









深入浅出视觉分割大模型SAM(原理解析+代码实践)
大家好,这里是肆十二,近两年来大模型的成果在一些领域的应用已经深入人心,由于我本人主要感兴趣的方向为计算机视觉,所以今天我们来一起看下计算机视觉领域中这个非常精彩的大模型-SAM。我在B站也同步更新了对应的讲解视频,感兴趣的小伙伴也可以按照视频来进行操作。
随着大语言模型的爆火,现在各种大模型层出不穷,比较著名的有非常牛逼的chatgpt,我们国内也有一些类似的大模型,比如百度的文心一言和清华的kimi,这些大语言模型也逐渐慢慢成为观众老爷们生活学习不可缺少的一个小组件,尤其是看我视频的观众老爷们,肯定经常使用这些大模型来完成自己的作业。
因为我们平时讲的主要内容都是计算机视觉,所以我们本次想和大家描述的这个大模型也是计算机视觉领域的大模型,SAM,或者叫做segment anything model。老规矩,我们还是先来看一下SAM模型能够做什么。
开始之前,我们还是先看一下SAM的效果。SAM由META的工作人员开发,其中论文的作者里面就有RCNN的作者Ross Girshick。开发团队不仅仅提供了源码,同时也提供了一些在线的案例,大家在直接在下面这个网址进行测试。
-
通过单个point作为提示词来进行物体的分割,比如下面的飞机

-
可以通过边界框作为提示词来进行分割

-
可以通过全局的网格点对全部的物体进行分割,在全局上生成32x32的网格点然后进行边界框的分割


-
或者是通过文本的形式进行提示来进行分割,这个部分demo中没有实现,具体可以参考论文。
OK,看到了上面的简单介绍之后,我们来对他的原理进行剖析。
首先,大模型兴起于NLP,自然语言处理领域。在自然语言处理中,有很多称为基础模型的模型,比如谷歌的BERT以及OpenAI的gpt,都是基础模型,这些基础模型输入是一段话,输出呢也是一段话,我们将这样的模型称为seq2seq,也就是序列预测,有了这些基础模型之后,就可以很方便地甚至不需要训练就能迁移到翻译或者文本摘要这种常规的自然语言处理的任务上。那这种基础模型是如何来进行训练的呢,训练离不开数据,各位在进行yolo模型训练的时候肯定也被数据标注折磨过,一张张的标注属于你任务的数据之后才能用于模型的训练,如果你标注的数据比较少的话,那训练的效果可能还比较差。对于自然语言处理的这种基础模型而言,有个比较方便的一点是无需人工标注,只需要从网络上搜集大量的文本即可,搜集文本之后,随机扣掉这段话中的部分单词作为输入,你得输出则是尽可能地将这些这些扣掉的词预测出来,这种方式是不是和你在高中英语中做的完型填空类似,由于你是那现成的文本扣掉部分单词来作为输入,你只需要写个简单的脚本随机扣掉这些单词就能制作一份巨大的数据集,完全不需要人工进行大量的标注,其中这种方式也就是大名鼎鼎的bert所使用的方式,感兴趣的小伙伴可以去读一下这篇文章,地址在这里。
