










Python深度学习训练篇
前置条件:
数据集
本篇文章主要涉及模型的构建、训练以及模型效果的评估。
评价函数
首先自定义遥感常用的评价函数:
from tensorflow.keras import backend as K
# +++++++++++++++++++++++++++++++++++++++++++
# custom metrics v1.0
# +++++++++++++++++++++++++++++++++++++++++++
def recall(y_true, y_pred): # producer accuracy
TP = K.sum(K.cast(y_true * K.round(y_pred), 'float'))
recall = TP / (K.sum(K.cast(y_true, 'float')) + K.epsilon()) # equivalent to the above two lines of code
return recall
def precision(y_true, y_pred): # user accuracy
TP = K.sum(K.cast(y_true * K.round(y_pred),'float'))
precision = TP / (K.sum(K.cast(K.round(y_pred),'float')) + K.epsilon()) # equivalent to the above two lines of code
return precision
def fmeasure(y_true, y_pred):
# Calculates the f-measure, the harmonic mean of precision and recall.
TP = K.sum(K.cast(y_true * K.round(y_pred), 'float'))
precision = TP / (K.sum(K.cast(K.round(y_pred), 'float')) + K.epsilon())
recall = TP / (K.sum(K.cast(K.round(y_true), 'float')) + K.epsilon())
F1score = 2 * precision * recall / (precision + recall + K.epsilon())
return F1score
def kappa_metrics(y_true, y_pred):
# Calculates the kappa coefficient
TP = K.sum(K.cast(y_true * K.round(y_pred), 'float')) + K.epsilon()
FP = K.sum(K.cast((1 - y_true) * K.round(y_pred), 'float')) + K.epsilon()
FN = K.sum(K.cast(y_true * (1 - K.round(y_pred)), 'float')) + K.epsilon()
TN = K.sum(K.cast((1 - y_true) * (1 - K.round(y_pred)), 'float')) + K.epsilon()
totalnum = TP + FP + FN + TN
p0 = (TP + TN) / (totalnum + K.epsilon())
pe = ((TP + FP) * (TP + FN) + (FN + TN) * (FP + TN)) / (totalnum * totalnum + K.epsilon())
kappa_coef = (p0 - pe) / (1 - pe + K.epsilon())
return kappa_coef
def kappa_metrics_mod(y_true, y_pred):
# Calculates the kappa coefficient
TP = K.sum(K.cast(y_true * K.round(y_pred), 'float')) + K.epsilon()
FP = K.sum(K.cast((1 - y_true) * K.round(y_pred), 'float')) + K.epsilon()
FN = K.sum(K.cast(y_true * (1 - K.round(y_pred)), 'float')) + K.epsilon()
TN = K.sum(K.cast((1 - y_true) * (1 - K.round(y_pred)), 'float')) + K.epsilon()
return TP,FP,FN,TN
def OA(y_true, y_pred):
TP = K.sum(K.cast(y_true * K.round(y_pred), 'float'))
FP = K.sum(K.cast((1 - y_true) * K.round(y_pred), 'float'))
FN = K.sum(K.cast(y_true * (1 - K.round(y_pred)), 'float'))
TN = K.sum(K.cast((1 - y_true) * (1 - K.round(y_pred)), 'float'))
totalnum = TP + FP + FN + TN
overallAC = (TP + TN) / (totalnum + K.epsilon())
return overallAC
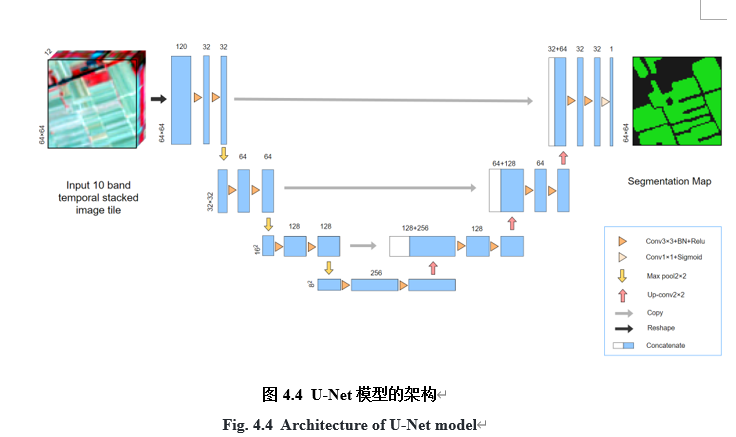
定义网络
定义网络模型,以U-net为例:
from tensorflow.keras.layers import *
from tensorflow.keras.models import Model
from tensorflow.keras import layers
