







学习python模块pandas ,numpy,matplotlib
1.pandas
pandas读取文件
import pandas as pd
file = pd.read_csv("f1.csv,encoding=gbk")
将修改后的file文件再写入csv
import pandas as pd
file.to_csv("f2.csv,encoding=gbk")
DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表.
import numpy as np
import pandas as pd
import scipy as sp
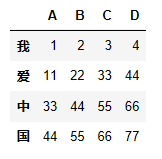
df1=pd.DataFrame([[1,2,3,4],[11,22,33,44],
[33,44,55,66],[44,55,66,77]],
index=list('我爱中国'),columns=list('ABCD'))
输出结果为:
df1['A'].values #查看某列的值,根据列名
输出结果为:
array([ 1, 11, 33, 44], dtype=int64)
df1.loc['我'] #查看某行的值,根据行名
输出结果为:
A 1
B 2
C 3
D 4
Name: 我, dtype: int64
df1.iloc[0] #查看某行的值,根据行索引
输出结果为:
A 1
B 2
C 3
D 4
Name: 我, dtype: int64
还可以对df1进行转置: df1.T
对每列求和: df1.sum()
对df1进行扩增列: 如
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3404
3404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