在计算机视觉的领域中,也有使用类似方法来进行训练的模型,就是有何凯明提出的MAE,注意,这里的这个作者同时也是resnet的作者。他的做法是将图像随机扣除部分块,然后将他进行还原,通过这种方式来进行训练也不需要进行标注。感兴趣的小伙伴可以去看mae这篇论文,地址在下面这个位置。
mae: [2111.06377] Masked Autoencoders Are Scalable Vision Learners (arxiv.org)
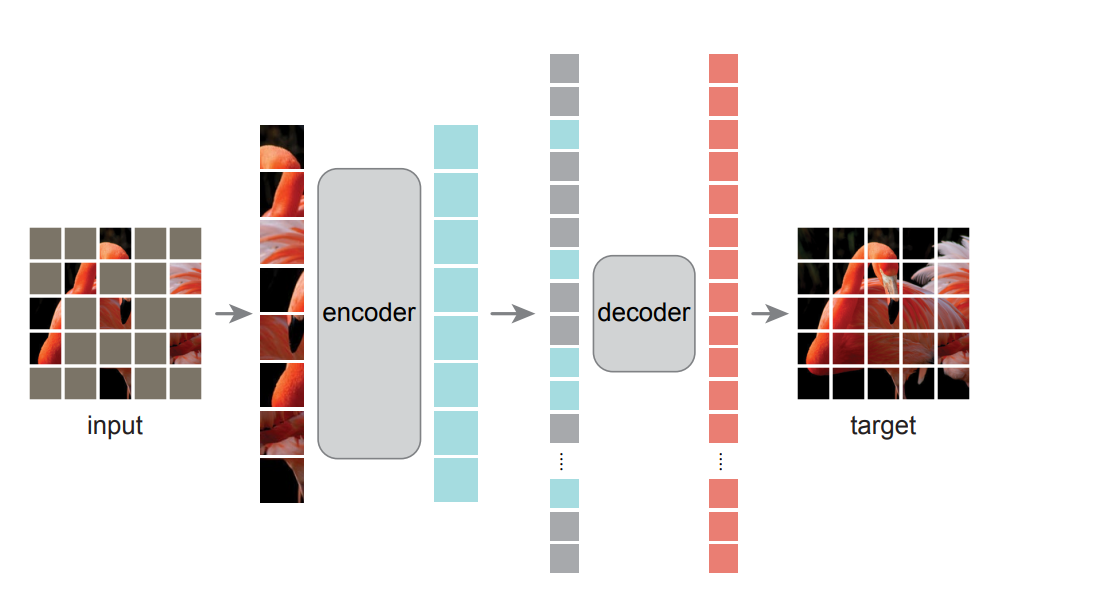
以上两个模型分别是NLP领域和CV领域的基础模型。OK,有了这些基础模型,我们就可以进行零样本的学习来适配到下游的任务上了。对于自然语言处理而言,这里的下游任务可以是翻译,可以是文本摘要。对于计算机视觉而言,这里的下游任务可以是分割,可以是检测。其中进行零样本学习的常用方面就是提示词工程,也就是你在chatgpt中经常听到的prompting。其中chatgpt就是类似于这种的形式,举个例子。
比如我们在文心一言中询问这样的一个问题。
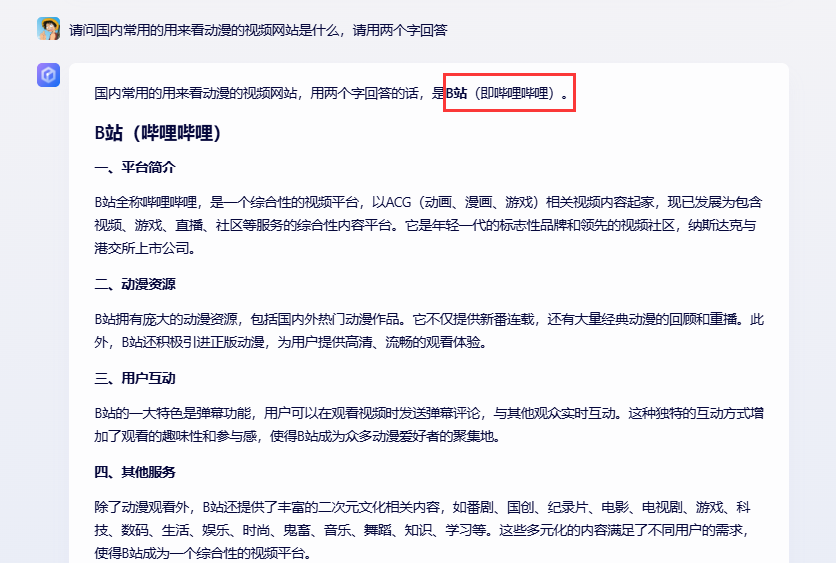
你会发现,他回答问题不是一次给出结果的,好像人在打字一样,一点点给出结果,大概的简化之后的原理是这样的。
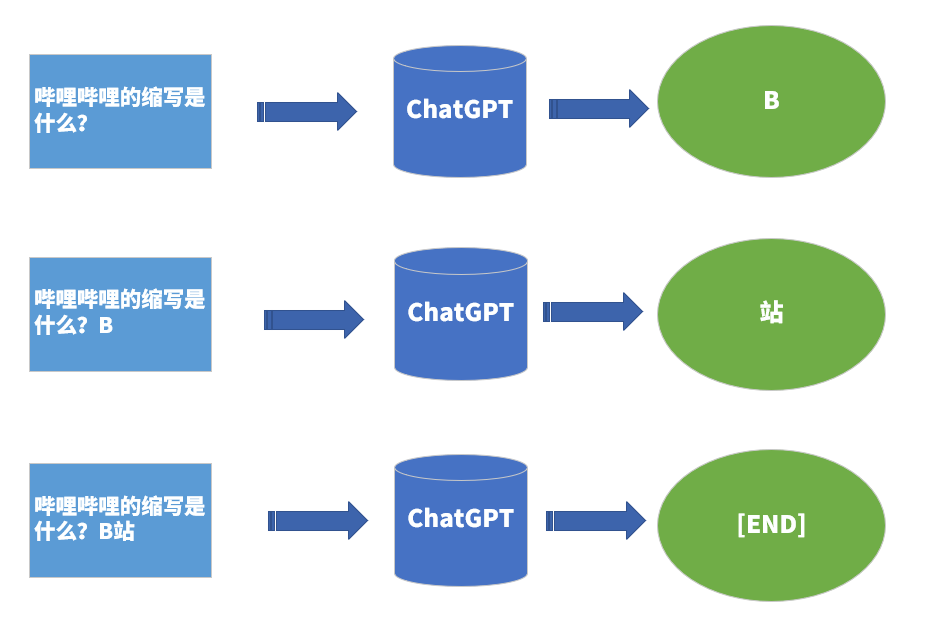
通过不断地输入到这种模型当中,这个模型就能不断的生成,直到遇到结束符号为止,是不是很神奇。当然,这只是一个简单的示例,为了让他的回答更像人以及让他的回答更有创造性,在选词的时候会加入一些随机性的策略,感兴趣的小伙伴可以去看下chatgpt的技术报告,里面给了比较详细的描述。
关于大模型是如何进行训练的呢,这里参考李宏毅老师的一张PPT,以chatgpt为例,他的训练模型基本分为了三个阶段。
说了这么多,终于回到我们SAM模型上来,有了NLP任务的参考。研究人员就想能不能把同样的方式应用在计算机视觉的领域上来。对于计算机视觉的任务,希望以图像建立一个类似这样的模型,然后迁移到其他任务上面,其中在计算机视觉的任务中,最难的就是分割了,分割要找到物体的轮廓。视觉和语言不一样,我们要处理的是图像,有了处理的图像,我们还缺少提示,那这样提示可以是什么样子的方式呢。OK,就让我们正式进入这篇论文。
