







Day 1 (2022.4.26)
// 在#后面的都是预处理语句,编译器收到源文件后首先处理预编译语句(发生在实际编译之前)
// #include <iostream> 将iostream文件的所有内容拷贝到当前文件,之所以要拷贝,是因为需要一个被 // 调函数的声明
// main函数不写return则默认返回0
// 重载运算符其实是函数
std::cout.print("Hello World!").print(std::endl);
// std::cin.get() 等待我们按下enter
// 预处理->编译生成目标文件(.obj)->链接为可执行文件(.exe)// 链接
// Log.cpp
#include <iostream>
void log(const char* message) {
std::cout << message << std::endl;
}
// Main.cpp
#include <iostream>
void log(const char* message);
int main() {
log("Hello World!");
std::cin.get();
}Day 2 (2022.4.27)
// 一个源文件连同通过#include包含的所有头文件和源文件一起被称为预处理翻译单元,
// 预处理翻译单元经过预处理之后被称为翻译单元
// 预编译处理命令 if true 就会编译中间的内容
#if
程序段
#endif
// 如果 xxx 被#define定义过,则编译程序段1,否则2
#ifdef
程序段1
#else
程序段2Day 3 (2022.5.8)
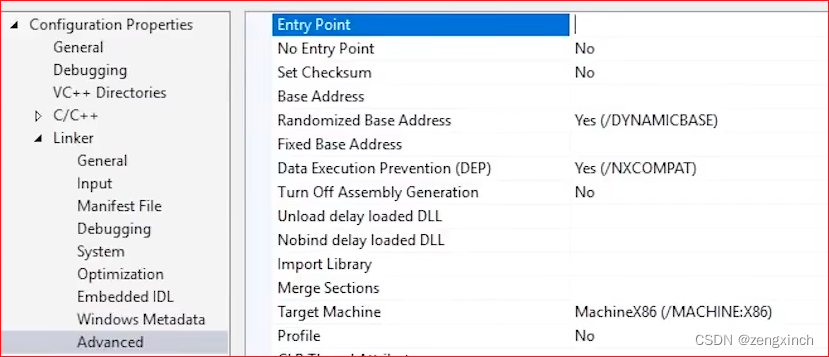
// 每一个exe文件都要有一个入口函数,不一定是main,可以设置
// 静态函数是只会在当前file文件用到。如果在main函数中没有用到它,则不会对它进行link
// Log.cpp
#include <iostream>
void Logg(const char* message)
{
std::cout << message << std::endl;
}
// Math.cpp
#include <iostream>
void Log(const char* message);
static void Multiply(int a, int b)
{
Log("Multiply");
}
int main()
{
std::cin.get();
}
// 下面代码会有重复定义的error,有三种解决办法
// static(每个cpp都有一份copy) inline(每个cpp直接是实现代码) 声明放在头文件,实现放在CPP
// Log.h
#pragma once
void Log(const char* message)
{
std::cout << message << std::endl;
}
// Log.cpp
#include <iostream>
#include <Log.h>
void InitLog()
{
Log("Initialized Log");
}
// Math.cpp
#include <iostream>
#include <Log.h>
static void Multiply(int a, int b)
{
Log("Multiply");
}
int main()
{
Multiply(3, 4);
std::cin.get();
}Day 4 (2022.5.14)
// 可以使用引号 " " 来指定编译器包含目录的相对路径里面的文件,尖括号 < > 只用于编译器包含
// 路径 (include)Day 5 (2022.5.15)
// 在断点(breakpoint)处,右键点击转到反汇编(go to disassembly)// Visual Studio 的最佳设置
// Header Files, Source Files 是一种虚拟的组织方案
// 点击 show all files 可以看到实际的文件组织情况,你可以自己
// 新建src文件夹,从visual studio中拖动文件放进去// (debug模式), Visual Studio 把中间文件放到了项目
// 目录中一个名为debug的文件夹中,而实际最终可执行的
// 二进制文件在solution目录下的一个名为Debug文件夹
// 现在我们来修改这个设置,在项目的属性中,将输出文件路径和中间文件路径改为如下,然后右键项目
// clean solution,当然这个clean清理不干净,需要我们再自己去文件夹中将不要的文件删除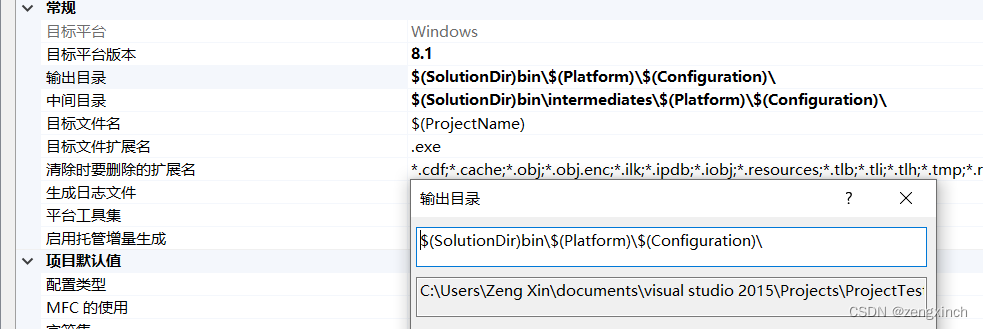
// 指针就是地址,是一个保存内存地址的整数
// 类型与这个无关,只是让编译器知道放在这个地址的是什么东西
// 引用是指针的语法糖,是指针的伪装
// 在定义引用后不能再更改它
// 使用指针修改变量
void Increment(int* value)
{
(*value)++;
}
int main()
{
int a = 5;
Increment(&a);
return 0;
}
// 使用引用修改变量
void Increment(in&* value)
{
value++;
}
int main()
{
int a = 5;
Increment(a);
return 0;
}// m_xxx, m_ 指私有类成员变量
// s_xxx, s_ 指静态变量/函数
// 静态变量或函数只在当前翻译单元内部链接
// 静态变量或函数意味着,当需要将这些函数或变量与实际定义的符号链接时,
// 链接器不会在这个翻译单元的作用域之外,寻找那个符号定义
// 如果将 Static.cpp中的static取消,会报重复定义s_Variable的错误
// 加static可以使得自己对其它翻译单元隐藏
// 也可也去掉static,再在Main.cpp中改成 external int s_Variable;
// Static.cpp
static int s_Variable = 5;
// Main.cpp
#include <iostream>
int s_Variable = 10;
int main()
{
std::cout << s_Variable << std::endl;
std::cin.get();
}// 静态成员变量是所有实例共享的,但是其只是在类中进行了声明,
// 并未定义或初始化(分配内存),类或者类实例就无法访问静态成员变量,
// 这显然是不对的,所以必须先在类外部定义
// 如果不加int Entity::x,会报错为解析的外部引用变量
struct Entity
{
static int x;
void Print()
{
std::cout << x << std::endl;
}
}
int Entity::x;
int main()
{
Entity e;
e.x = 2;
return 0;
}Day 6 (2022.5.16)
// 用static实现单例类,调用Get一直都是同一个对象
// 也可用静态初始化函数创建所有对象,然后使用静态方法Get之类的。
#include <iostream>
class Singleton
{
public:
static Singleton& Get()
{
static Singleton instance;
return instance;
}
void Hello() {}
};
int main()
{
Singleton::Get().Hello();
return 0;
}// 在类中,enum是静态的
#include <iostream>
class Log
{
public:
enum Level
{
LevelError, LevelWarning, LevelInfo
};
private:
Level m_Loglevel = LevelInfo;
public:
void SetLevel(Level level)
{
m_Loglevel = level;
}
void Error(const char* message)
{
if (m_Loglevel >= LevelError)
std::cout << "[ERRR]: " << message << std::endl;
}
};
int main()
{
Log::Level tmp = Log::LevelError;
std::cout << tmp << std::endl;
std::cin.get();
return 0;
}// 当对象是在栈上创建时,退栈的时候就会调用析构函数
// 如果在堆上手动分配了任何类型的内存,那么就需要手动清理 (在堆上创建的对象)
// 如果在类使用中或者构造中分配了内存,就要删除它们Day 7 (2022.5.17)
// 继承的写法:class Player : public Entity
// 在接受父类的地方都可以传递子类进去// C++ 虚函数
// 虚函数允许我们在子类中重写方法
// 虚函数需要额外的内存来存储虚函数表,
// 每次调用虚函数时,需要遍历这个表,来确定映射到哪个函数
// 如果不是虚函数就会打印两次Entity
#include <iostream>
#include <string>
class Entity
{
public:
virtual std::string GetName() {return "Entity";}
};
class Player : public Entity
{
private:
std::string m_Name;
public:
Player(const std::string& name)
: m_Name(name) {}
std::string GetName() override {return m_Name;}
}
void PrintName(Entity* entity)
