







 本文介绍了CORD-19数据集,一个关于COVID-19的科学论文资源,用于文本挖掘和信息检索。通过聚类分析和t-SNE降维,实现文献的可视化,帮助专业人员筛选和理解COVID-19研究。文章提供了kaggle上的聚类分析代码,使用了NLP、TF-IDF、PCA、t-SNE和LDA等技术,旨在协助医护人员和研究人员快速定位关键信息。
本文介绍了CORD-19数据集,一个关于COVID-19的科学论文资源,用于文本挖掘和信息检索。通过聚类分析和t-SNE降维,实现文献的可视化,帮助专业人员筛选和理解COVID-19研究。文章提供了kaggle上的聚类分析代码,使用了NLP、TF-IDF、PCA、t-SNE和LDA等技术,旨在协助医护人员和研究人员快速定位关键信息。
写在前面
最近发现了一个有关新冠疫情的数公开据集,CORD-19。CORD-19是有关COVID-19和相关历史冠状病毒研究的不断增长的科学论文资源。 CORD-19旨在通过其丰富的元数据和结构化全文本来促进文本挖掘和信息检索系统的开发。 自发布以来,CORD-19已下载超过75,000次,并已成为许多COVID-19文本挖掘和发现系统的基础。 在本文中,我们描述了数据集构建的机制,重点介绍了挑战和关键设计决策,概述了如何使用CORD-19,并预览了围绕数据集构建的工具和即将出现的共享任务。 我们希望该资源将继续使计算机界,生物医学专家和决策者聚集在一起,以寻求有效的COVID-19治疗和管理政策。 一经发布在kaggle平台上就引发了研究的热潮,这里贴上网址:https://www.kaggle.com/allen-institute-for-ai/CORD-19-research-challenge。这份数据集包括csv元数据和json文件,可以用于信息检索,信息抽取,知识图谱,问答对,预训练模型,摘要,推荐,蕴含,辅助文献综述,增强阅读等多个方向,适合广大机器学习爱好者学习研究,以寻求有效的COVID-19治疗和管理政策。
博主这里介绍一份kaggle上聚类分析的代码,虽然这份代码没有用现在流行的一些预训练模型进行分类任务,但是它处理这些数据的思路以及对聚类相关工具的熟练使用值得借鉴。网址:https://www.kaggle.com/maksimeren/covid-19-literature-clustering
目标
鉴于大量文献和COVID-19的迅速普及,卫生专业人员很难掌握有关该病毒的新信息。我们通过使用聚类进行标记和降维以进行可视化,可以通过散点图来表示文献的集合。在此图上,主题高度相似的出版物将共享一个标签,并且彼此靠近绘制。为了找到群集中的含义,将执行主题建模以查找每个群集的关键字。
通过使用Bokeh,该图将是交互式的。用户可以选择查看整体图,也可以按群集过滤数据。如果需要缩小范围,该图还将具有搜索功能,该功能会将输出限制为仅包含搜索项的论文。将鼠标悬停在绘图上的点上将提供基本信息,例如标题,作者,期刊和摘要。单击某个点将显示一个带有URL的菜单,该URL可用于访问完整出版物。
这是一个艰难的时期,医护人员,环卫人员和许多其他重要人员无法离开世界。在遵守隔离协议的同时,Kaggle CORD-19竞赛为我们提供了机会,以计算机科学系学生的最佳方式提供帮助。但是,应该指出的是,我们不是流行病学家,也不是我们评估这些论文重要性的地方。创建该工具是为了帮助受过培训的专业人员更轻松地筛选与该病毒有关的许多出版物,并找到自己的决定。
方法
-
使用自然语言处理(NLP)从每个文档的正文中解析文本。
-
使用TF-IDF将每个文档实例di转换为特征向量Xi。
-
使用t分布随机邻近嵌入(t-SNE)将降维应用于每个特征向量Xi,以将相似的研究文章聚类在二维平面XY1中。
-
使用主成分分析(PCA)将X的尺寸投影到多个尺寸,这些尺寸将保持0.95的方差,同时消除嵌入Y2时的噪声和离群值。
-
在Y2上应用k均值聚类,其中k为20,以标记Y1上的每个聚类。
-
使用潜在狄利克雷分配(LDA)在X上应用主题建模,以从每个集群中发现关键字。
-
在情节上可视地调查聚类,根据需要缩小到特定文章,并使用随机梯度下降(SGD)进行分类。
1 加载数据
加载csv数据
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import glob
import json
import matplotlib.pyplot as plt
plt.style.use('ggplot')
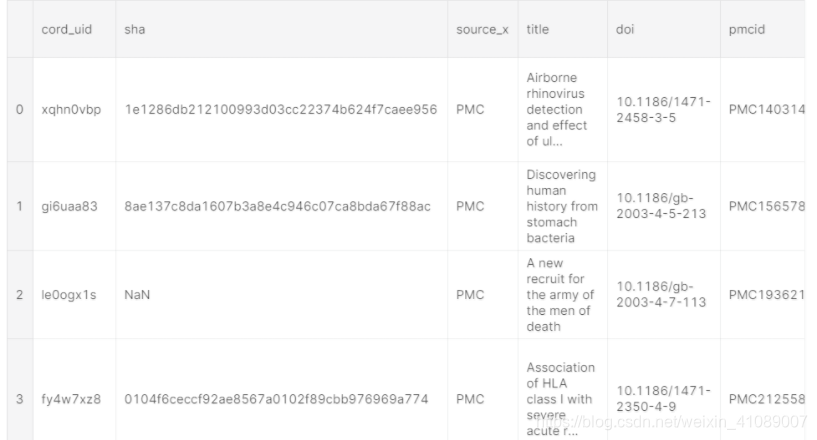