在NLP的领域中,存在一些被称为基础模型的模型,他们通过预测句子中的下一个词进行训练,称为顺序预测。通过这些基础的模型可以轻松地适应到其他的NLP的任务上,比如翻译或者是文本摘要,这种实现方式也可以称为是零样本迁移学习。其中比较著名的方法就是prompting,通过聊天的形式来进行交互。NLP有效的前提是网络上存在大量的文本,而对于序列的预测,比如说知道一些词然后预测后面的词是什么,这种不需要人工标注的标签就能完成训练。但是问题转化到计算机视觉的任务上,尽管网络上存在数十亿的图像,但是由于缺乏有效标注的mask的信息,所以在计算机视觉的任务上建立这样模型成为了挑战。开门见山,作者首先提出了三个问题。

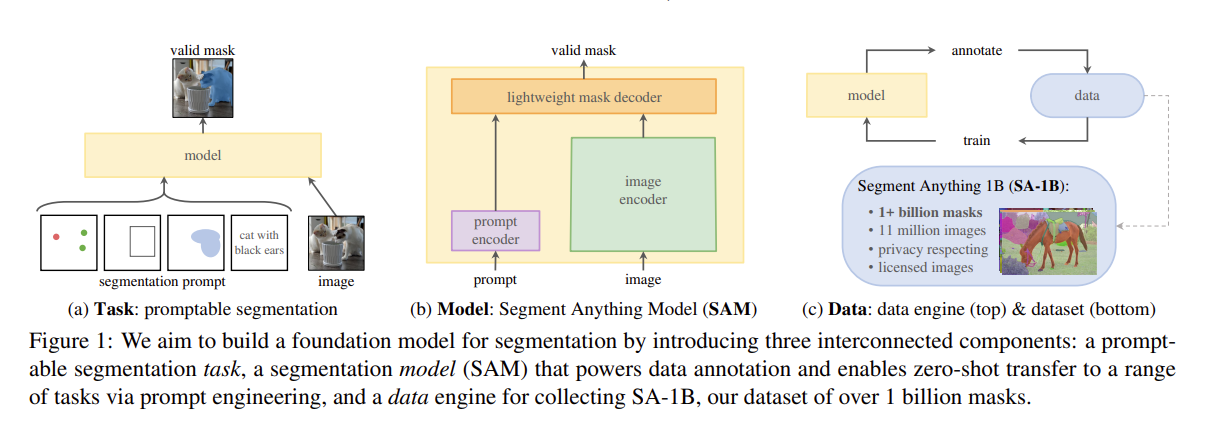
针对上面提出的3个问题,作者给出的解决方案。作者的目标是通过引入三个相互关联的组件来构建一个分割的基础模型:一个可提示的分割任务、一个通过数据标注提供动力并能够通过提示工程实现一系列任务零样本迁移的分割模型(SAM),以及一个用于收集我们的数据集SA-1B(包含超过10亿个掩码)的数据引擎。
只能说大佬的思路足够清晰,先提出问题,然后根据问题给出解决方案,非常之自然。
论文解析
下面我们分别对3个子模块来进行解析。
分割一切的任务
在自然语言处理(NLP)领域,乃至最近的计算机视觉领域,基础模型都是一种很有前景的发展方向,通常通过使用“提示”技术,能够对新的数据集和任务进行零样本和少量样本的学习。受这一工作方向的启发,我们提出了可提示的分割任务,其目标是在给定任何分割提示的情况下返回一个有效的分割掩码(见图1a)。提示简单地指定了图像中要分割的内容,例如,提示可以包括标识对象的空间或文本信息。有效输出掩码的要求意味着,即使提示含糊不清且可能指代多个对象(例如,衬衫上的一个点可能表示衬衫或穿衬衫的人),输出也应该是其中至少一个对象的合理掩码。我们将可提示的分割任务既用作预训练目标,也用作通过提示工程解决一般的下游分割任务的方法。
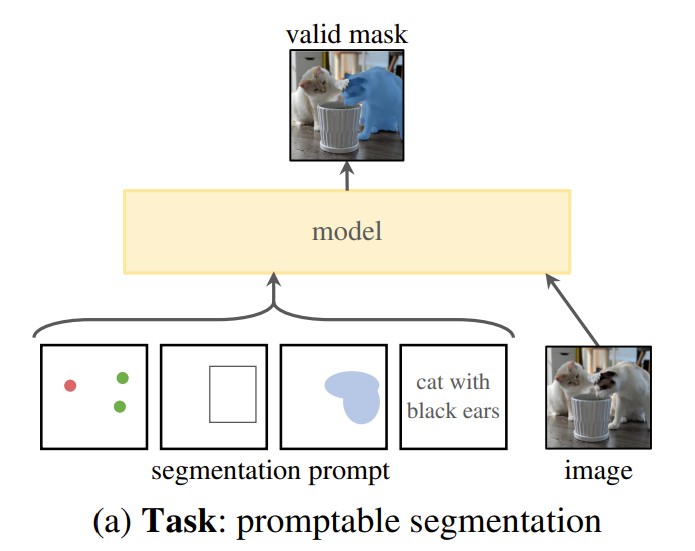
参考这种提示词工程的做法,给定一张图片和给定对应的提示信息,得到对应位置的mask区域。这里的提示信息可以是mask、points、box或者是text,如果是mask的话则使用卷积来进行表示,如果是其余的三种提示词则使用位置编码的形式来进行表示,其中text可以通过clip一类的模型获取词嵌入。其中主干网络的部分使用的特征提取能力更强的VIT网络,整体的构思如下:
分割一切的模型
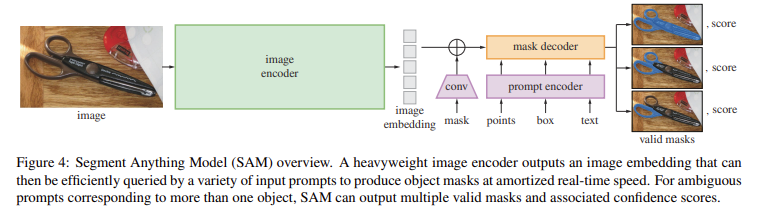
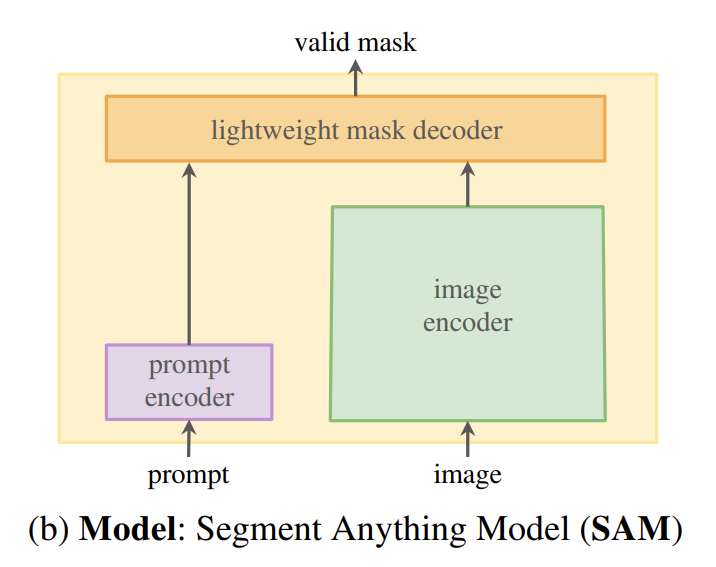