from tensorflow.keras import losses
from tensorflow.keras import models
from tensorflow.keras import metrics
from tensorflow.keras import optimizers
# 分段常数衰减(Piecewise Constant Decay)
boundaries=[5*steps_per_epoch, 10*steps_per_epoch,
20*steps_per_epoch, 30*steps_per_epoch] # 以 0 5 10 20 30为分段
lr = 0.001
values=[1*lr, 0.25*lr, 0.125*lr, 0.0625*lr, 0.0625/2*lr] # 各个分段学习率的值
piece_wise_constant_decay = tf.keras.optimizers.schedules.PiecewiseConstantDecay(
boundaries=boundaries, values=values, name=None)
#训练效果不好可以自己调整学习率,学习率调整策略
def conv_block(input_tensor, num_filters):
encoder = layers.Conv2D(num_filters, (3, 3), padding='same')(input_tensor)
encoder = layers.BatchNormalization()(encoder)
encoder = layers.Activation('relu')(encoder)
encoder = layers.Conv2D(num_filters, (3, 3), padding='same')(encoder)
encoder = layers.BatchNormalization()(encoder)
encoder = layers.Activation('relu')(encoder)
return encoder
def encoder_block(input_tensor, num_filters):
encoder = conv_block(input_tensor, num_filters)
encoder_pool = layers.MaxPooling2D((2, 2), strides=(2, 2))(encoder)
return encoder_pool, encoder
def decoder_block(input_tensor, concat_tensor, num_filters):
decoder = layers.Conv2DTranspose(num_filters, (2, 2), strides=(2, 2), padding='same')(input_tensor)
decoder = layers.concatenate([concat_tensor, decoder], axis=-1)
decoder = layers.BatchNormalization()(decoder)
decoder = layers.Activation('relu')(decoder)
decoder = layers.Conv2D(num_filters, (3, 3), padding='same')(decoder)
decoder = layers.BatchNormalization()(decoder)
decoder = layers.Activation('relu')(decoder)
decoder = layers.Conv2D(num_filters, (3, 3), padding='same')(decoder)
decoder = layers.BatchNormalization()(decoder)
decoder = layers.Activation('relu')(decoder)
return decoder
def UNet(times = 12,input_shape = (64, 64,12, 10)):
inputs = Input(input_shape) # (64, 64,12, 10)
#inputs1 = layers.LayerNormalization()(inputs) #尝试增加归一化层,好像效果并不好
inputs1 = Reshape((64, 64,-1))(inputs) #(64, 64,120)
#inputs1 = cbam_block(inputs1) #增加CBAM注意力机制
encoder0_pool, encoder0 = encoder_block(inputs1, 32) # 32
encoder1_pool, encoder1 = encoder_block(encoder0_pool, 64) # 16
encoder2_pool, encoder2 = encoder_block(encoder1_pool, 128) # 8
center = conv_block(encoder2_pool, 256) # center
decoder2 = decoder_block(center, encoder2, 128) # 8
decoder1 = decoder_block(decoder2, encoder1, 64) # 16
decoder0 = decoder_block(decoder1, encoder0, 32) # 32
outputs = layers.Conv2D(1, (1, 1), activation='sigmoid')(decoder0) # 二分类不使用onehot编码
model = Model(inputs, outputs)
model.compile(
optimizer = optimizers.Adam(piece_wise_constant_decay),