{
std::cout << entity->GetName() << std::endl;
}
int main()
{
Entity* e = new Entity();
PrintName(e);
Player* p = new Player("Xin");
PrintName(p);
return 0;
}Day 8 (2022.5.18)
// C++ 接口(纯虚函数)
// 如果一个类只包含纯虚函数,不能实例化它。其子类必须实现这个纯虚函数,才能被实例化
virtual std::string GetName() = 0;// C++ 可见性
// private 当前类和它的友元类/函数可访问
// protected 只能在当前类和其继承类中可访问
// public 都可以访问// C++ 数组
int a[5]; //是在栈中创建的内存,在花括号结束时自动回收
int* a = new int[5] //是在堆上创建,在程序销毁前都处于活跃状态,需要用delete删除
//因此,某个函数返回的数组必须要是用new创建的
//间接寻址
//用int example[5],当看e的地址时会看到5个连续的2
//new会看到一个新的地址,这个新地址里有5个连续的2
class Entity
{
public:
int example[5];
// int* example = new int[5];
Entity()
{
for (int i = 0; i < 5; i++)
example[i] = i;
}
};
int main()
{
Entity e;
return 0;
}// C++ 字符串字面值:是在双引号之间的一串字符
// 字符串字面值只保存在内存的只读区域
char* name = "cherno"; // 这是未定义的行为
name[2] = 'p'; // name的类型实际是const (在常量区),不支持这样修改
char name[] = "cherno"; // 需要修改的话可以这样写
const char* name = "cherno"; // 否则
std::wstring name0 = L"cherno";
const char* name = "cherno";
const wchar_t* name1 = L"cherno";
const char16_t* name = u"cherno";
const char32_t* name = U"cherno";// const 关键字
int const* a =
int* const a = new int; // 指针a是个常量
const int* a = new int; // (int* a)是个常量,即a的内容是个常量,不能给a赋值
// 由const修饰的类的方法,不对类进行任何修改
// 如果GetX不加const,在e.GetX()会报错,const Entity只能使用const方法
class Entity
{
private:
int x;
public:
int GetX() const
{
return x;
}
}
void PrintEntity(const Entity& e)
{
std::cout << e.GetX() << std::endl;
}// mutable 允许函数是常量方法,但可以修改变量
// 修饰lambda表达式,值捕获时可以直接操作传入参数。(并非引用捕获,依旧值捕获,不修改原值)
class Entity
{
private:
int x;
mutable y;
public:
int GetX() const
{
y = 2;
return x;
}
}// C++ 成员初始化列表
// 初始化成员列表的时候,要与成员变量声明时的顺序一致
// 会初始化Example两次,调用两个构造函数,使用初始化成员列表则不会出现这个问题
// 内置变量也不会出现这个问题
class Example
{
public:
Example()
{
std::cout << "Created Example!" << std::endl;
}
Example(int x)
{
std::cout << "Created Example: " << x << "!" << std::endl;
}
}
class Entity
{
private:
std::string m_Name;
Example m_Example;
public:
Entity()
{
m_Example = Example(8);
return x;
}
}
int main()
{
Entity e;
}Day 9 (2022.5.19)
// 创建并初始化C++对象
// 在栈上创建的对象会在{}结束自动销毁
// 在堆上创建对象比在栈上创建慢,且必须手动释放被分配的内存
// 加不加括号是一样的,对于默认构造函数
Entity* e = new Entity;
Entity e;
// 创建一个对象数组
Entity* e = new Entity[50];// C++ new 关键字
// new 不仅分配内存,还调用了构造函数
Entity* e = new Entity();
Entity* e = (Entity*)malloc(sizeof(Entity));
delete e;// C++ 隐式转换和explicit关键字
// 隐式构造函数
// 在构造函数前加上explicit就不能够进行隐式转换
#include <iostream>
#include <string>
class Entity
{
private:
int m_Age;
std::string m_Name;
public:
Entity(int age) : m_Age(age) {}
Entity(std::string name) : m_Name(name) {}
};
void PrintEntity(const Entity& entity)
{
}
int main()
{
Entity e = 27;
PrintEntity(std::string("Xin"));
return 0;
}// C++ 运算符及其重载
// 运算符其实就是函数
Vector2 Operator+(const Vector& other) const
{
return Vector2(x + other.x, y + other.y);
}
// cout 的重载,不在类里面重载
std::ostream& operator<<(std::ostream& stream, const Vector2& other)
{
stream << other.x << "," << other.y;
return stream;
}// C++ this
// 通过 this 可以访问类成员函数
#include <iostream>
#include <string>
void PrintEntity(const Entity& e);
class Entity
{
public:
int x, y;
Entity(int x, int y)
{
this->x = x;
this->y = y;
PrintEntity(*this);
}
};
void PrintEntity(const Entity& entity)
{
}Day 10 (2022.5.23)
// 栈作用域生存期
// 这样写是错误的,一旦返回,数组将被销毁
// 有2个解决方法,1,在堆上创建数组(new),2,传参
int* CreateArray()
{
int array[50];
return array;
}
// 作用域指针
// 它基本上是一个类(指针的包装器),在构造时用堆分配指针,析构时删除指针,其可以
// 自动化new和delete
// 仍想在堆上分配,但在作用域结束后自动删除
class Entity
{
};
class ScopedPtr
{
private:
Entity* m_Ptr
public:
ScopedPtr(Entity* ptr) : m_Ptr(ptr) {}
~ScopedPtr() {delete m_Ptr;}
}
int main()
{
{
// 在{}作用域结束后会自动销毁Eneity,因为ScopedPtr是在栈中分配的
ScopedPtr e = new Entity();
}
}// C++ 的智能指针,它们可以避免你忘记使用delete
// unique_ptr 是作用域指针,超出作用域时,它会被自动销毁
// 不能够复制 unique_ptr,当你复制它的时候,相当于两个unique_ptr指向同一个区域,如果其中一个
// 死掉了,这块区域的内存会被释放,则另一个指针就指向了被释放的内存
#include <iostream>
#include <memory>
class Entity
{
public:
Entity()
{
std::cout << "Construct Entity!" << std::endl;
}
~Entity()
{
std::cout << "Destroyed Entity!" << std::endl;
}
void Print() {}
};
int main()
{
{
// std::unique<Entity> entity(new Entity());
// 出于异常安全的缘故,最好使用make_unique
// 当构造函数有异常的时候,不会得到一个没有引用的悬空指针,从而造成内存泄漏
std::unique<Entity> entity = std::make_unique<Entity>();
entity->Print();
}
}
// shared_prt 引用计数
// shared_ptr 需要分配另一块内存,叫做控制块,用来存储引用计数
// 因此,用new的话需要先后分配Entity和控制内存块的两次分配,比std::make_shared要慢