可提示的分割任务和实际使用目标对模型架构施加了约束。具体而言,模型必须支持灵活的提示,需要以分摊的实时方式计算掩码以允许交互式使用,并且必须具备处理歧义的能力。令人惊讶的是,我们发现一个简单的设计就能满足所有这三个约束条件:一个强大的图像编码器计算图像嵌入,一个提示编码器嵌入提示,然后将这两个信息源在一个轻量级的掩码解码器中结合起来,预测分割掩码。我们将此模型称为“任意分割模型”或SAM(见图1b)。通过将SAM分离为图像编码器和快速的提示编码器/掩码解码器,可以使用不同的提示重复使用相同的图像嵌入(并分摊其成本)。给定图像嵌入,提示编码器和掩码解码器可以在网页浏览器中在约50毫秒内从提示预测掩码。我们专注于点、框和掩码提示,并展示了使用自由形式文本提示的初步结果。为了使SAM具备处理歧义的能力,我们设计它针对单个提示预测多个掩码,从而使SAM能够自然地处理歧义,例如衬衫与人之间的示例。
-
图像的编码器:
图像编码器。出于可扩展性和强大的预训练方法的考虑,我们使用了一个经过最小调整以适应高分辨率输入的MAE预训练视觉Transformer(ViT)[33][62]。图像编码器每张图像运行一次,并可在提示模型之前应用,这里使用的mae来进行预训练。(PS: 之前有个想法是使用mae先预训练一个模型出来,但是明显这个想法是使用在这个模型里面的,所以多读书是非常必要的)
-
提示词的编码器:
提示编码器。我们考虑两组提示:稀疏提示(点、框、文本)和密集提示(掩码)。我们用位置编码[95]来表示点和框,并将其与每种提示类型的学习嵌入和来自CLIP的现成文本编码器中的自由格式文本相加。密集提示(即掩码)使用卷积进行嵌入,并与图像嵌入进行逐元素相加。
-
掩码的解码器:
掩码解码器能够高效地将图像嵌入、提示嵌入和输出标记映射到一个掩码。采用了一个经过修改的Transformer解码器块,后面跟着一个动态掩码预测头。我们修改后的解码器块在两个方向上(从提示到图像嵌入和从图像嵌入到提示)使用提示自注意力和交叉注意力来更新所有嵌入。运行两个块之后,我们对图像嵌入进行上采样,并且一个多层感知机(MLP)将输出标记映射到一个动态线性分类器,然后该分类器计算图像每个位置的前景掩码概率。
-
解决歧义的问题:
解决歧义问题。如果给定一个模糊的提示,模型将平均多个有效的掩码作为一个输出。为了解决这个问题,我们修改了模型,使其能够针对单个提示预测多个输出掩码(见图3)。我们发现,3个掩码输出足以处理大多数常见情况(嵌套掩码通常最多有三层:整体、部分和子部分)。比如上面的剪刀的图像,其实由三个有效的掩码。
数据引擎
