







学习来源https://www.youtube.com/user/TheChernoProject/playlists
1. vs有两种默认运行方式,debug或release,其中在项目的C++属性栏中,debug模式下里面的Optimization是默认关闭的,而release模式是默认开启的,Optimization会自行简化一些操作,加速程序运行,但是不适合Debug。
2. 头文件是在预处理阶段编译的,实际编译时,Compiler编译的只有cpp文件,每一个cpp文件都会被单独编译,然后每一个cpp都会生成一个其对应的(vs生成的是.obj格式)文件。VS里面按ctrl + F7可以单独编译一个Cpp。
3. 什么是Translation Unit
The text of the program is kept in units called source files in this International Standard. A source file together with all the headers (17.4.1.2) and source files included (16.2) via the preprocessing directive #include, less any source lines skipped by any of the conditional inclusion (16.1) preprocessing directives, is called a translation unit. [Note: a C++ program need not all be translated at the same time. ]
举个例子:
有两个cpp文件,它们互相不包含,互不关联,那么这是两个translation unit,每一个unit分别包含了其cpp文件和cpp文件包含的头文件,会生成两个.obj文件。
如果两个cpp文件A和B, A中有这么一句代码#include “B.cpp”,尽管各自编译都能生成各自的.obj文件,那么这些加起来也只是一个translation unit,注意,在代码中不要写这种代码#include “B.cpp”,否则相当于把B的所有内容复制粘贴到了A中,再进行Link操作会出现函数重定义的问题,这也不是一个好的编码习惯。
4. #include<header.h> 的底层实现原理
实际上很简单,在预处理过程中,compiler会找到这个文件,然后把文件里面所有的内容复制粘贴到写了这一行代码的cpp中,所以#include<...>通常都写在前面,具体参见第五条。
5. C++的预处理是怎么实现的
生成预处理文件
通过vs的项目属性参数的设置,可以把所有的预处理过程,也就是预处理后得到的新的cpp文件,将其输出到文件夹,如下图所示。
