序
有些网站需要用户登录,利用python实现知乎网站的模拟登录。用Cookies记录登录信息, 然后就可以抓取登录之后才能看到的信息。
知乎登录首页
第一、使用Fiddler观察“登录”浏览器行为
打开工具Fiddler,在浏览器中访问https://www.zhihu.com,Fiddler 中就能看到捕捉到的所有连接信息。在左侧选择登录的那一条:
观察右侧,打开 Inspactors 透视图, 上方是该条连接的请求报文信息, 下方是响应报文信息:

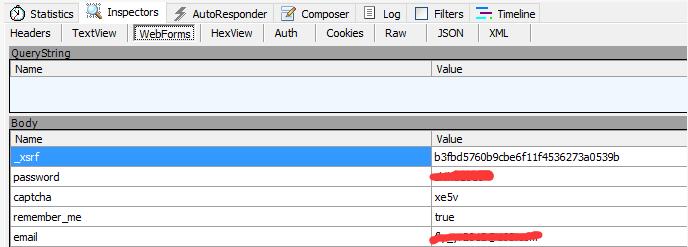
1.2 用户登录信息
1.3 Raw显示请求报头原文

1.4下方:回应报文

第二、Python实现
2.1 抓取知乎首页
简单的写一个 GET 程序, 把知乎首页 GET 下来, 然后 decode() 一下解码, 结果报错. 仔细一看, 发现知乎网传给我们的是经过 gzip 压缩之后的数据. 这样我们就需要先对数据解压. Python 进行 gzip 解压很方便, 因为内置有库可以用. 代码片段如下:
import gzip
def ungzip(data):
try:
print('正在解压.....')
data = gzip.decompress(data)
print('解压完毕!')
except:
print('未经压缩, 无需解压')
return data
通过 opener.read() 读取回来的数据, 经过 ungzip 自动处理后, 再来一遍 decode() 就可以得到解码后的 str 了。
2.2 使用正则表达式获取_xsrf
_xsrf 这个键的值在茫茫无际的互联网沙漠之中指引我们用正确的姿势来登录知乎. 如果没有 _xsrf, 我们或许有用户名和密码也无法登录知乎。 如上文所说, 我们在第一遍 GET 的时候可以从响应报文中的 HTML 代码里面得到这个值. 如下函数实现了这个功能, 返回的 str 就是 _xsrf 的值.
import re
def getXSRF(data):
cer = re.compile('name=\"_xsrf\" value=\"(.*)\"', flags = 0)
strlist = cer.findall(data)
return strlist[0]
2.3 发射Post
集齐 _xsrf, id, password 三大法宝, 我们可以发射 POST 了. 这个 POST 一旦发射过去, 我们就登陆上了服务器, 服务器就会发给我们 Cookies. 本来处理 Cookies 是个麻烦的事情, 不过 Python 的 http.cookiejar 库给了我们很方便的解决方案, 只要在创建 opener 的时候将一个 HTTPCookieProcessor 放进去, Cookies 的事情就不用我们管了. 下面的代码体现了这一点.
import http.cookiejar
import urllib.request
def getOpener(head):
cj = http.cookiejar.CookieJar()
pro = urllib.request.HTTPCookieProcessor(cj)
opener = urllib.request.build_opener(pro)
header = []
for key, value in head.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
return opener
getOpener 函数接收一个 head 参数, 这个参数是一个字典. 函数把字典转换成元组集合, 放进 opener. 这样我们建立的这个 opener 就有两大功能:
- 自动处理使用 opener 过程中遇到的 Cookies;
- 自动在发出的 GET 或者 POST 请求中加上自定义的 Header;
2.4 完整爬虫代码
'''
登录
对于需要用户登录的网站信息的爬取
'''
import urllib.request,gzip,re,http.cookiejar,urllib.parse
import sys
def ungzip(data):
try:
print("正在解压缩...")
data = gzip.decompress(data)
print("解压完毕...")
except:
print("未经压缩,无需解压...")
return data
def getOpener(header):
cookieJar = http.cookiejar.CookieJar()
cp = urllib.request.HTTPCookieProcessor(cookieJar)
opener = urllib.request.build_opener(cp)
headers = []
for key,value in header.items():
elem = (key,value)
headers.append(elem)
opener.addheaders = headers
return opener
def getXsrf(data):
cer = re.compile('name=\"_xsrf\" value=\"(.*)\"',flags=0)
strlist = cer.findall(data)
return strlist[0]
headers = {
'Connection': 'Keep-Alive',
'Accept': '*/*',
'Accept-Language':'zh-CN,zh;q=0.8',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.63 Safari/537.36',
'Accept-Encoding': 'gzip, deflate,br',
'Host': 'www.zhihu.com',
'DNT':'1'
}
url = "https://www.zhihu.com/"
req=urllib.request.Request(url,headers=headers)
res=urllib.request.urlopen(req)
data = res.read()
data = ungzip(data)
_xsrf = getXsrf(data.decode('utf-8'))
opener = getOpener(headers)
url+='login/email'
name='**********'
passwd='*****'
postDict={
'_xsrf':_xsrf,
'email':name,
'password':passwd,
'remember_me':'true'
}
postData=urllib.parse.urlencode(postDict).encode()
res=opener.open(url,postData)
data = res.read()
data = ungzip(data)
print(data.decode())























 745
745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