// 当把shared_prt 赋值给另一个shared_ptr会增加引用计数,然而,赋值给一个weak_ptr则不会Day 11 (2022.5.24)
// C++ 的复制与拷贝构造函数
// 当我们 copy 这个类的时候,C++ 将它的所有类成员变量(这些成员变量组成了类(实例的内存空间))
// 这种是浅拷贝,它们共用m_Buffer,因此{}结束后,它被析构两次,所以报错
// String string = "Xin";
// String second = string;
// 深拷贝是拷贝对象里面的所有成员
// 可以使用拷贝构造函数来进行深拷贝
// 默认的拷贝构造函数如下
// String(const String& other) : m_Buffer(other.m_Buffer), m_Size(other.m_Size) {}
// 如果不需要拷贝构造函数(不允许拷贝)
// String(const String& other) = delete;
// 尽量用 const xxx& 传递对象会效率更高
#include <iostream>
class String
{
private:
char* m_Buffer;
unsigned int m_Size;
public:
String(const char* string)
{
m_Size = strlen(string);
m_Buffer = new char[m_Size + 1];
memcpy(m_Buffer, string, m_Size);
m_Buffer[m_Size] = 0;
}
~String()
{
delete[] m_Buffer;
}
String(const String& other)
: m_Size(other.m_Size)
{
m_Buffer = new char[m_Size + 1];
memcpy(m_Buffer, other.m_Buffer, m_Size + 1);
}
char& operator[](unsigned int index)
{
return m_Buffer[index];
}
friend std::ostream& operator<<(std::ostream& stream, const String& string);
};
std::ostream& operator<<(std::ostream& stream, const String& string)
{
stream << string.m_Buffer;
return stream;
}
int main()
{
String string = "Xin";
String second = string;
second[2] = 'm';
std::cout << string << std::endl;
std::cout << second << std::endl;
std::cin.get();
return 0;
}Day 12 (2022.5.27)
// C++ 箭头操作符
#include <iostream>
#include <string>
class Entity
{
public:
int x;
public:
void Print() const { std::cout << "Hello" << std::endl; }
};
class ScopedPtr
{
private:
Entity* m_Obj;
public:
ScopedPtr(Entity* entity)
: m_Obj(entity)
{
}
~ScopedPtr()
{
delete m_Obj;
}
Entity* operator->()
{
return m_Obj;
}
};
int main()
{
ScopedPtr entity = new Entity();
entity->Print();
std::cin.get();
return 0;
}
// 得到偏移量
// "指针->属性"访问属性的方法实际上是通过把指针的值和属性的偏移量相加,
// 得到属性的内存地址进而实现访问。
// 而把指针设为nullptr(0),然后->属性就等于0+属性偏移量。
// 编译器能知道你指定属性的偏移量是因为你把nullptr转换为类指针,
// 而这个类的结构你已经写出来了(float x,y,z),float4字节,
// 所以它在编译的时候就知道偏移量(0,4,8),所以无关对象是否创建
struct Vector3
{
float x, y, z;
}
int main()
{
int offset = (int)&(((Vector3*)nullptr)->y);
}Day 13 (2022.5.29)
// C++ 动态数组 (std::vector)
int main()
{
std::vector<Vertex> vertices;
vertices.push_back({1, 2, 3});
vertices.push_back({1, 2, 3});
// cout的v是Vertex的copy,这样会多一个copy操作
for (Vertex v : vertices)
std::cout << v << std::endl;
for (const Vertex& v : vertices)
std::cout << v << std::endl;
}// c++ std::vector的使用优化策略
#include <iostream>
#incldue <string>
#include <vector>
strcut Vertex
{
float x, y, z;
Vertex(float x, float y, float z)
: x(x), y(y), z(z)
{}
Vertex(const Vertex& vertex)
: x(vertex.x), y(vertex.y), z(vertex.z)
{
std::cout << "Copied!" << std::endl;
}
}
int main()
{
// 这种情况会调用6次拷贝构造函数
// vertex的三次初始化是在main的内存中初始化的,把他们放入vertices中,有三次copy
// vertices增容3次,copy 3次
std::vector<Vertex> vertices;
vertices.push_back(vertex(1, 2, 3));
vertices.push_back(vertex(4, 5, 6));
vertices.push_back(vertex(7, 8, 9));
// std::vector<Vertex> vertices(3) 这样子不仅是分配了3个Vertex的内存
// 而且会构造三个vertex对象,所以会报错
// reserve 提前申请内存,避免动态申请开销
// emplace_back 不是传递我们已经构建的vertex对象,我们只是传递了
// 构造函数的参数列表,它会在vertices内存中构建对象
std::vector<Vertex> vertices;
vertices.reserve(3);
vertices.emplace_back(vertex(1, 2, 3));
vertices.emplace_back(vertex(4, 5, 6));
vertices.emplace_back(vertex(7, 8, 9));
std::cin.get();
}// C++ 中使用库(静态链接)
// 我们将以二进制文件的形式进行链接,而不是或去实际依赖库的源代码并自己进行编译,
// 对于大多数严肃的项目,我推荐实际构建源代码(添加一个项目,该项目包含您的依赖库的源代码
// ,然后将其编译为静态或动态库),如果你拿不到源代码或者这只是一个快速项目,那么我倾向于
// 链接二进制文件,因为它会更快更容易。
// 今天我们只讨论处理二进制,确切的说,是GLFW库
// 典型的C++库的组织结构通常包含include(包含目录)和library(库目录)
// include是一堆我们需要使用的头文件,这样我们就可以实际使用预构建的二进制文件中的函数
// lib目录有那些预先构建的二进制文件,有动态库和静态库(并不是所有库都提供静态动态两种)
// 但GLFW提供了2种,因此我们可以选择静态链接还是动态链接
// 静态链接意味着这个库会被放在我的可执行文件中,在我的exe文件中,或者其它操作系统的可执
// 文件。而动态链接库是在运行时被链接的(程序运行时,装载动态链接库,在WindowsAPI中有个
// 叫loadLibrary的函数,会载入我的动态库,从中拉出函数,然后调用它,也可以在程序启动时
// 加载我的dll文件。
// 主要区别是,库文件是否被编译到exe或者链接到exe文件中,还是只是一个单独的文件,
// 在运行时你需要把它放在你的exe文件旁边或者某个地方,然后你的exe文件可以加载它。
// 静态链接更快,编译器或链接器可以在执行链接时优化,通常静态链接更好。
// include和lib文件都需要设置,对于编译器必须把它指向头文件(包含文件),这样就知道哪些
// 函数是可用的,然后就有了这些函数声明。然后还要将连接器指向库文件,这样就可以得到正确
// 的函数定义。
// lib-vc2015, lib-mingw 这些是不同编译器编译出来的版本(大概率任何一个版本都可以兼容,
// 只是尽量选择最接近的)
// lib-vc2015下有3个文件,glfw3.dll, glfw3.lib, glfw3dll.lib
// glfw3dll.lib实际上是一种静态库,它与dll是一起用的,这样我们就不需要实际询问dll
// 我们有一堆指向所有这些函数的函数指针吗,也就是说dll.lib实际上包含了.dll中所有
// 函数、符号的位置,所以我们可以在编译时链接他们
// C++创建一个动态链接库,编译后会生成两个可用的文件一个是lib文件一个是dll文件,
// 那么这个lib文件是干嘛的呢?