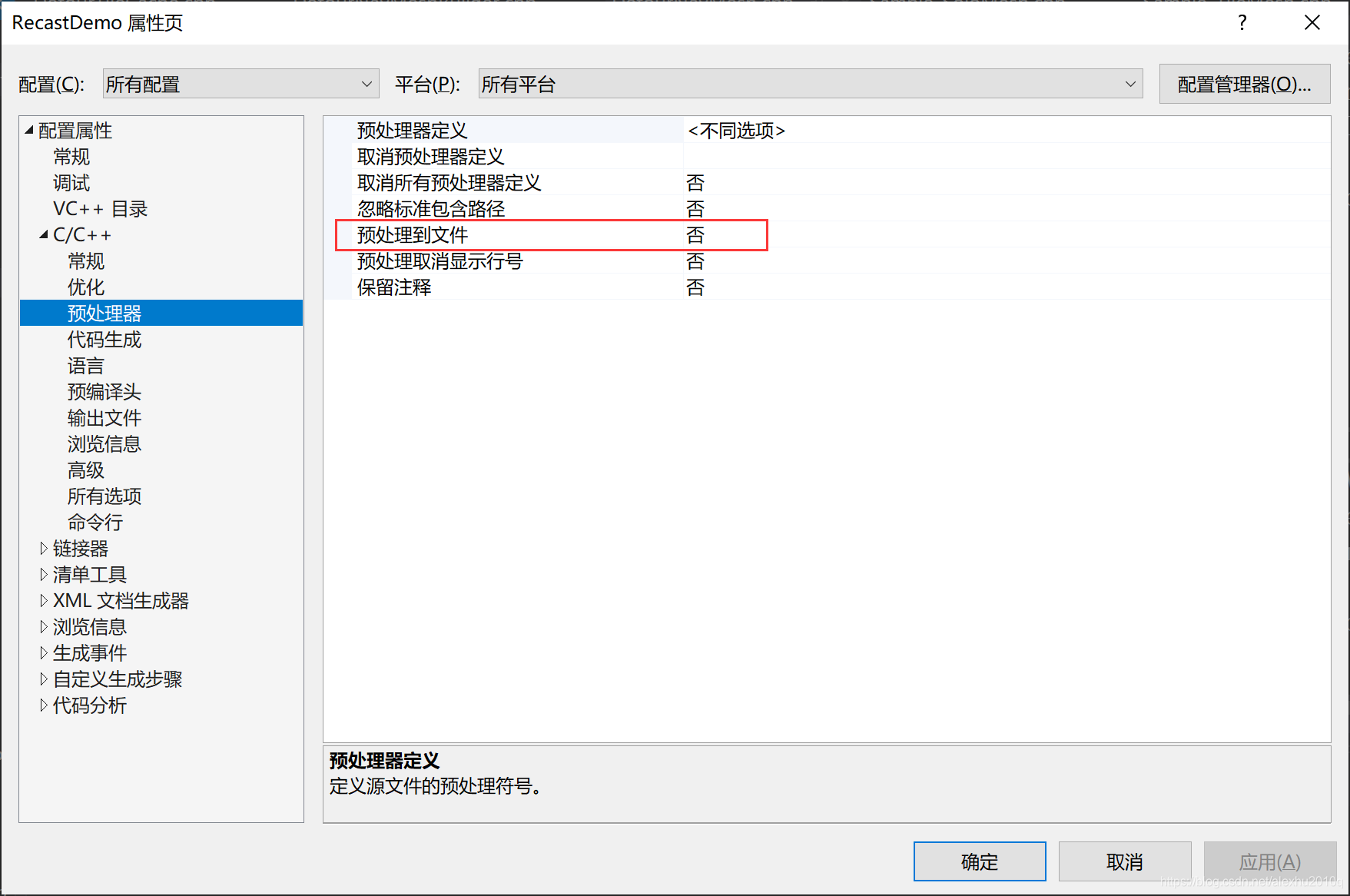
注意下面的提示,勾选这个不能让程序正常编译运行
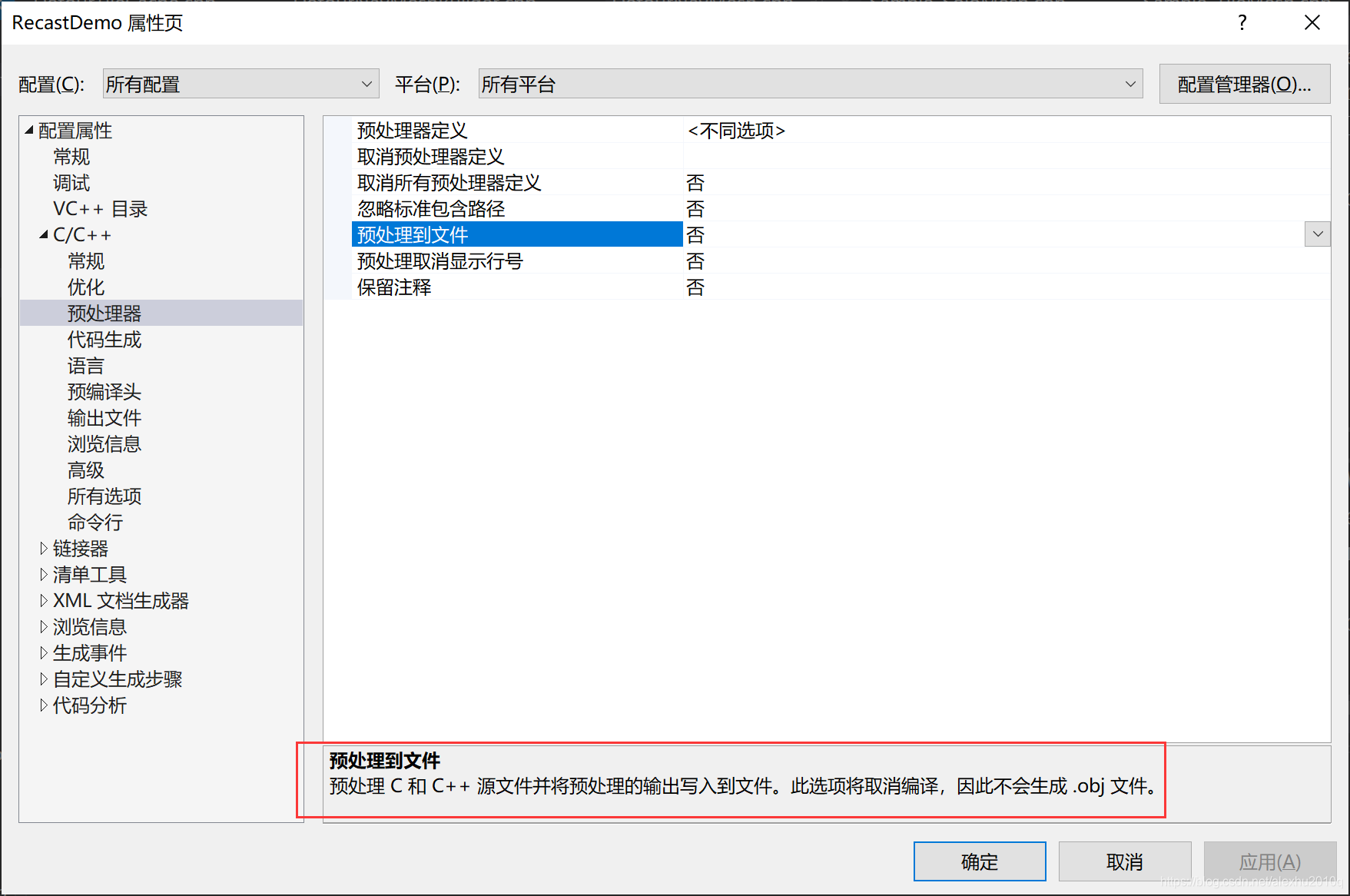
如果选择预处理到文件,不会生成.obj文件,会生成一个.i文件。
#include如何实现的预处理操作
举两个例子,对于下述简单的例子,不能运行,但是可以进行单独编译(ctrl + F7):
第一个例子:建立一个cpp文件和一个.h文件
.h文件如下,没有看错,就是一个单纯的}:
}
cpp文件如下:
int main()
{
int a = 2;
a++;
#include"test.h"
对cpp进行编译,显示编译成功:
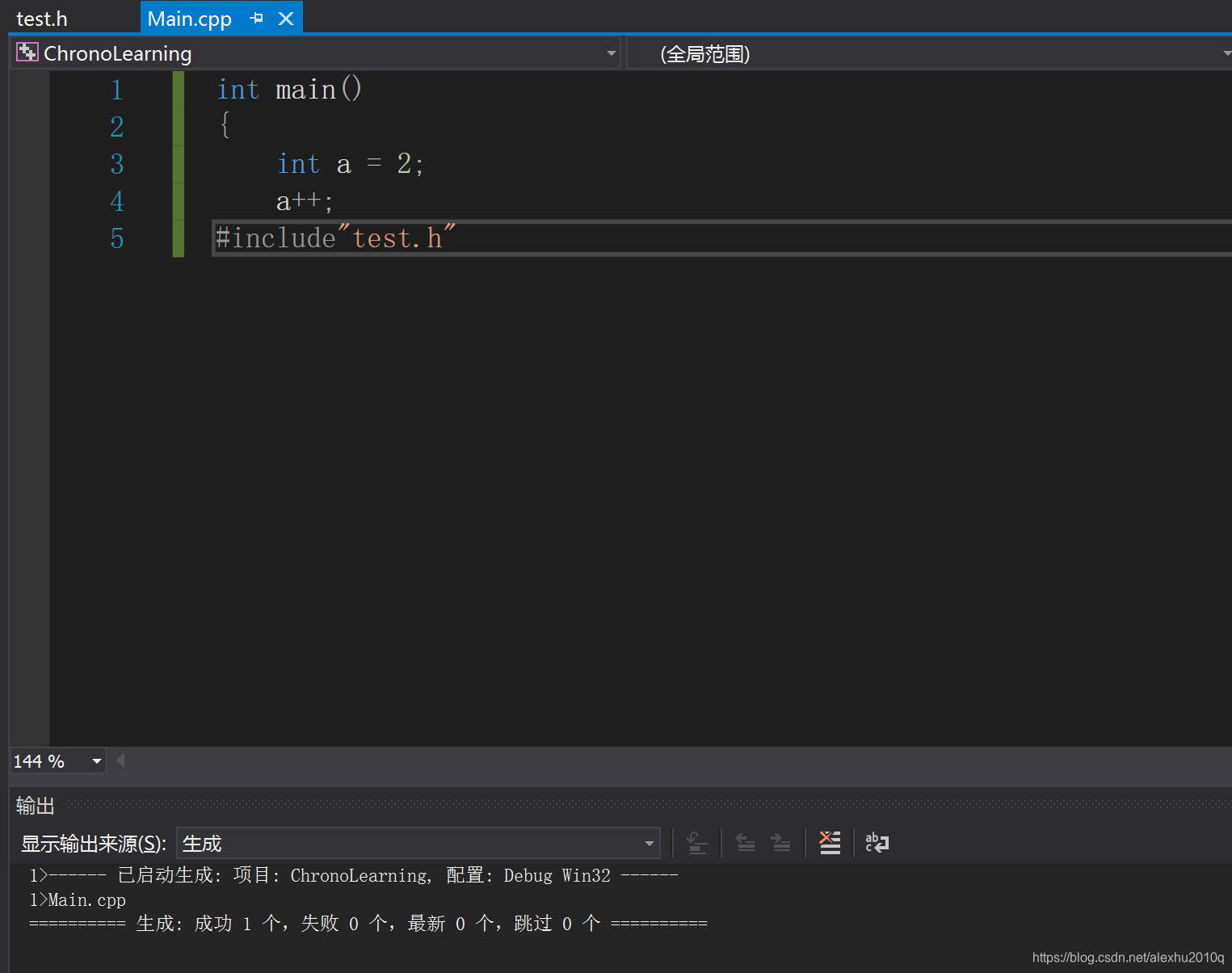
打开Debug文件夹下的Main.i文件:

以下是Main.i文件的全部内容:
#line 1 "c:\\users\\wutong\\source\\repos\\chronolearning\\chronolearning\\main.cpp"
int main()
{
int a = 2;
a++;
#line 1 "c:\\users\\wutong\\source\\repos\\chronolearning\\chronolearning\\test.h"
}
#line 6 "c:\\users\\wutong\\source\\repos\\chronolearning\\chronolearning\\main.cpp"
可以看出,预处理器先打开main.cpp,执行到#include"test.h"时,就直接把该文件里的内容搬过来,仅此而已,就是这么简单。
第二个例子,正常的cpp如下
#include<iostream>
int main()
{
std::cout << 1;
}
编译后,打开Debug文件夹下的Main.i文件:

打开文件,下面是文件的开头内容:
#line 1 "c:\\users\\wutong\\source\\repos\\chronolearning\\chronolearning\\main.cpp"
#line 1 "c:\\program files (x86)\\microsoft visual studio\\2017\\community\\vc\\tools\\msvc\\14.16.27023\\include\\iostream"
#pragma once
#line 1 "c:\\program files (x86)\\microsoft visual studio\\2017\\community\\vc\\tools\\msvc\\14.16.27023\\include\\istream"
...