为了实现对新数据分布的强泛化能力,我们发现有必要在比任何现有分割数据集都更大且多样化的掩码集上训练SAM。虽然基础模型的典型方法是在线获取数据[82],但掩码并不是自然丰富的,因此我们需要一种替代策略。我们的解决方案是构建一个“数据引擎”,即我们与模型内循环数据集标注(见图1c)共同开发我们的模型。我们的数据引擎有三个阶段:辅助手动、半自动和全自动。在第一阶段,SAM辅助标注者标注掩码,类似于经典的交互式分割设置。在第二阶段,SAM可以通过提示可能的对象位置自动为一部分对象生成掩码,而标注者则专注于标注剩余的对象,这有助于增加掩码的多样性。在最后阶段,我们使用前景点的常规网格提示SAM,平均每张图像生成约100个高质量掩码。
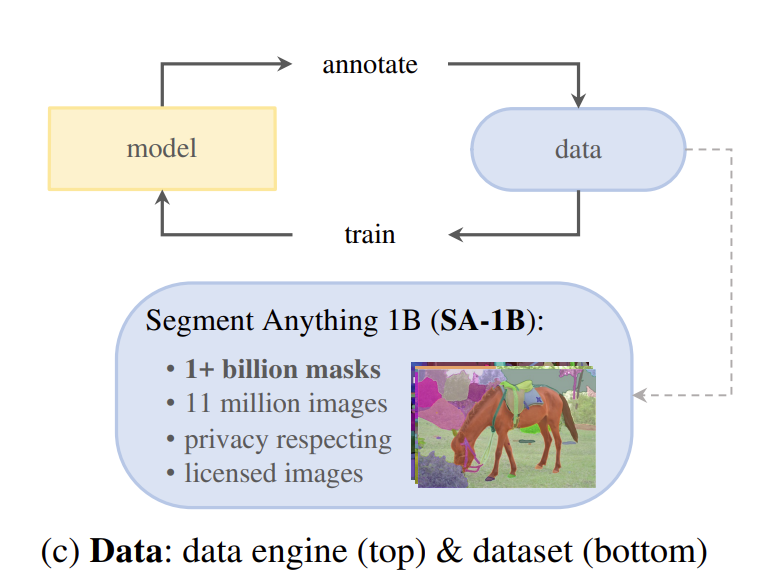
数据引擎分为3个阶段
-
第一个阶段
使用公开的数据集进行分割,并让模型和标注专家进行互动,标注专家使用浏览器通过擦除或者绘画画布来纠正模型输出的掩码。在第一阶段,类似于经典的交互式分割,一组专业标注者使用由SAM支持的基于浏览器的交互式分割工具,通过点击前景/背景对象点来标注掩码。可以使用像素精确的“画笔”和“橡皮擦”工具来完善掩码。我们的模型辅助标注在浏览器内实时运行(使用预计算的图像嵌入),从而实现了真正的交互式体验。我们没有对标注对象施加语义约束,标注者可以自由标注“材质”和“物体”[1]。我们建议标注者标注他们能够命名或描述的对象,但没有收集这些名称或描述。标注者被要求按照突出程度顺序标注对象,并且如果标注一个掩码需要超过30秒,就会被鼓励继续标注下一张图像。
-
第二个阶段
第二个阶段在第一个阶段的基础之上更关注模型的细节。在这一阶段,我们的目标是增加掩码的多样性,以提高我们的模型分割任何物体的能力。为了让标注者关注不太突出的物体,我们首先自动检测置信度高的掩码。然后,我们向标注者展示预填充了这些掩码的图像,并要求他们标注任何其他未标注的物体。为了检测置信度高的掩码,我们使用通用的“物体”类别,在所有第一阶段的掩码上训练了一个边界框检测器[84]。在这一阶段,我们在18万张图像中额外收集了590万个掩码(总共1020万个掩码)。与第一阶段一样,我们定期在新收集的数据上重新训练我们的模型(5次)。由于这些物体更难标注,每个掩码的平均标注时间回升至34秒(不包括自动掩码)。每张图像的平均掩码数量从44个增加到72个(包括自动掩码)。
-
第三个阶段