// 在使用动态库的时候,往往提供两个文件:一个引入库和一个DLL。引入库包含被DLL导
// 出的函数和变量的符号名,DLL包含实际的函数和数据。在编译链接可执行文件时,只需
// 要链接引入库,DLL中的函数代码和数据并不复制到可执行文件中,在运行的时候,再去
// 加载DLL,访问DLL中导出的函数。
// 1. Load-time Dynamic Linking 载入时动态链接
// 这种用法的前提是在编译之前已经明确知道要调用DLL中的哪几个函数,编译时在目标文
// 件中只保留必要的链接信息,而不含DLL函数的代码;当程序执行时,利用链接信息加载
// DLL函数代码并在内存中将其链接入调用程序的执行空间中,其主要目的是便于代码共享。
// 2. Run-time Dynamic Linking 运行时动态链接
// 这种方式是指在编译之前并不知道将会调用哪些DLL函数,完全是在运行过程中根据需要
// 决定应调用哪个函数,并用LoadLibrary和GetProcAddress动态获得DLL函数的入口地址。
// 关于用尖括号还是用引号的区别
// 实际上没有区别,弱国是引号的话,会先检查相对路径,如果没有找到任何相对于这个文
// 件的东西,它会检查编译器的include路径。我选这个的方法是,如果源文件在visual studio
// 中,GLFW.h 在我的解决方案中的某个地方,就用引号。如果完全是一个外部依赖,或外部的库
// 不在visual studio 中和我实际解决方案一起编译,那就用尖括号,表示它实际上是外部的// 指定头文件目录
// 指定库(library)目录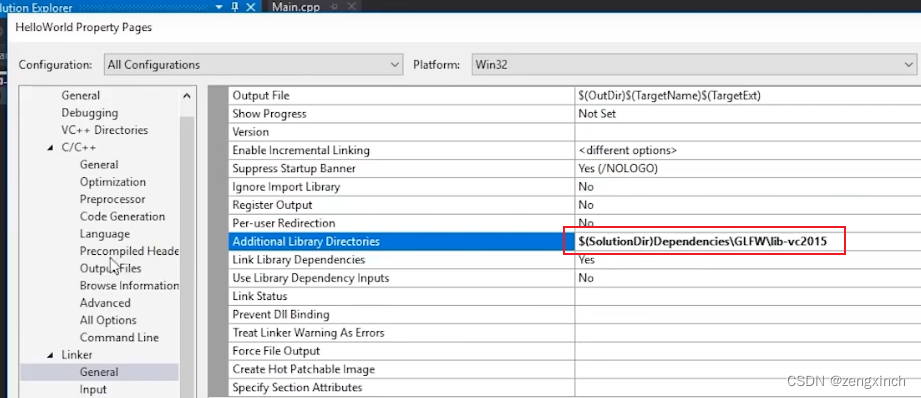
// 指定相对库目录的库文件的名称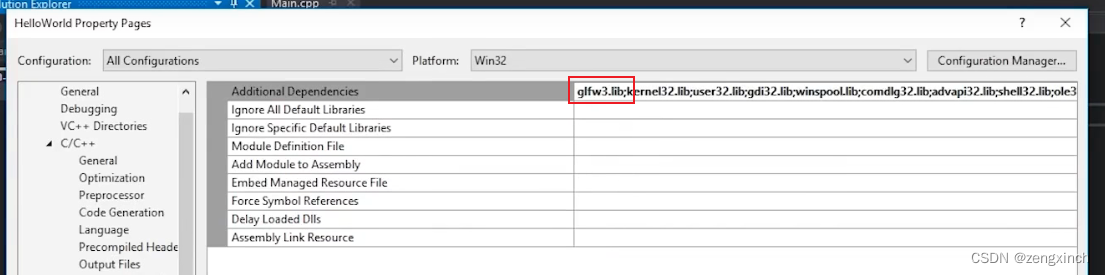
// 在当前文件写一个函数的声明,它会自动在lib文件夹中的所有文件找它的实现
// 即使没有include它的头文件(头文件通常只是用来声明的)
//
// 你自己声明一个c语言函数(不包含它的头文件,只想用这个函数),extern "C" int glfwInit();Day 14 (2022.5.30)
// C++ 中使用动态库
// "静态的"动态库的版本,应用程序现场需要这个动态链接库,已经知道里面有什么函数,
// 可以使用什么。另一种版本是,想要任意加载这个动态库,甚至不知道里面有什么,但
// 想取出一些东西,或者想用它做很多事。
//
// 1、 _declspec(dllexport)与_declspec(dllimport)是相互呼应,只有在DLL内部用
// dllexport作了声明,才能在外部函数中用dllimport导入相关代码。
// 2、如果vs中的dll项目内部的函数前面都没有 _declspec(dllexport),则无法生成导
// 出库lib,只有dll生成。
// 3、lib库原理上应该是不做链接过程的,我在一个lib项目上,故意犯下链接错误,编译
// 并不报错。另外,我的一个lib项目,想把opencv的dll库包进来,成为一个包含了opencv
// 功能的lib库,是不行的,因为在这个lib项目中,在vs编译器中都找不到linker选项,再
// 次说明lib库不做链接。
// 4、回到cherno的问题,因为这个项目已经用了引导库lib,所以不需要_declspec(dll
// import),就已经能够使用dll库了。lib就是起到定位dll的作用,所以用不用这个
