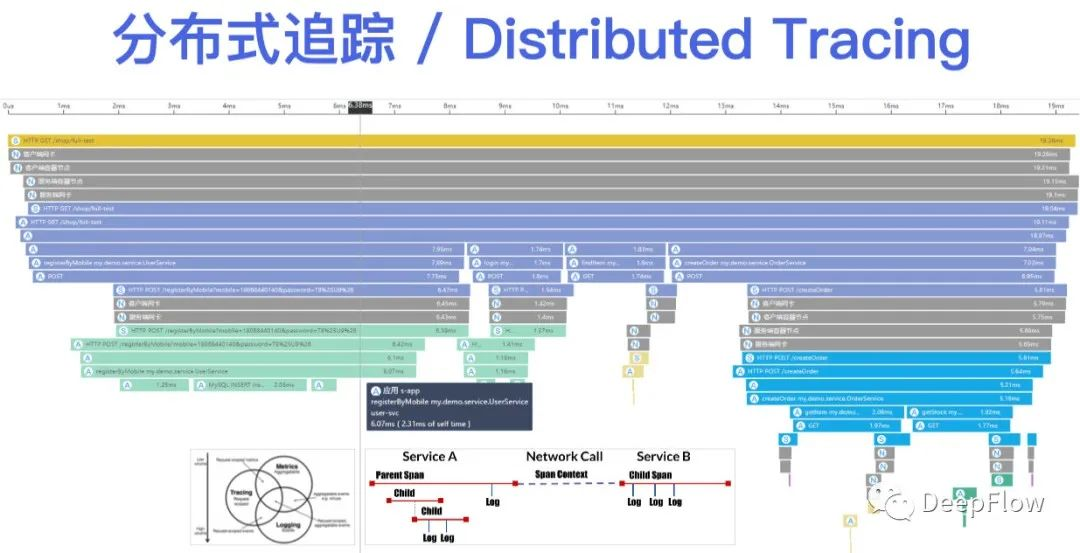
通过采集一个 Trace 在多个进程中的 Span,最终我们能得到这样一个火焰图,它有点类似于我们对单一进程做的 CPU Profile,区别在于分布式追踪是一个聚焦在单次业务请求上的、覆盖多个服务进程的全景火焰图。它从上到下描述了一个分布式应用在服务之间的远程调用关系、服务内部的函数调用关系,它能够快速帮助开发者,特别是由很多个跨团队的微服务开发同学快速确定问题发生的位置,找到对应的负责人。
基于这样的火焰图,我们还可以从中聚合出一些应用性能指标,比如说每个服务的吞吐、时延、异常,以及服务之间的访问关系拓扑等。

一般认为分布式追踪可以追溯到 Google 的 Dapper 论文上,这个论文是 2010 年发表的,论文里讲到 Google 从 2008 年开始做 Dapper 这个系统,解决 Google 内部微服务调用追踪的问题。受这篇论文启发,开源社区诞生了一批优秀的项目,例如非常火的 Apache SkyWalking 就是聚焦在这个问题上。
再到最近几年,开发者们发现插桩这件事应该要标准化、自动化,因为它侵入了业务程序中,随着开发语言、微服务框架越来越多样化,开发者们不希望因为插桩这件事去太多修改业务代码,在这个驱动力之下诞生了 OpenTracing,进而发展为 OpenTelemetry。

我们发现在云原生时代,分布式追踪这件事变得越来越迫切,也遇到越来越严峻的挑战。首先,随着服务拆成,单个微服务的业务代码会越来越简单,同时有一部分公共逻辑会逐渐的卸载到基础设施中,比如说通过服务网格或 API 网关实现。因此微服务会越来越轻,开发写的代码会越来越聚焦在业务逻辑方面,这是一个趋势。
另外一点是微服务技术栈的多样性,如果微服务变得越来越简单了,开发同学就会有越来越多的自由,可以选择自己比较喜欢的框架和语言。但是这会导致一个问题,分布式追踪在这种场景下越来越不容易全面覆盖。有一个以往我们很喜欢的东西,Java Agent,它可以做到无侵扰的插码,在对业务代码无修改的情况下实现一定程度上的分布式追踪能力。
但是一方面注入 JavaAgent 还是需要重启业务进程,另一方面在其它语言中一般不存在类似的字节码注入机制,比如说对于 Golang。假设你是公司内部的基础设施开发团队,你负责开发维护 Golang 的 SDK 去做 Instrumentation,可以想象在 SDK 每发布一个新版本之后,都需要漫长的时间来让公司里众多业务部门将 SDK 更新到新版本,这个时间可能会长达半年甚至一年,是一个非常漫长非常无奈的过程。因此,大家几乎有一个共识,现有的依靠插码的分布式追踪,落地起来还是很有难度的,是一项需要协调所有业务开发部门的工作。