loss= losses.BinaryCrossentropy(from_logits=False,label_smoothing=0.0,axis=-1,reduction="auto"),
metrics=['accuracy',recall,precision,kappa_metrics,fmeasure,OA])
return model
model = UNet(input_shape = (64, 64,12, 10))
model.summary()
训练模型
训练并保存日志,日志名称会根据网络名称和当前时间自动生成,保证同一网络多次训练结果不会同名,保存至./logs/文件夹下。
同时保存训练过程中验证集上kappa_metrics最高的模型。日志通过tensorboard保存,在Jupyter Lab环境下还需要安装TensorBoard Pro插件:JupyterLab TensorBoard Pro,其可是实时查看当前训练的一些情况,非常方便。
from datetime import datetime
from tensorflow import keras
BATCH_SIZE = 8
EVAL_BATCH_SIZE = 8
EPOCHS = 40
TRAIN_SIZE = BUFFER_SIZE*training_patches_size #160*27
EVAL_SIZE =BUFFER_SIZE*eval_patches_size #160*9
m = UNet(input_shape = (64, 64,12, 10)); NetNAME = "Unet_lr0.001"
# m = convLTSM_2(input_shape = (64, 64,12, 10));NetNAME = "convLSTM"
# m = UNet_LSTM(input_shape = (64, 64,12, 10)) ;NetNAME = "UNet_LSTM"
# m = DeeplabV3(input_shape = (64, 64,12, 10));NetNAME ="DeeplabV3"
# m = SegFormer(input_shape = (64, 64,12, 10));NetNAME = "SegFormer"
# m = TD_UNet(input_shape = (64, 64,12, 10)) ;NetNAME = "TD_UNet"
def trainModel(m,NetNAME):
training = get_training_dataset()
evaluation = get_eval_dataset()
tf.debugging.set_log_device_placement(True)
timestamp = datetime.now().strftime("%Y%m%d-%H%M%S")
NAME = timestamp + NetNAME +"_batchsize"+str(BATCH_SIZE);print(NAME)
logdir = "./logs/" + NAME ##!!!!安装tensorbroad pro 打开对应目录查看训练日志
modeldir = "./model/"+NAME+".h5"
tensorboard_callback = keras.callbacks.TensorBoard(log_dir=logdir)
checkpoint = tf.keras.callbacks.ModelCheckpoint(filepath=modeldir, monitor='val_kappa_metrics', verbose=1, save_best_only=True, mode = 'max')
with tf.device('/GPU:0'):
m.fit(
x=training,
epochs=EPOCHS,
steps_per_epoch=int(TRAIN_SIZE / BATCH_SIZE),
validation_data=evaluation,
validation_steps=int(EVAL_SIZE / EVAL_BATCH_SIZE),
validation_batch_size = EVAL_BATCH_SIZE,
validation_freq=1,
callbacks=[tensorboard_callback,checkpoint])
trainModel(m,NetNAME)
输出:

评估模型效果
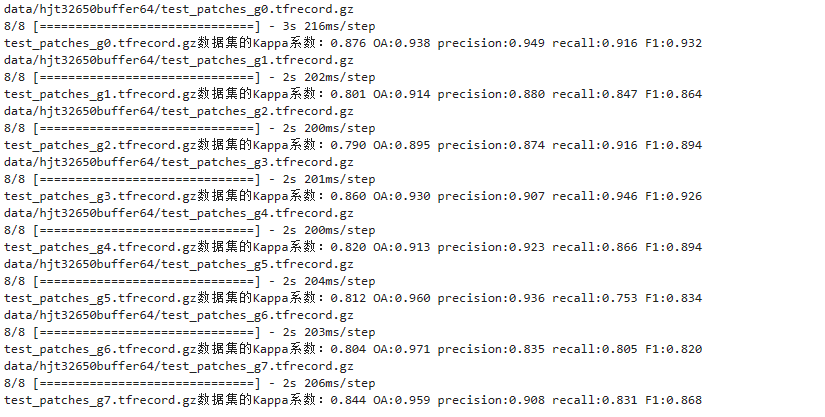
对保存的模型在测试样方数据集(未拼接)上进行效果评估,用于观察模型的精度效果。
import os
modelName = {'UNet':'20231109-215546UNet_lr_DS_batchsize8.h5',
'TFBS':'20231109-234748TFBS_lr_DS_batchsize8.h5',
'convLSTM':'20231111-122300convLTSM_lr_DS_batchsize8.h5',
'Mymodel':'20231110-125123Mymodel_lr_DS_batchsize8.h5',
'UNet_LSTM':'20231110-175526UNet_LSTM_lr_DS_batchsize8.h5',
'TD-UNet':'20240203-235557TD_UNet_lr_DS_batchsize8.h5'}
name = 'UNet'
MODEL_DIR = 'model/'+modelName[name]
row = pd.DataFrame(columns=['名称',name])
print(MODEL_DIR)
m = tf.keras.models.load_model(MODEL_DIR,custom_objects={'recall': recall,
'precision':precision,
'kappa_metrics':kappa_metrics,