第三个阶段引入32X32的常规网格作为输入提示,这个阶段涵盖物体的部分、子部分和整体。在最后阶段,标注是完全自动的。这得益于我们模型的两大改进。首先,在这一阶段开始时,我们已经收集了足够的掩码来极大地改进模型,包括上一阶段的各种掩码。其次,到这一阶段,我们已经开发了具有歧义感知能力的模型,这使得我们即使在存在歧义的情况下也能预测出有效的掩码。具体来说,我们用32×32的常规网格点来提示模型,并为每个点预测一组可能对应有效物体的掩码。借助具有歧义感知能力的模型,如果一个点位于某个部分或子部分上,我们的模型将返回子部分、部分和整个物体。我们使用模型的交并比(IoU)预测模块来选择置信度高的掩码;此外,我们只识别和选择稳定的掩码(我们认为,如果在0.5−δ和0.5+δ的概率图上应用阈值处理能得到相似的掩码,则该掩码是稳定的)。最后,在选择置信度高且稳定的掩码后,我们应用非极大值抑制(NMS)来过滤重复的掩码。为了进一步提高较小掩码的质量,我们还处理了多个重叠的放大图像裁剪。有关此阶段的更多详细信息,请参见附录B。我们将全自动掩码生成应用于数据集中的所有1100万张图像,总共生成了11亿个高质量的掩码。接下来,我们将描述并分析所得的数据集SA-1B。
最终在1100w张图片上生成了11亿个掩码,称为SA-1B数据集。
最后完成零样本迁移的任务,任务的类型有以下几种。
实验结果
采用了零样本的学习方式,并且进行预测的图像是没有在文中提到的SA-1B数据集出现过的。我们展示了一系列实验,这些实验涵盖了低、中、高级别的图像理解,并大致与该领域的历史发展并行。具体来说,我们提示SAM执行以下任务:(1)执行边缘检测,(2)分割所有内容,即生成对象提议,(3)分割检测到的对象,即实例分割,以及(4)作为概念验证,从自由格式的文本中分割对象。这四个任务与SAM训练时的可提示分割任务显著不同,并通过提示工程实现。我们的实验以消融研究结束。
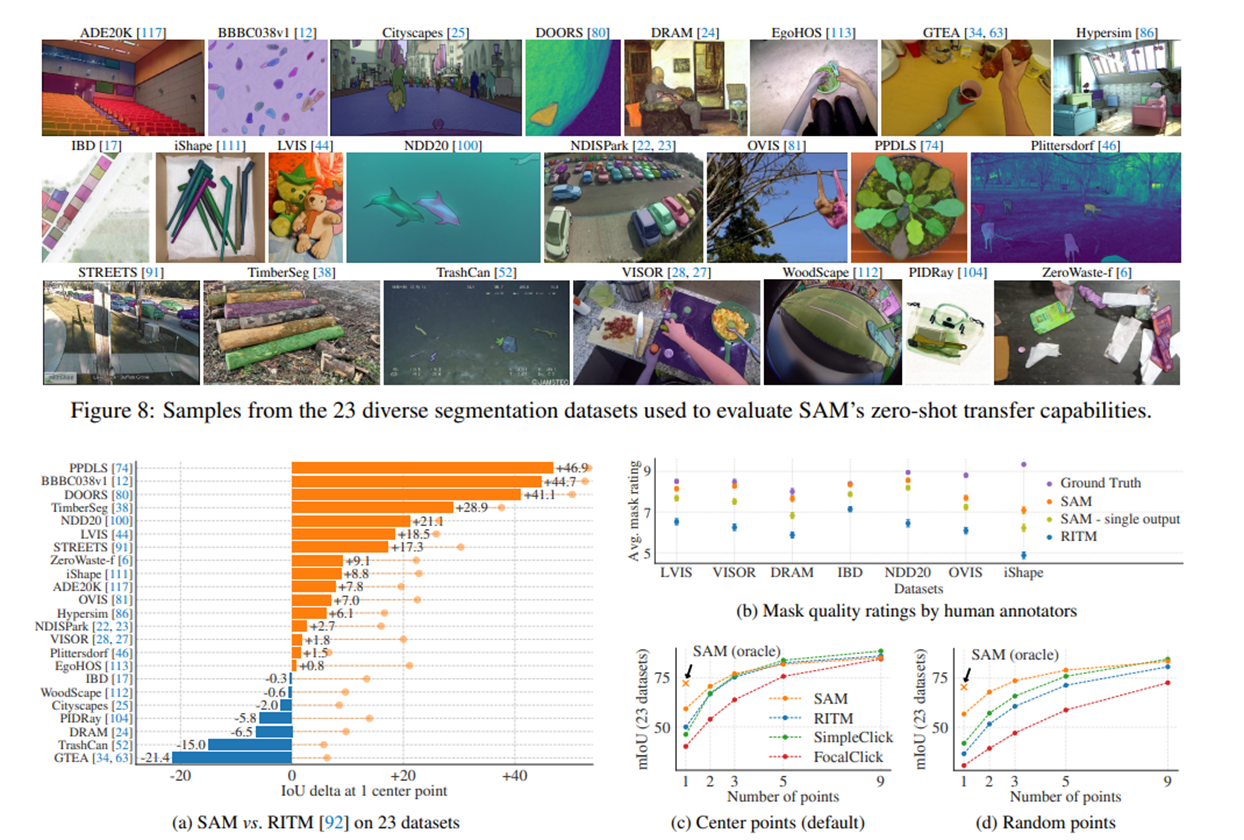
单点语义分割
按照交互式分割[92]中的标准评估协议,从真实掩码的“中心”(在掩码内部距离变换的最大值处)采样点。由于SAM能够预测多个掩码,我们默认情况下仅评估模型最具置信度的掩码。所有基线方法都是单掩码方法。我们主要与RITM[92]进行比较,这是一种强大的交互式分割器,与其他强大的基线[67, 18]相比,在我们的基准测试中表现最佳。
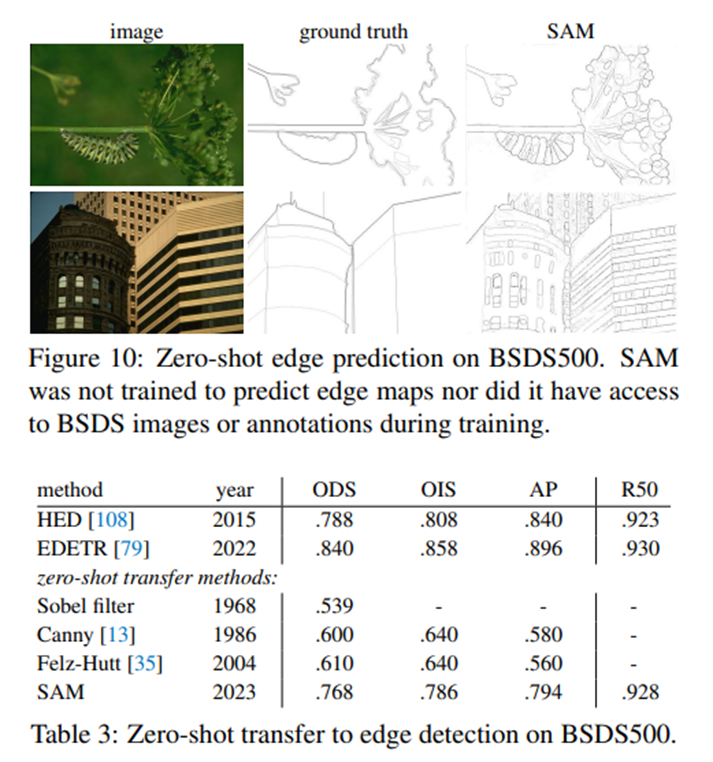
边缘检测
我们使用了简化版的自动掩码生成流程。具体来说,我们用16×16的常规前景点网格来提示SAM,生成了768个预测的掩码(每个点3个)。通过非极大值抑制(NMS)去除冗余的掩码。然后,使用未阈值化的掩码概率图的Sobel滤波和标准轻量级后处理(包括边缘NMS,详见附录D.2)来计算边缘图。