//_declspec(dllimport)都无所谓。但如果此项目不用lib引导库,那必须使用
// _declspec(dllimport)来定位dll中的导出函数。
//
//预处理器中设置GLFW_DLL就相当于在源文件里面添加了#define GLFW_DLL,同时由于作者是
// WIN32平台就会有_WIN32这个宏定义,(在GFLW头文件那里面是一串关于GLFWAPI的宏定义)
// 所以这种情况下就会将GLFWAPI定义为_declspec(dllimport),相当于在声明函数时加上了
// _declspec(dllimport),如果不加GLFW_DLL的宏定义就相当于啥都没有。作者就是想问声明
// 函数时无论加不加_declspec(dllimport),为什么都能正常运行,具体原因就是作者在链接
// 器配置里面已经附加了glfw3dll.lib所以加不加_declspec(dllimport)效果一样都能正常运
// 行,glfw3dll.lib的作用作者在前面有具体说明,当然推荐还是加上GLFW_DLL的定义(前面的
// 注释说了,如果你的应用程序要链接这个DLL最好确保加上这个GLFW_DLL定义)
// 将dll文件与exe放在一起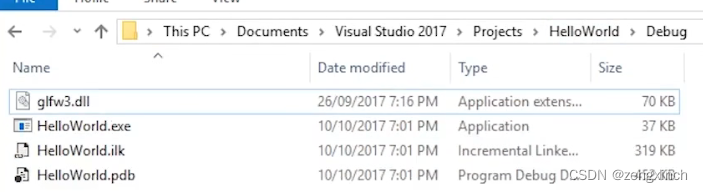
// C++ 创建与使用库
// 如何在Visual Studio 中建立多个项目,以及如何创建一个库让所有项目都能使用
// 一个解决方案下有两个项目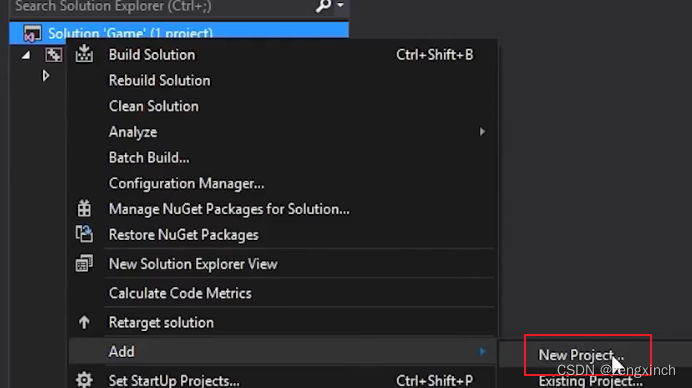
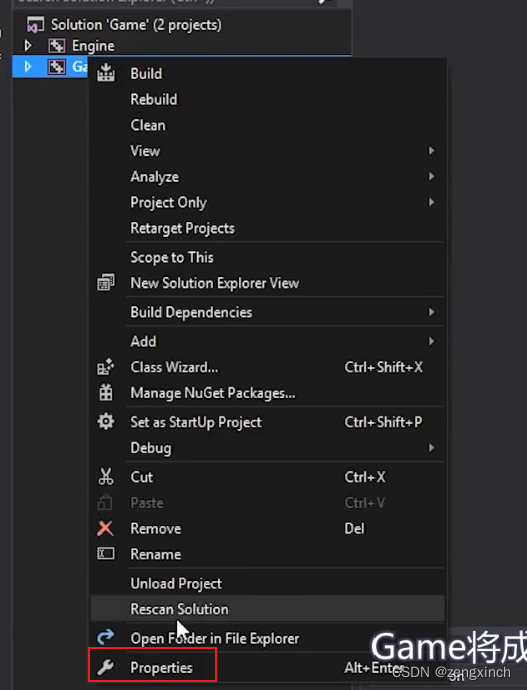
// 设置Game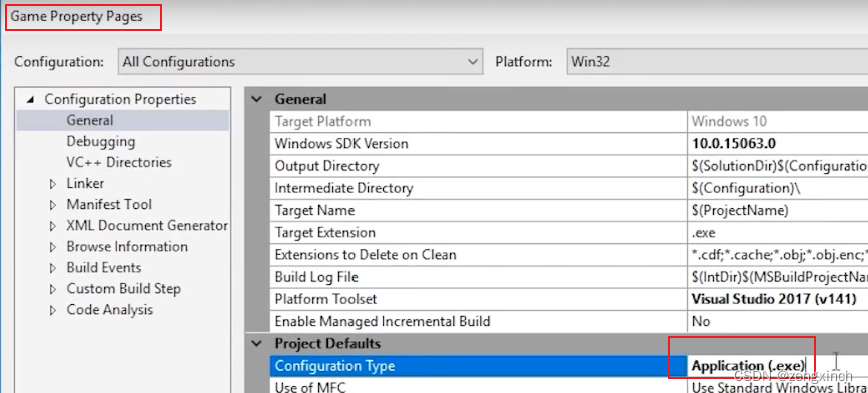
// 设置Engine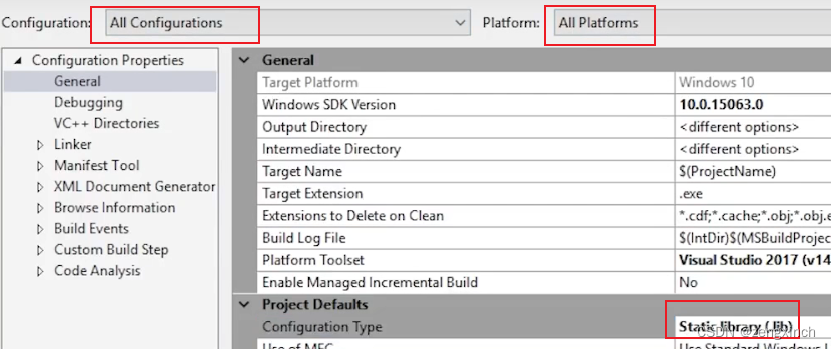
// 为了在game中使用engine,需要设置game的property
// 把engine生成的lib作为链接器的输入,但我们不需要这么做
// Visual Studio可以为我们自动做这个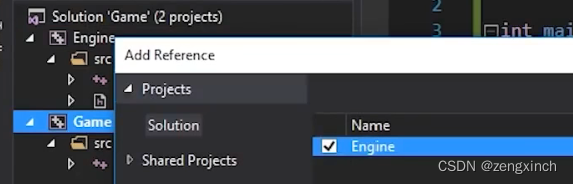
// Aplication.cpp (Game project)
#include "Engine.h"
#incldue <iostream>
int main()
{
engine::PrintMessage();
return 0;
}
// Engine.h (Engine project)
#pragma once
namespace engine{
void PrintMessage();
}
// Engine.cpp (Engine project)
#include "Engine.h"
#include <iostream>
namespace {
void PrintMessage()
{
std::cout << "Hello World!" << std::endl;
}
}Day 15 (2022.6.1)
// C++ 模板
#include <iostream>
#include <string>
// 这不是一个实际的函数,只有我们调用这个函数的时候,基于传递的参数
// 这个函数才被创建出来,并作为源代码被编译
// 也可也用class T,一样
template<typename T>
void Print(T value)
{
std::cout << value << std::end;
}
// 将类转化成一个模板?