'fmeasure':fmeasure,
'OA':OA
})
directory = 'data/yangfang/' # 替换为你要列出文件的目录路径
files = os.listdir(directory)
filesIndex = [0,1,2,3,4,5,6,7]#
testPath = 'test_patches_g%d.tfrecord.gz'
files = [testPath%(i) for i in filesIndex]
files = files
# 遍历多个样方
for file in files:
data = []
labels = []
dataset = get_dataset([directory+file])
print(directory+file)
for example in dataset:
data.append(example[0])
labels.append(example[1])
data = tf.stack(data)
labels = tf.stack(labels)
# 预测数据集
predictions = m.predict(data)
binary_predictions = np.where(predictions > 0.5, 1, 0) # 根据阈值判定进行二分类
binary_predictions = binary_predictions[:,:,:,0]
# 计算整个数据集的预测结果和真实标签的Kappa系数
kappa = kappa_metrics(binary_predictions,labels)
oa = OA(binary_predictions,labels)
pre = precision(binary_predictions,labels)
rc = recall(binary_predictions,labels)
f1 = fmeasure(binary_predictions, labels)
print(f"{file}数据集的Kappa系数:{kappa:.3f} OA:{oa:.3f} precision:{pre:.3f} recall:{rc:.3f} F1:{f1:.3f}")
预测、拼接并保存测试样方区块。num_rows和num_cols参数根据GEE导出的结果填写。
import os
import pandas as pd
df = pd.DataFrame(columns=['名称'])
modelName = {'UNet':'20231109-215546UNet_lr_DS_batchsize8.h5',
'TFBS':'20231109-234748TFBS_lr_DS_batchsize8.h5',
'convLSTM':'20231111-122300convLTSM_lr_DS_batchsize8.h5',
'Mymodel':'20231110-125123Mymodel_lr_DS_batchsize8.h5',
'UNet_LSTM':'20231110-175526UNet_LSTM_lr_DS_batchsize8.h5'}
name = 'UNet'
MODEL_DIR = 'model/'+modelName[name]
row = pd.DataFrame(columns=['名称',name])
print(MODEL_DIR)
m = tf.keras.models.load_model(MODEL_DIR,custom_objects={'recall': recall,
'precision':precision,
'kappa_metrics':kappa_metrics,
'fmeasure':fmeasure,
'OA':OA
})
directory = 'data/yangfang/' # 替换为你要列出文件的目录路径
# 测试文件
files = ['test_patches_g1.tfrecord.gz']
# 遍历多个样方
for file in files:
data = []
labels = []
dataset = get_dataset([directory+file])
print('data/2019/'+file)
for example in dataset:
data.append(example[0])
labels.append(example[1])
data = tf.stack(data)
labels = tf.stack(labels)
print(data.shape)
predictions = m.predict(data)
binary_predictions = np.where(predictions > 0.5, 1, 0) # 根据阈值判定进行二分类
binary_predictions = binary_predictions[:,:,:,0]
# 拼接数据
big_image = mosicImage(data,num_rows = 16,num_cols = 16)
big_label = mosicLabel(labels,num_rows = 16,num_cols = 16)
big_predictions = mosicLabel(binary_predictions,num_rows = 16,num_cols = 16)
# 计算整个数据集的预测结果和真实标签的Kappa系数
kappa = kappa_metrics(big_predictions,big_label)
print(f"{file}数据集的Kappa系数:{kappa}")
#显示 并保存
savename = file.split('.')[0]
savePath = f"2019/{savename}/"
if not os.path.exists('img/'+savePath):
os.makedirs('img/'+savePath)
print(f'{savePath}文件夹已创建!')
