







《统计学习方法(第二版)》李航 读书笔记 (8)
第5章 决策树 以及典型算法ID3、C4.5和CART
分类决策树模型是一种描述对实例进行分类的树形结构。由结点和有向边组成。内部节点表示一个特征或树形,叶结点表示一个类。路径上内部结点的特征对应着规则的条件,而叶结点的类对应着规则的结论。
决策树学习本质上是从训练数据集中归纳出一组分类规则。归纳学习由于依赖于检验数据,因此又称为检验学习。
归纳学习存在一个基本的假设:
任一假设如果能够在足够大的训练样本集中很好的逼近目标函数,则它也能在未见样本中很好地逼近目标函数。该假定是归纳学习的有效性的前提条件。(这个有点像大数定律)
特征选择
选取对训练数据具有分类能力的特征
在信息论与概率统计中,熵(entropy)是表示随即变量不确定性的度量。
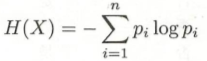
对数以2为底或者以e为底,熵的单位分别是比特bit或纳特nat。由定义就可以知道,熵只依赖于X的分布,而与X的取值无关。
熵越大,随机变量的不确定性就越大。![]()
随机变量X给定条件下随机变量Y的条件熵,定义为X给定条件下Y的条件概率分布的熵对X的数学期望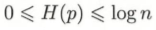
信息增益
特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)的差,即g(D,A)= H(D)- H(D|A)
熵H(Y)与条件熵H(Y|X)之差称为互信息(mutual information),决策树中的信息增益等价于训练数据集中类与特征的互信息。
算法5.1 信息增益的算法
输入:训练数据集D和特征A
输出:g(D,A&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 829
829











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