template<typename T, int N>
class Array
{
private:
T m_Array[N];
public:
int GetSize() const { return N; }
};
int main()
{
Print(5);
Print<int>(5);
Print("555");
Array<std::string, 5> array;
std::cin.get();
return 0;
}// C++ 堆与栈内存的比较
// 在栈上分配内存是按地址连续分配的
// new 关键字实际上调用了一个叫做malloc的函数,memory allocate,你的程序会跟踪一个叫做空闲
// 列表的东西,它会跟踪哪些内存块是空闲的。
// 在堆上分配内存是一堆事情(慢),而在栈上分配内存只需要一条cpu指令(快)// C++ 宏
#include <iostream>
#include <string>
#define LOG(x) std::cout << x << std::endl;
int main()
{
LOG("Hello");
std::cin.get();
}
// 在Debug下添加宏PR_DEBUG 到 Preprocessor Definitions
// 在Release就不会输出消息
// 反斜杠 \ 是换行符,反斜杠后必须直接换行
#include <iostream>
#include <string>
#ifdef PR_DEBUG
#define LOG(x) std::cout << x << std::endl;
#else
#define LOG(x)
#endif
int main()
{
LOG("Hello");
std::cin.get();
}Day 16 (2022.6.2)
// C++ 静态数组 std::array
// 静态数组可以返回数组大小 size(),有边界检查(可以关掉)
// vector是在堆上创建的,array是在栈上创建的
// 方法1
#include <array>
template<int N>
void Print(const std::array <int, N>& arr)
{
for (int i = 0; i < arr.size(); i++)
}
template<typename T>
void Print(const T& arr)
{
for (int i = 0; i < arr.size(); i++)
}
int main()
{
std::array<int, 5> a;
a[0] = 1;
a[1] = 2;
Print(a);
return 0;
}Day 17 (2022.6.3)
// 原始函数指针
// 将一个函数赋值给一个变量的方法
void HelloWorld()
{
std:: cout << "Hello World!" << std::endl;
}
int main()
{
// function是函数指针的名字,第二个括号是参数列表
// auto function = HelloWorld;
// 也可也这样写,HelloWorld是函数地址(隐式转换),相当于&HelloWorld
void(*function)() = HelloWorld;
// 使用typedef
typedef void(*HelloWorldFunction)();
HelloWorldFunction function = HelloWorld;
function();
}
#include <iostream>
#include <vector>
void PrintValue(int value)
{
std::cout << "Value: " << value << std::endl;
}
void ForEach(const std::vector<int>& values, void(*func)(int))
{
for (int value : values)
func(value);
}
int main()
{
std::vector<int> values = {1, 2, 3, 4, 5};
ForEach(values, PrintValue);
return 0';
}
// lambda 本质上就是一个普通函数,只是它不像普通函数那样声明,像匿名函数
// [] 叫做捕获方式,也就是如何传入传出参数, () 参数列表,{} 函数体
ForEach(values, [](int value) {std::cout << "value:" << value << std::endl; });// C++ lambda的使用
int a = 5;
auto func = [=]() mutable {a = 1; std::cout << "a:" << a << std::endl; };
// 如果要捕获变量,则函数参数要转换为
#include <functional>
void ForEach(const std::vector<int>& values, std::function<void(int)>& func)
#include <iostream>
#include <vector>
#incldue <algorithm>
int main()
{
std::vector<int> values = {1, 2, 3, 4, 5};
auto it = std::find_if( values.begin(), values.end(), [](int value) { return value > 3;} );
std::cout << *it << std::endl;
}// using namespace
// 绝对不要在头文件中使用
// 如果同时用两个 using namespace, 可能会存在两个命名空间有同样的函数,这样调用就可能会出现问题Day 18 (2022.6.3)
// c++ 命名空间
namespace apple
{
namespace function
{
void print(string& str) {};
}
}
int main()
{
// using apple::function::print
// namespace a = apple::function;
using namespace apple;
using namepsace function;
}// C++ 线程
// join 在当前线程等待这个线程完成工作(阻塞当前线程,直到另一线程完成)
#include <iostream>
#include <thread>
static bool s_Finished = false;
void DoWork()
{
using namespace std::literals::chrono_literals;
while (!s_Finished)
{
std::cout << "Working...\n";
std::this_thread:sleep_for(1s);
}
}
int main()
{
std::thread worker(DoWork);
std::cin.get();
s_Finished = true;
worker.join();
std::cout << "Finished." << std::endl;
std::cin.get();
return 0;
}Day 19 (2022.6.6)
// c++ 计时
#include <iostream>
#include <chrono>
#include <thread>
struct Timer
{
std::chrono::time_point<std::chrono::steady_clock> start, end;
std::chrono::duration<float> duration;
Timer()
{
start = std::chrono::high_resolution_clock::now();
}
~Timer()
{
end = std::chrono::high_resolution_clock::now();
duration = end - start;
std::cout << "Timer took " << duration.count() * 1000 << "ms" << std::endl;
}
};
void Function()
{
Timer timer;
for (int i = 0; i < 100; i++);
}
int main()
{
/*using namespace std::literals::chrono_literals;
auto start = std::chrono::high_resolution_clock::now();