metadata_path = 'data/metadata.csv'
meta_df = pd.read_csv(metadata_path, dtype={
'pubmed_id': str,
'Microsoft Academic Paper ID': str,
'doi': str
})
meta_df.head()
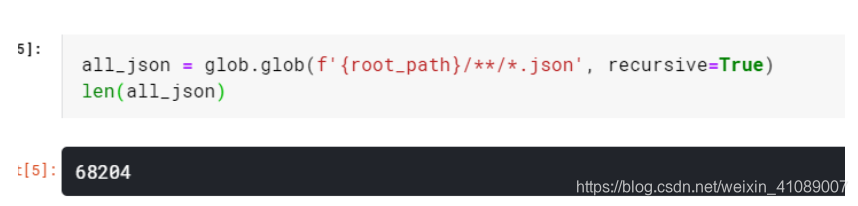
加载json文件
辅助函数
构建一些辅助用的函数,读取json文件,在字符长度达到一定数量时在每个单词后添加断点。 这是用于交互式绘图的,因此悬停工具适合屏幕。
class FileReader:
def __init__(self, file_path):
with open(file_path) as file:
content = json.load(file)
self.paper_id = content['paper_id']
self.abstract = []
self.body_text = []
# Abstract
for entry in content['abstract']:
self.abstract.append(entry['text'])
# Body text
for entry in content['body_text']:
self.body_text.append(entry['text'])
self.abstract = '\n'.join(self.abstract)
self.body_text = '\n'.join(self.body_text)
def __repr__(self):
return f'{self.paper_id}: {self.abstract[:200]}... {self.body_text[:200]}...'
first_row = FileReader(all_json[0])
print(first_row)def get_breaks(content, length):
data = ""
words = content.split(' ')
total_chars = 0
# add break every length characters
for i in range(len(words)):
total_chars += len(words[i])
if total_chars > length:
data = data + "<br>" + words[i]
total_chars = 0
else:
data = data + " " + words[i]
return data将json文件转换为DataFrame
dict_ = {'paper_id': [], 'doi':[], 'abstract': [], 'body_text': [], 'authors': [], 'title': [], 'journal': [], 'abstract_summary': []}
for idx, entry in enumerate(all_json):
if idx % (len(all_json) // 10) == 0:
print(f'Processing index: {idx} of {len(all_json)}')
try:
content = FileReader(entry)
except Exception as e:
continue # invalid paper format, skip
# get metadata information
meta_data = meta_df.loc[meta_df['sha'] == content.paper_id]
# no metadata, skip this paper
if len(meta_data) == 0:
continue
dict_['abstract'].append(content.abstract)
dict_['paper_id'].append(content.paper_id)
dict_['body_text'].append(content.body_text)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2921
2921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