简单总结来说就是先通过网格点作为提示来生成掩码,最后通过滤波和后处理完成物体边缘的提取。
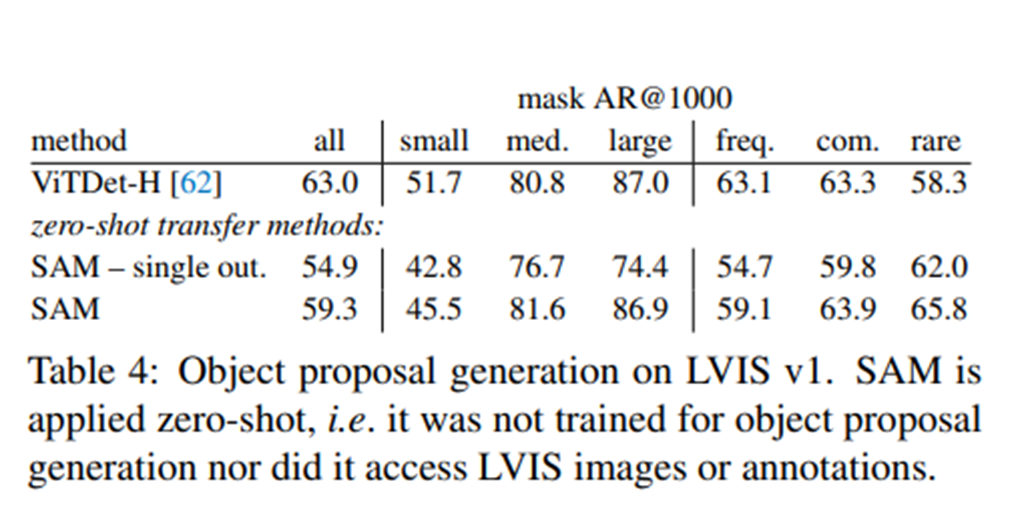
提议边界框
将前面的流程稍作修改,变为计算输出掩码的边界框的形式。
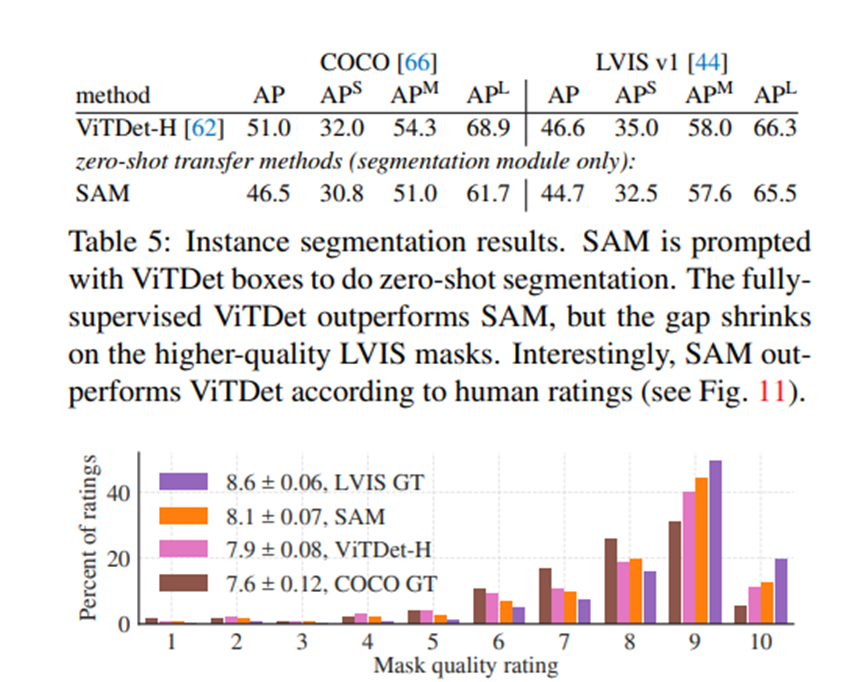
实例分割
转向更高级别的视觉任务,我们使用SAM作为实例分割器的分割模块。实现过程很简单:我们运行一个目标检测器(之前使用的ViTDet),并用其输出的边界框来提示SAM。这说明了如何在一个更大的系统中组合使用SAM。
文本生成图像
首先通过CLIP等模型生成词嵌入,作为提示词输入到SAM模型中,得到对应物体的MASK。我们考虑了一个更高层次的任务:从自由格式的文本中分割对象。这个实验证明了SAM处理文本提示的能力。虽然在之前的所有实验中我们都使用了完全相同的SAM,但在这个实验中,我们对SAM的训练过程进行了修改,使其能够识别文本,但这种方式并不需要新的文本注释。具体来说,对于每个手动收集的面积大于1002的掩码,我们提取CLIP图像嵌入。然后,在训练过程中,我们将提取的CLIP图像嵌入作为SAM的第一次交互。这里的关键观察是,由于CLIP的图像嵌入是与其文本嵌入对齐的,因此我们可以使用图像嵌入进行训练,但使用文本嵌入进行推理。也就是说,在推理时,我们将文本通过CLIP的文本编码器运行,然后将得到的文本嵌入作为提示给SAM(详见附录D.5)。
从实验中可以看出,通过文本加点的集合可以帮助模型输出更完美的mask,如果只是通过文本的话分割的情况有限。

项目实战
为了方便大家使用,我在原始的代码上进行了修改,可以方便地对上面的案例进行预测:
环境配置
# 安装并激活对应的虚拟环境
conda create -n sam python==3.8.5
cconda activate sam
安装pytorch
conda install pytorch==1.8.0 torchvision torchaudio cudatoolkit=10.2 # 注意这条命令指定Pytorch的版本和cuda的版本
conda install pytorch==1.10.0 torchvision torchaudio cudatoolkit=11.3 # 30系列以上显卡gpu版本pytorch安装指令
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cpuonly # CPU的小伙伴直接执行这条命令即可
安装其他的依赖库
pip install -r requirements.txt
pip install -v -e .