std::this_thread::sleep_for(1s);
auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration<float> duration = end - start;
std::cout << duration.count() << "s =" << std::endl;*/
Function();
std::cin.get();
return 0;
}Day 20 (2022.6.7)
// C++ 多维数组
// 多维数组就是指针的指针
// 分配一个5 * 5的二维数组,假如访问完第一个指针的5个整数后
// 开始访问第二个指针,这个时候存在缓存不命中(这两个指针指向的内存不连续)
// 会导致我们从ram中获取数据,速度比一维数组慢
// new int*[50] 是指有50个指针,每个指针都有50个整数
int main()
{
int** a2d = new int*[50];
for (int i = 0; i < 50; i++)
a2d[i] = new int[50];
int*** a3d = new int**[50];
for (int i = 0; i < 50; i++)
{
a3d[i] = new int*[50];
for (int j = 0; j < 50; j++)
{
int** ptr = a3d[i];
a3d[i][j] = new int[50];
}
}
// 删除操作
for (int i = 0; i < 50; i++)
{
delete[] a2d[i];
}
delete[] a2d;
}// C++ 排序
#include <iostream>
#include <vector>
#include <algorithm>
#include <functional>
int main()
{
std::vector<int> values = { 3, 5, 1, 2, 4 };
// 如果返回true,a在b前面
std::sort(values.begin(), values.end(), [](int a, int b)
{
return a < b;
});
for (int value : values) std::cout << value << std::endl;
std::cin.get();
return 0;
}Day 20 (2022.6.9)
// C++ 类型双关
// 假设一直使用整数类型,但现在需要把这段内存当作double或class类型
// 我们可以很容易的绕过类型系统
// 假设我们有一个类,我们想把它写成一个字节流,假设它是一个基本类型的结构,
// 并且没有指向内存中其它地方的指针,那么我们就可以重新解释整个结构或者类,
// 将它作为一个字节数组,然后写出来
int a = 50;
double value = *(double*)&a;
// 不想创建一个全新的变量,但这个操作是很危险的
// 如果赋值 value = 0.0,那么会对a的八个字节内存而不是
// 4个进行操作
int a = 50;
double& value = *(double*)&a;
#include <iostream>
struct Entity
{
int x, y;
};
int main()
{
Entity e = {5, 8};
int* position = (int*)&e;
std::cout << position[0] << "," << position[1] << std::endl;
// y = 8;
int y = *(int*)((char*)&e + 4);
std::cin.get();
}Day 21 (2022.6.10)
// C++ union(联合体)
// 通常人们用联合体来做的事情是和类型双关紧密联系的
// 通常union是匿名使用的,但是匿名union不能含有成员函数
#include <iostream>
int main()
{
struct Union
{
// 如果它是匿名的,它只是一种数据结构,并没有添加任何东西
union
{
float a;
int b;
};
};
Union u;
u.a = 2.0f;
// 把2的字节当成float输出
std::cout << u.a << " " << u.b << std::endl;
std::cin.get();
return 0;
}
// ******************************************* //
#include <iostream>
struct Vector2
{
float x, y;
};
struct Vector4
{
union
{
struct
{
float x, y, z, w;
};
struct
{
Vector2 a, b;
};
};
};
void PrintVector(const Vector2& vector)
{
std::cout << vector.x << ", " << vector.y << std::endl;
}
int main()
{
Vector4 vector = { 1.0f, 2.0f, 3.0f, 4.0f };
PrintVector(vector.a);
PrintVector(vector.b);
std::cout << vector.x << std::endl;
std::cin.get();
return 0;
}Day 22 (2022.6.12)
// C++ 虚析构函数
// 类B派生于类A,我们想把类B引用为类A,但它实际上是类B
// 然后你想要删除它,你希望运行的是B的析构函数,而不是A的
//
// 普通方法标记为virtual,那么它就可以被覆写,
// 析构函数标记为virtual,则意味着加上一个析构函数
#include <iostream>
class Base
{
public:
Base() { std::cout << "Base constructor!\n"; }
~Base() { std::cout << "Base destructor!\n"; }
void print() { std::cout << "a"; }
};
class Derived : public Base
{
public:
Derived() { std::cout << "Derived constructor!\n"; }
~Derived() { std::cout << "Derived destructor!\n"; }
void print() { std::cout << "b"; }
};
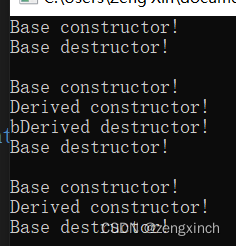
int main()
{
Base* base = new Base();
delete base;
std::cout << "\n";
Derived* derived = new Derived();
derived->print();
delete derived;
std::cout << "\n";
Base* poly = new Derived();
delete poly;
std::cin.get();
return 0;
}
Day 22 (2022.6.15)
// C++ 类型转换
// C 和 C++ 两种风格转换
// C 风格
double value = 5.25;
int a = (int)value;
// C++ 风格
double value = 5.25;
int a = static_cast<int>(value);
// 主要有四种cast,他们不做任何C风格不能做的事情
// static_cast, reinterpret_cast, dynamic_cast, const_cast
// static_cast static_cast 用于进行比较“自然”和低风险的转换,如整型和浮点型、字符型之间的互相
// 转换,不能用于指针类型的强制转换
// reinterpret_cast 用于进行各种不同类型的指针之间强制转换
// const_cast 仅用于进行去除 const 属性的转换
// dynamic_cast 不检查转换安全性,仅运行时检查,如果不能转换,返回nullDay 23 (2022.6.18)
// C++ 条件与操作断点
// 操作断点可以在控制台输出你想要输出的东西,击中断点时不中断程序(可以选择是否继续)
// 条件断点,满足特定情况才输出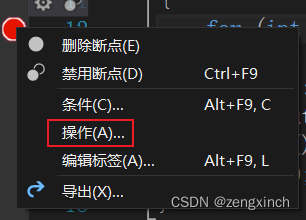
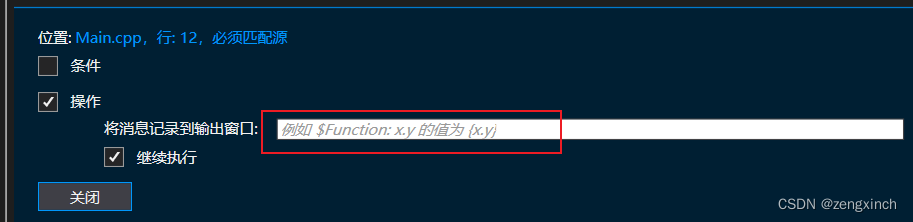
Day 24 (2022.6.19)
// C++ 中的安全