show_image(big_image.numpy(),[8,4,3],savePath+f"{savename}")
show_label(big_label.numpy(),savePath+f"{savename}-label")
show_label(big_predictions.numpy(),savePath+f"{name}")
计算拼接后的区块结果和真值的Kappa等。用于导出模型最终的精度效果。
from PIL import Image
import numpy as np
import os
def readResult(path):
# 读取图像
image = Image.open(path)
# 转换为numpy数组
image_array = np.array(image)
# 归一化
image_array = image_array / 255.0
# 转换为Tensor格式
image_tensor = tf.convert_to_tensor(image_array, dtype=tf.float32)
return image_tensor
def search_files(folder_path, prefix):
file_names = []
for root, dirs, files in os.walk(folder_path):
for file in files:
if file.startswith(prefix):
file_names.append(os.path.join(root, file))
return file_names[0]
filesIndex = [0,1,2,3,4,5,6,7]
trainPath = 'test_patches_g%d.tfrecord.gz'
files = [trainPath%(i) for i in filesIndex]
print(f'UNet TD-UNet convLSTM UNet_LSTM SegFormerB1 packagename')
METRICS = {'recall': recall,'precision':precision,'kappa_metrics':kappa_metrics,'fmeasure':fmeasure,'OA':OA}
metrics = 'OA'
kappaSum = [0,0,0,0,0]
for file in files:
packagename = file.split('.')[0]
folder_path = "img\\"+packagename
kappa = []
base = search_files(folder_path, 'label')
label = readResult(base)
file_names = folder_path+'\\UNet.png'
kappa.append(METRICS[metrics](readResult(file_names),label))
file_names = folder_path+'\\TD-UNet.png'
kappa.append(METRICS[metrics](readResult(file_names),label))
file_names = folder_path+'\\convLSTM.png'
kappa.append(METRICS[metrics](readResult(file_names),label))
file_names = folder_path+'\\UNet_LSTM.png'
kappa.append(METRICS[metrics](readResult(file_names),label))
file_names = folder_path+'\\SegFormerB1.png'
kappa.append(METRICS[metrics](readResult(file_names),label))
print(f'{kappa[0]:.4f} {kappa[1]:.4f} {kappa[2]:.4f} {kappa[3]:.4f} {kappa[4]:.4f} {packagename}')
kappaSum = [k+s for k,s in zip(kappa,kappaSum)]
print(f'{kappaSum[0]/8:.4f} {kappaSum[1]/8:.4f} {kappaSum[2]/8:.4f} {kappaSum[3]/8:.4f} {kappaSum[4]/8:.4f} mean')
大范围模型预测
此步骤的目的是得到整个研究区的分类结果,过程和数据量比较大,需要导出覆盖研究区的所有区块的数据包(作者导出了100个),并且推理得到每个区块的分类结果。以下代码是拼接多个区块并恢复地理位置信息。需要安装GDAL库
import numpy as np
from PIL import Image
###研究区每个区块的位置,-1代表无
pos = [[-1,-1,-1,31,41,-1,-1,69,79,88,-1,-1,],
[-1,-1,21,30,40,50,59,68,78,87,95,-1,],
[-1,-1,20,29,39,49,58,67,77,86,94,-1,],
[ 6,-1,19,28,38,48,57,66,76,85,93,100,],