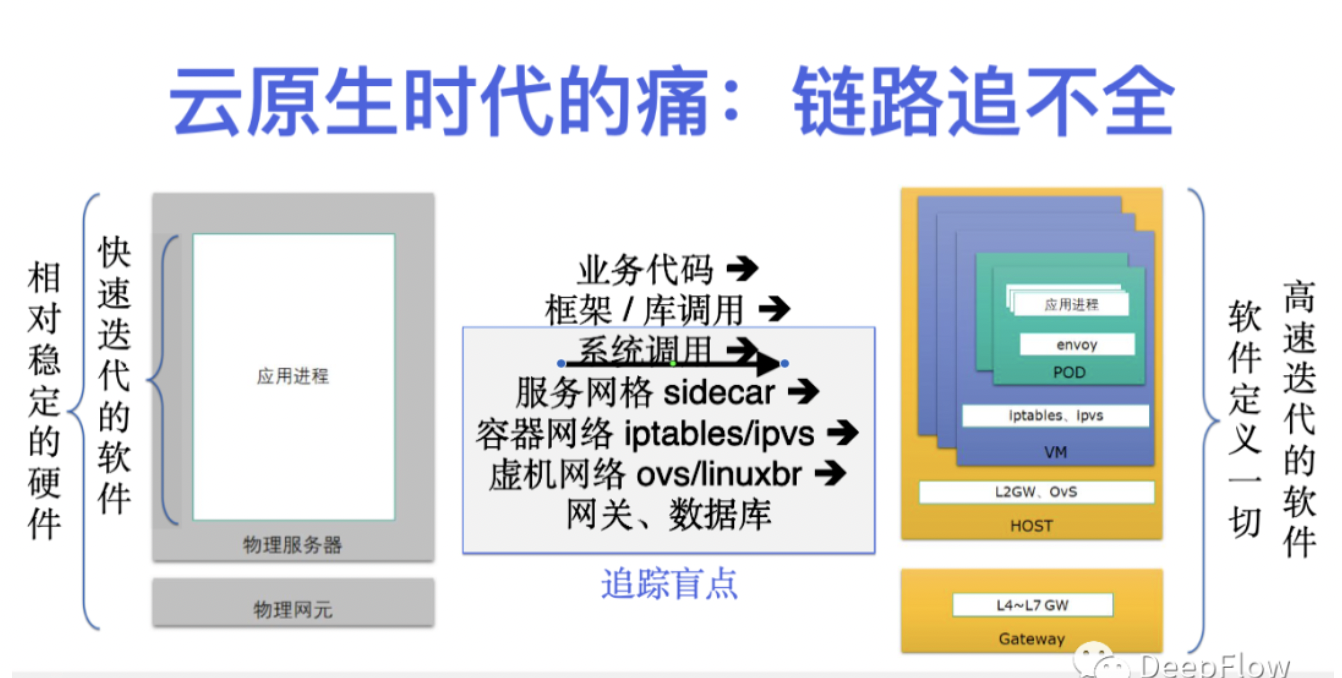
再说说云原生时代的另外一个趋势,通信路径的复杂性。以往服务之间的通信路径非常简单,最早的时候可能是两台服务器通过网线和交换机直接连起来,甚至是在同一台服务器上通过本地 Socket 直接通信。但在云原生时代,开发同学会发现两个服务之间可能跨越了千山万水,有 Pod 里面的 Service Mesh Sidecar、云服务器中的虚拟网桥、KVM 宿主机上虚拟交换机,还有大量的四七层网关、消息队列、中间件等等,通信路径非常复杂。
与此同时,几乎所有的分布式追踪机制其实都只聚焦在业务代码、框架 / 库函数两个层面,对服务之间的通信路径缺乏覆盖。然而,在微服务数量从 1 增长到 N 的过程中,服务之间通信路径的复杂度极端情况下可能增长了 N^2,复杂度的增长达到了几个数量级。造成的后果是,业务出现问题之后,依靠现有的分布式追踪能力开发同学往往找不到问题所在,越是聚焦在业务开发的同学,对于底层的这些云原生基础设施会了解的越少。
我们发现经常发生的经典故事是,开发难以回答到底是自己的问题、上下游服务的问题,还是基础设施的问题。由于分布式追踪无法覆盖云原生基础设施中的通信路径,这个问题往往无法回答,导致一个工单来回在不同团队之间无效流转。
是的,上面这些就是我们的现状,微服务越来越多样,通信路径越来越复杂,导致了分布式追踪越来越重要,但又越来越难以追全。
03|AutoTracing:基于 eBPF,零代码修改实现分布式追踪
铺垫了这么多,下面介绍今天的主角,DeepFlow 基于 eBPF 做的一个非常酷的能力 AutoTracing,即零代码修改、零应用发布、零进程重启的分布式追踪能力。
上面这个图是去年截的,贴的是 Google 的搜索结果,如果今年再写 PPT 的话应该要贴 ChatGPT 的图了。从图中可以看到搜索
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1596
1596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