// 智能指针本质上是围绕原始指针做了额外的辅助代码,以便自动化所有事情(本质是删除和释放内存)Day 25 (2022.6.21)
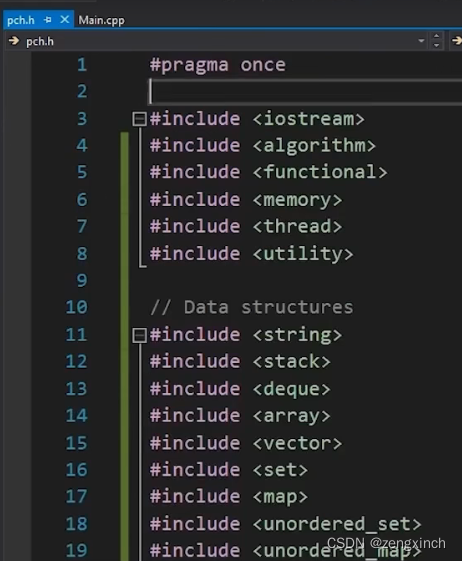
// C++ 预编译头文件
// 预编译的头文件实际上是让你抓取一堆头文件,并将他们转换成编译器可以使用的格式,
// 而不必一遍又一遍地读取这些头文件
// 不要将频繁改变的东西放入预编译头(如stl,windows.h)
// Visual Studio 通常将预编译头文件写成 stdafx.h,你自己建的话可以随便取名字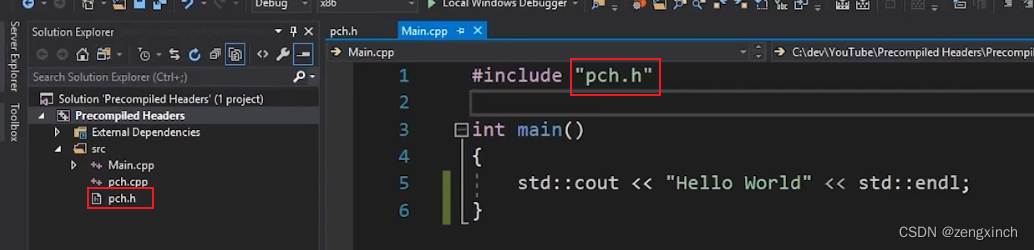
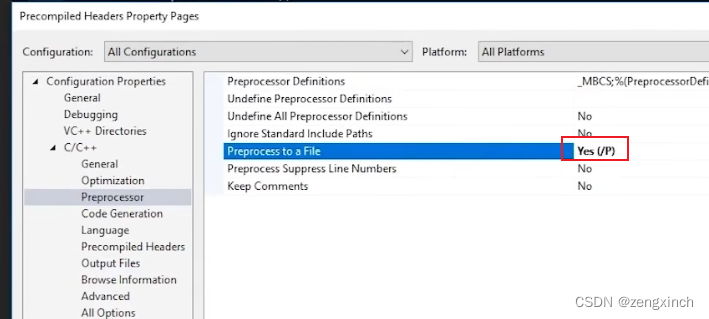
// 对于C++来说,我们需要创建一个包含头文件的CPP文件
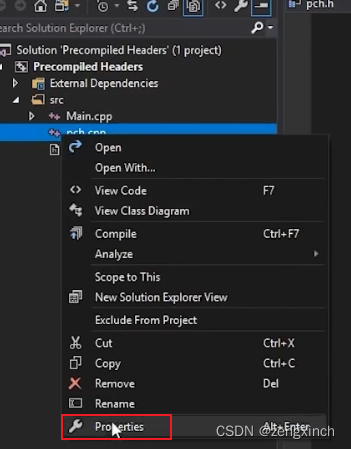
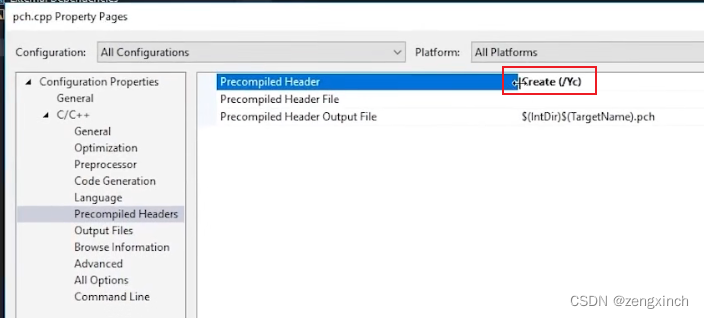
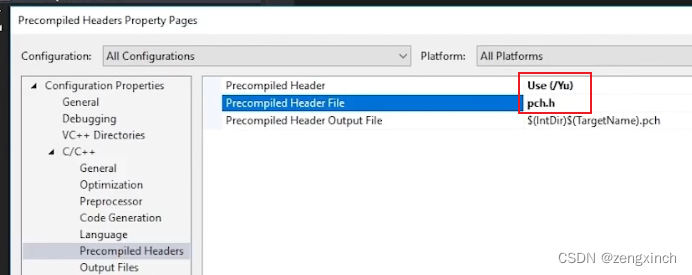
// 然后点击这个CPP文件的properties选择use precompiled headers
// 然后到整个项目的properties下选择ues
//
Day 26 (2022.6.22)
// C++ dynamic_cast
// dynamic_cast 是专门用于沿继承层次结构进行的强制类型转换
// 用dynamic_cast 的类必须要有虚函数Day 27 (2022.6.25)
// C++ 基准测试
#include <iostream>
#include <chrono>
#include <memory>
class Timer
{
public:
Timer()
{
m_StartTimepoint = std::chrono::high_resolution_clock::now();
}
~Timer()
{
Stop();
}
void Stop()
{
auto endTimepoint = std::chrono::high_resolution_clock::now();
auto start = std::chrono::time_point_cast< std::chrono::microseconds >(m_StartTimepoint).time_since_epoch().count();
auto end = std::chrono::time_point_cast< std::chrono::microseconds >(endTimepoint).time_since_epoch().count();
auto duration = end - start;
std::cout << duration << "ms" << std::endl;
}
private:
std::chrono::time_point< std::chrono::high_resolution_clock > m_StartTimepoint = std::chrono::high_resolution_clock::now();
};
int main()
{
int value = 0;
{
Timer timer;
for (int i = 0; i < 1000000; i++)
value += 2;
}
std::cout << value << std::endl;
return 0;
}// C++ 结构化绑定(Structured bindings, C++17)
#include <iostream>
#include <string>
#include <tuple>
struct Person
{
std::string Name;
int Age;
};
std::tuple<std::string, int> CreatePerson()
{
return { "Cherno", 24 };
}
Person CreatePersonS()
{
return{ "Cherno", 24 };
}
int main()
{
/*auto person = CreatePerson();
std::string& name = std::get<0>(person);
int age = std::get<1>(person);
std::string name;
int age;
std::tie(name, age) = CreatePerson();*/
auto p = CreatePersonS();
std::cout << p.Name << std::endl;
std::cin.get();
return 0;
}
#include <iostream>
#include <string>
#include <tuple>
std::tuple<std::string, int> CreatePerson()
{
return { "Cherno", 24 };
}
int main()
{
auto[name, age] = CreatePersonS();
std::cout << name << std::endl;
std::cin.get();
return 0;
}Day 28 (2022.6.26)
// C++ 如何处理Optional数据 (C++ 17)
// 三种不同的新类型(Optional是其中之一),可以处理那些可能存在,也可能不存在的数据
#include <iostream>
#include <optional>
#include <fstream>
std::optional<std::string> ReadFile(const std::string& filepath)
{
std::ifstream stream(filepath);
if (stream)
{
std::string result;
// read file
stream.close();
retrun result;
}
return{};
}
int main()
{
std::optional<std::string> data = ReadFile("data.txt");
if (data) // if (data.has_value())
{
// std::string& result = *data;
std::string result = data.value();
// 其中xxx作为默认值,如果存在数据返回数据,不存在返回xxx
// std::string result = data.value_or(xxx)
}
else{}
return 0;
}Day 29 (2022.6.27)
// C++ 单一变量存放多种类型的数据
// std::variant 允许你列出所有可能的类型,然后你可以决定它是什么
// data.index() 会告诉我们数据当前存储在哪个索引中
// 是检查的类型就返回其指针,否则返回空指针
// auto value = std::get_if<std::string>(&data);
#include <iostream>
#include <variant>
int main()
{
std::variant<std::string, int> data;
data = "Cherno";
std::cout << std::get<std::String>(data) << "\n";
data = 1;
std::cout << std::get<int>(data) << "\n";
}Day 28 (2022.6.28)
// 如何在 C++ 单个变量中存储任意类型的数据 (std::any, C++ 17)
#include <iostream>
#include <any>
int main()
{
std::any data;
data = 2;
data = "Cherno";
// 如果不能这样转换会抛出异常
std::string str = std::any_cast<std::string>(data);
std::cin_get();
}Day 29 (2022.6.29)
// C++ 如何让C++运行的更快
// std::async & futures 这个感觉讲的太快了,还是自己搜教程吧-----------------------------------------------------------------------------------------------















 3285
3285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