[ 5,12,18,27,37,47,56,65,75,84,92,99,],
[ 4,11,17,26,36,46,55,64,74,83,91,98,],
[ 3,10,16,25,35,45,54,63,73,82,90,97,],
[ 2, 9,15,24,34,44,53,62,72,81,89,96,],
[ 1, 8,14,23,33,43,52,61,71,80,-1,-1,],
[ 0, 7,13,22,32,42,51,60,70,-1,-1,-1,]]
SoyaMap = np.zeros((10*496, 12*624))
for i,row in enumerate(pos):
for j,index in enumerate(row):
if index != - 1 :
path = f"img/predict/predict_patches_g{index}/Mymodel-predict.png"
try:
# 读取图像
image = Image.open(path)
# 转换为numpy数组
image_array = np.array(image)
SoyaMap[i*496:(i+1)*496,j*624:(j+1)*624]= image_array
finally:
pass
Image.fromarray(np.uint8(255-SoyaMap)).save(f"img/predict/SoyaMap.png")

还原位置信息。保存为TIF格式,需要图像左上角的经纬度坐标,可以从GEE导出的json文件中获取。
def read_img(filename):
dataset = gdal.Open(filename)
im_width = dataset.RasterXSize #栅格矩阵的列数
im_height = dataset.RasterYSize #栅格矩阵的行数
im_geotrans = dataset.GetGeoTransform() #仿射矩阵
im_proj = dataset.GetProjection() #地图投影
im_data = dataset.ReadAsArray(0,0,im_width,im_height)
del dataset
return im_proj,im_geotrans,im_data
def write_img(filename,im_proj,im_geotrans,im_data):
if "int8" in im_data.dtype.name:
datatype = gdal.GDT_Byte
elif "int16" in im_data.dtype.name:
datatype = gdal.GDT_UInt16
else:
datatype = gdal.GDT_Float32
if len(im_data.shape) == 3:
im_bands, im_height, im_width = im_data.shape
else:
im_bands, (im_height, im_width) = 1, im_data.shape
driver = gdal.GetDriverByName("GTiff") # 数据类型必须有,因为要计算需要多大内存空间
dataset = driver.Create(filename, im_width, im_height, im_bands, datatype)
dataset.SetGeoTransform(im_geotrans) # 写入仿射变换参数
dataset.SetProjection(im_proj) # 写入投影
if im_bands == 1:
dataset.GetRasterBand(1).WriteArray(im_data) # 写入数组数据
else:
for i in range(im_bands):
dataset.GetRasterBand(i + 1).WriteArray(im_data[i])
del dataset
from osgeo import gdal, osr
path = r"img/predict/SoyaMap.png"
output_raster=r"img/predict/SoyaMap.tif"
# 读取图像
image = Image.open(path)
# 转换为numpy数组
image_array = (1-np.array(image)/255).astype(np.int8)
# 创建一个空间参考对象 ,将空间坐标系设置为EPSG:4326
srs = osr.SpatialReference()
srs.ImportFromEPSG(4326)
# 地理转换信息,图像左上角的经纬度坐标点和像素大小
geotransform = [115.86991557438377,8.983152841195215E-5, 0.0, 33.789500591456914, 0.0, -8.983152841195215E-5]
dataset = write_img(output_raster,srs.ExportToWkt(),geotransform,image_array)
















 208
208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