可以看到第一行表示打开了main.cpp,读取到了第一行#include<iostream>,然后继续打开iostream文件, 然后开始进一步打开iostream文件里的istream文件,这个过程有点类似于递归函数,一层层的展开文件,最后合并成一个大的文件。
文件的末尾如下所示:

可见前面的5W多行全是iostream文件里的内容,所以整个Main.i文件,,由于iostream文件的存在,第二个例子的文件会比第一个Main.h文件大得多, 就是预处理过后我们真实的cpp的大小。
经过上述两个例子,可以看出#include<file>指令就是单纯的打开该文件,把该文件里的所有内容粘贴回来,代替这一行而言, 就这么简单。
理解#include的实际预处理操作后,了解其他的就不怎么难了
#define、#if预处理操作
所有在C++里面带#符号的语句都是预处理语句,举个例子,定义Main.cpp
#define sss int
int main()
{
sss a = 2;
a++;
}
编译后得到的Main.i文件内容如下:
#line 1 "c:\\users\\wutong\\source\\repos\\chronolearning\\chronolearning\\main.cpp"
int main()
{
int a = 2;;
a++;
}
可以看出,没有任何#define字样,原来的sss a = 2 变成了 int a = 2,也就是说,如果#include<header.h>起到的是复制粘贴作用,那么这里的#define起到的是单纯的替换作用,甚至连一句带#号的注释都没有留下。
编译期间会检查语法错误, 但预处理过程不会
如果我们开启生成预处理文件的功能,用来生成相应的.i文件,我们甚至可以瞎写,来进行测试,例子如下。但是如果要能顺利生成obj文件,那还是得满足基本的语法条件。
