







反向传播算法及其推导过程
在使用pytorch搭建神经网络时,一直对这几行代码不是很理解:
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
而这正是神经网络最重要的算法之一:BP算法,这次借助一个最简单的例子,手动推导一遍向后传播过程,以期对神经网络有更深刻的理解。
神经网络结构
这里使用一个三层网络结构,一层输入层,一层隐藏层,一层输出层,每层均包含两个神经元,其中隐含层和输出层都有偏置。

为了让这个例子更加具体,给网络中的参数进行初始化如下:

前向传播
隐藏层
首先我们计算h1和h2的输入:

之后将输入传递给激活函数(这里使用的是sigmoid激活函数),得到:

输出层
将隐藏层的输出作为输入,对输出层的神经元重复上述过程。

误差计算
这里我们均方误差作为目标函数:
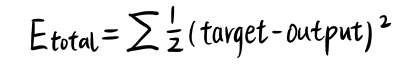
分别计算 [公式] 和 [公式] 的误差:

总误差为:
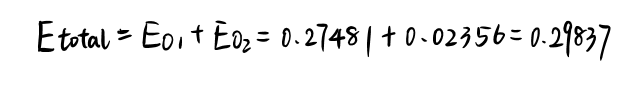
反向传播
输出层–>隐藏层
更新w5参数:
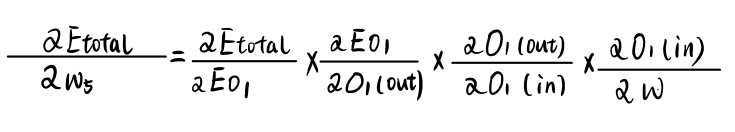
应用链式法则:

为了求出w5的梯度,我们要一层一层地算:
首先,计算总误差对O1(out)的梯度:

然后计算总误差对O1(in)的梯度:

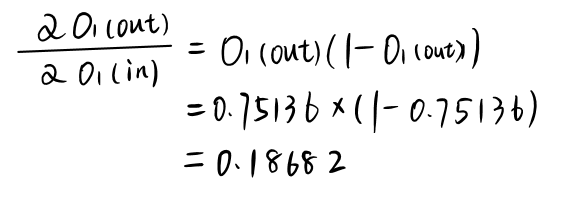
这里对sigmoid的求导需要一些技巧:

最后计算对w5的梯度:
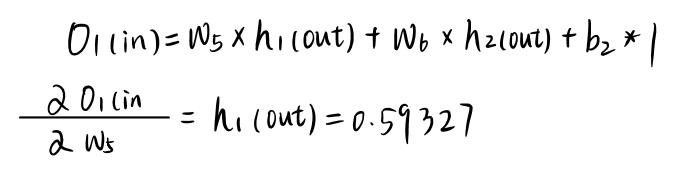
把所有梯度值相乘:

选用随机梯度下作为优化函数,学习率定为0.5,有:
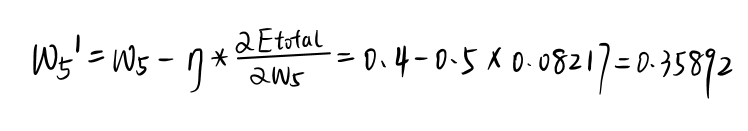
同理我们可以求出w6,w7,w8的更新值:
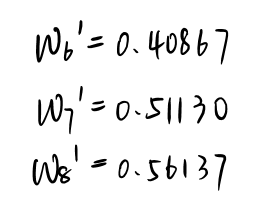
再次应用上面的算法,对b2进行更新:

隐藏层–>输入层
对于 [公式] 的梯度,我们需要计算出:
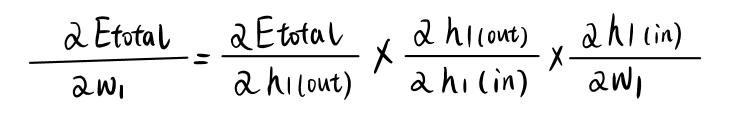
而右式中第一项由两部分相加组成:

如果继续算下去的话,也并不难算,但是这时我们暂停一下,来考虑一下BP算法如何处理这种多项相加的导数计算。
BP算法的精华在于,它可以只用一次从上至下的遍历,即可算出指定参数的导数,它是如何做到的呢?
在每一层计算导数时,仅仅计算这一层相对于下一层的导数,并把计算得到的值传到下一层,当下一层收集到所有来自上游的导数后,把他们的值相加,乘上自己对自己下一层的导数并传递到下一层?
是不是懵了?不懵才怪,我们用一个例子来解释一下:

当我们在O1这一层时,我们计算两个导数值,即:
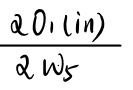 和
和
然后分别把他们放到隐藏层备用,同理,在计算o2时也把计算到的两个值传递到隐藏层。
而当我们在隐藏层中计算下一级导数时,就可以很方便的把两个值加起来,继续下一层的计算。
(这里可能还是表述的不是很清楚,可以参考知乎的一篇文章:https://www.zhihu.com/question/27239198/answer/89853077 写得非常好)
好了,我们继续计算第二层的导数,其中第一项:

第二项为:

两式相加,再加上对w1的求导:

同样,对w1进行更新:

用同样的方法更新w2,w3,w4,b1计算结果如下:

这样我们就完成了一次正向计算 + 一次反向传播
验证
这个时候,我们再进行一次正向的计算,看一看Etotal有没有减少,这里就不逐步分析了:


可以看到,更新后的Etotal为0.28390,比第一次的0.29837有明显的降低,可以验证我们的传播过程基本正确。
与代码联系
现在我们再来看这五行代码:
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
就很清楚他们都做了什么:
- 把梯度置为0,这一步对应我们上文中说到每次反向传播,都会在中间层记录上一层传下来的梯度之和,这一步就是每层的这个值清零,方便一次新的计算
- 带入inputs,得到output,这相当于我们刚刚带入i1,i2,求出O1(out),和O2(out),即为一次正向的传播
- loss的计算。相当于我们刚刚计算Etotal,事实上,如果指定
loss=nn.MSELoss(),那这一步就是刚好对应我们的Etotal - backward,这一步就是刚刚我们整个的反向传播过程,在每一层都算出对应一个梯度值
- optimizer.step(),更新参数,这一步就是我们取学习率为0.5并更新w的操作,把每个参数都进行了更新
以上即为反向传播的原理,计算和使用pytorch实现的代码,如有谬误,欢迎指正~














 20万+
20万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