安装完毕之后你首先可以你执行第一个42_1_predictor_one_point.py做一个简单的测试
这里是使用sam来进行单点测试的,如果出现下面的结果证明你调试的没有问题。



另外,你还可以执行自动的调试,不需要你指定标注点,直接生成一系列的标注点,然后让模型自己胜场即可。
源码如下:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
'''
@Project :segment-anything-main
@File :predictor_example.py
@IDE :PyCharm
@Author :肆十二(企鹅: 3045834499) 粉丝可享受99元调试服务
@Description :用来做全局预测的
@Date :2024/8/7 18:28
'''
import matplotlib.pyplot as plt
import cv2
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator, SamPredictor
from common_tools import show_anns
if __name__ == '__main__':
sam_checkpoint = "models/sam_vit_h_4b8939.pth" # 训练好的sam模型
model_type = "vit_h" # 模型类型,使用 ViT-H
device = "cuda" # 使用 GPU 进行计算
image_path = 'images/dog.jpg'
image = cv2.imread()
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
print("step1: 图像加载成功")
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
print("step2: 模型加载成功")
mask_generator = SamAutomaticMaskGenerator(sam)
masks = mask_generator.generate(image)
print(len(masks))
print(masks[0].keys())
plt.figure(figsize=(20, 20))
plt.imshow(image)
show_anns(masks)
plt.axis('off')
plt.show()
执行结果如下,其中左侧是原图,右侧是分割结果。

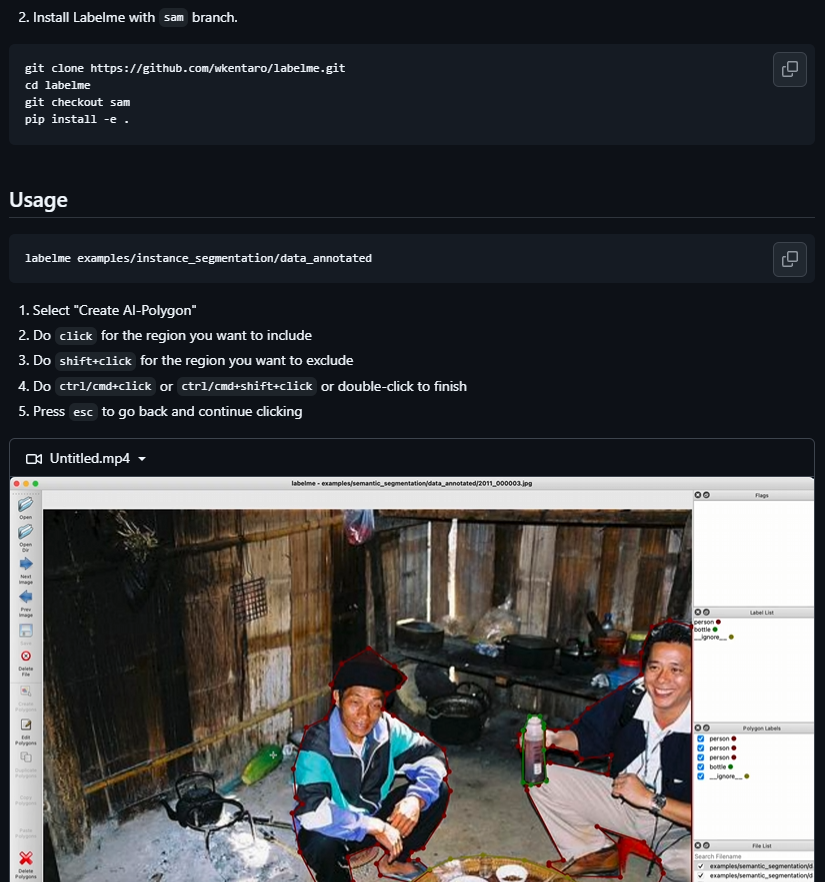
labelme-项目配置(选做)
很多自动标注的软件都是基于这个原理来进行开发的,并且再labelme中也支持了sam的模型,如果大家感兴趣,可以点击这里的订阅,如果想看的兄弟比较多的话,我们就专门出一期来说说如何使用AI来辅助你得标注。


















 2843
2843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