随便定义一个类型:
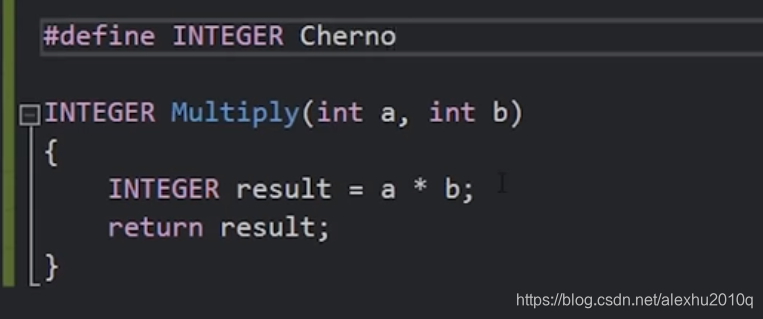
预处理后会得到以下文件,虽然不能正确编译,但是预处理过程是没问题的:
6. C++生成的.obj文件
前面提到过,每一个cpp文件在完成编译过程后,都会生成一个.obj文件,.obj文件是纯粹的2进制的机器语言,也就是Machine Code,纯粹的机器语言我们是无法阅读的,但通过VS2017,我们可以将.obj文件转换成一种汇编语言的.asm文件,可以通过阅读.asm文件来了解计算机具体干了什么。
具体设置如下,把编译文件输出方式,从无列表改成仅有程序集的列表(/FA):
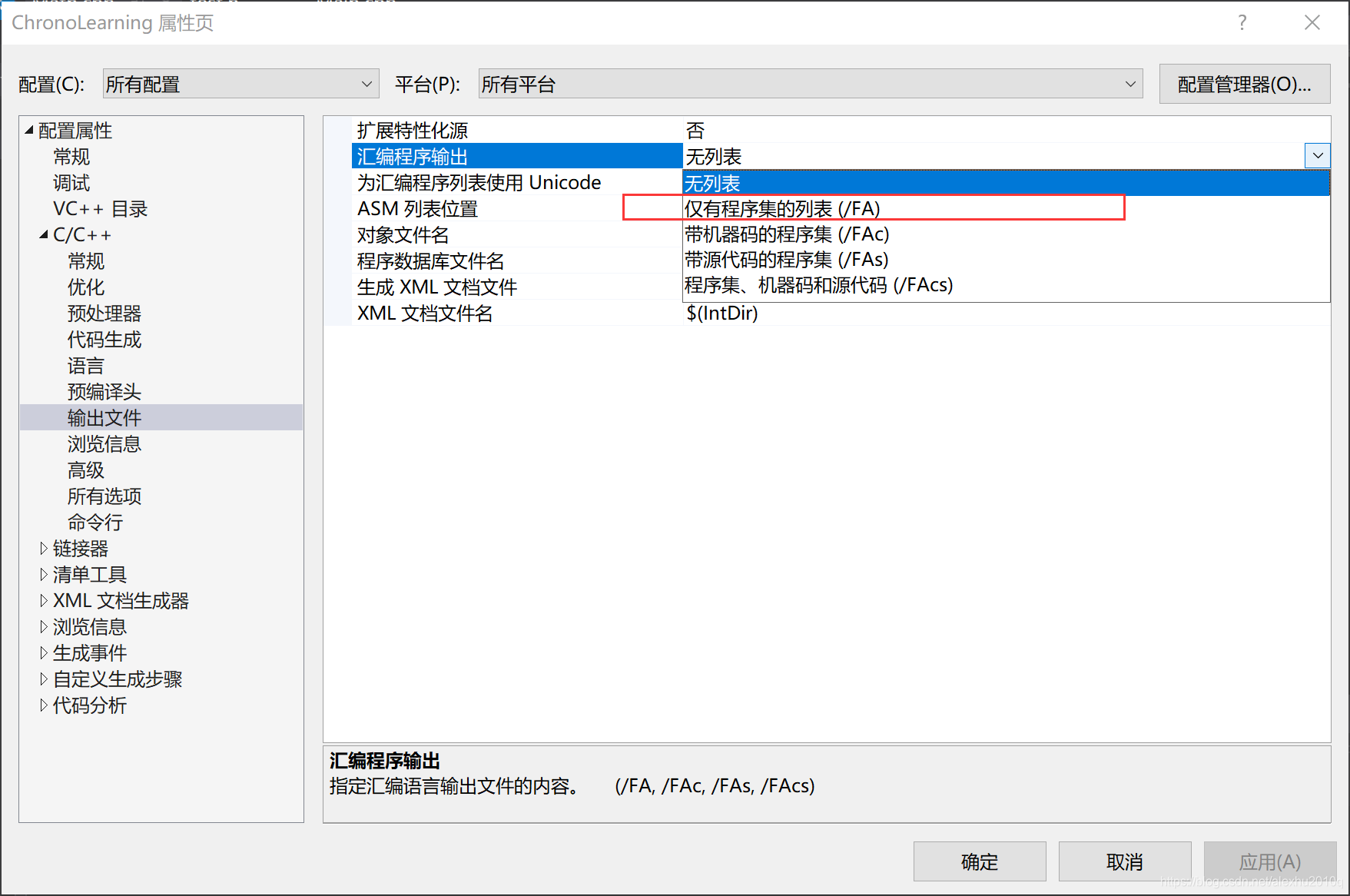
勾选之后,再编译文件,会在对应的路径生成对应的.asm文件(assembly),里面记载了程序生成的机器汇编语言,而且勾不勾选Promotion选项,是Debug和Release模式的重要差别之一,勾选了之后,会发现生成的.asm文件会自动对很多步骤进行优化,生成的指令集明显比不勾选生成的指令集内容要少,日后有兴趣可以仔细研究一下这块内容。
7. Linker的作用
Linker的作用有以下几点
- 将所有的
.obj文件合成起来,生成一个exe(即使只有一个.obj文件也需要Linker) - 需要通过Linker找到函数的入口
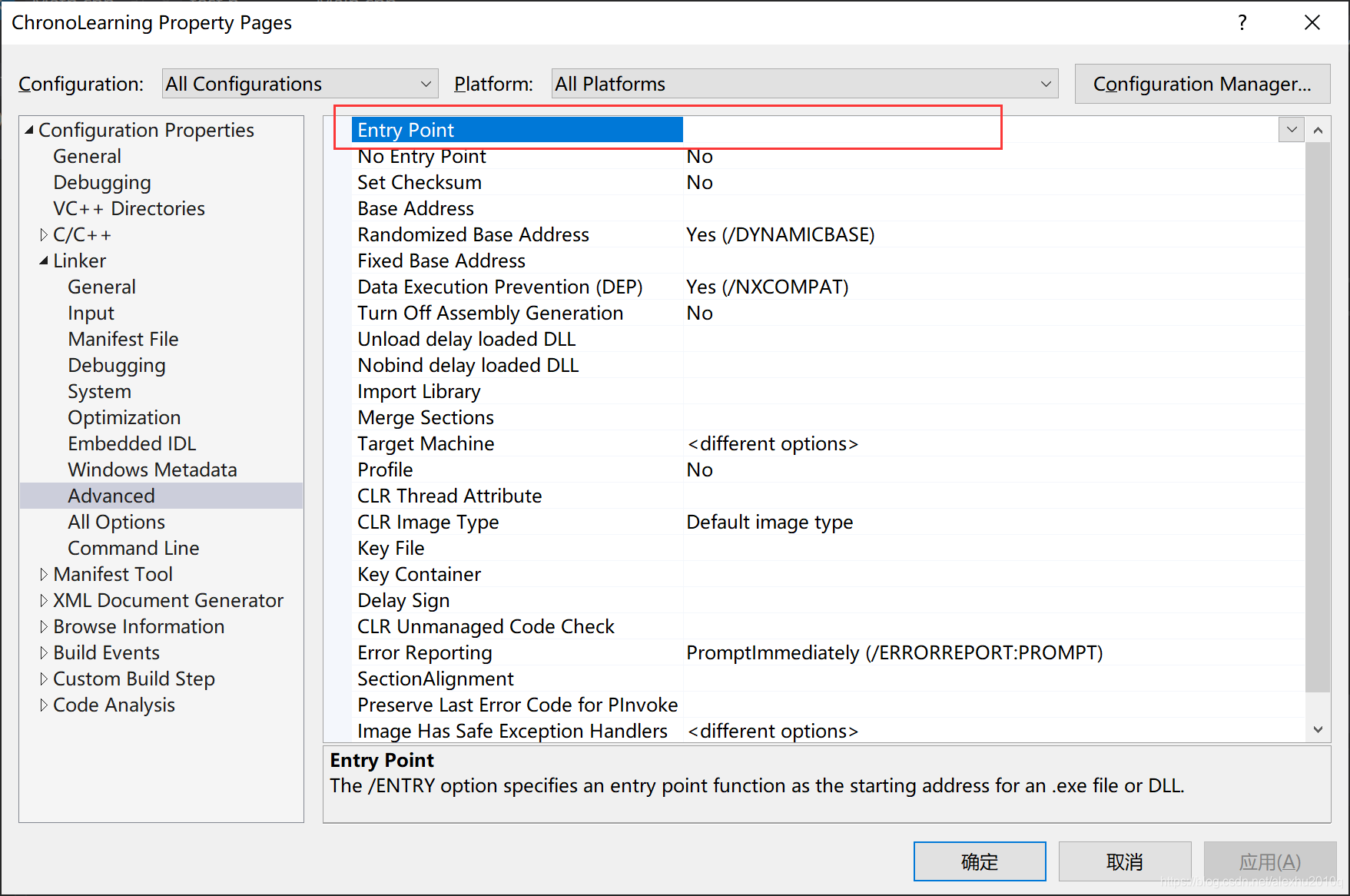
C++程序默认的入口是main函数,当然可以在Visual Studio中自行设定入口函数,如下图所示:
8. 关于函数重定义
当Linker把不同的.obj文件Link起来时,对于用到的函数,会去寻找其定义函数(Compiler只会查询有没有声明,不会管定义)。
举个函数重定义的例子:
在头文件里声明和定义了函数,然后两个或以上的cpp引用了该头文件。
原因:因为头文件的引用,对其预处理相当于使用的复制粘贴,所以两个cpp都会包含相应的定义。
解决办法有三种:
- 第一种:将头文件的该函数,设置为static函数,这样每个使用它的cpp,函数的定义范围就仅限于该cpp了。
- 第二种:将头文件的该函数,设置为inline函数,这样实际上变成了预处理类似的方式,不会再报错。
- 第三种:也是最常用的一种,就是.h文件里面不实现函数定义,只包含函数声明,这样就把原来两个Translation Unit 变成了一个,两个CPP均有函数声明,但是共享一个函数定义
9. 32位操作系统:
char 1个字节
short 2个字节
int、long、float 4个字节
double、long long、 long int: 8个字节
任何一个前面加上unsigned 都会移除符号位,使其在正数的范围更大
关于char
char看似是一个字符,实际上也只是一个简单的数字而已,C++中所有的数据类型本质上并没有区别,只是其所占的字节数不一样而已,不同的是,计算机在输出的时候,将其转换成了字符输出
举个简单的例子:
char a = 65;//'A' = 65
std::cout<< a << std::endl;
结果会输出

浮点数怎么存储的
float a = 5.5f//正确
double b = 6.3;//正确
float c =5.5//5.5是double类型,实际上这里有隐式转换
bool型变量
bool占一个字节,其实跟char的存储方式没什么区别,任何非0的bool值都是true,虽然bool值实际上只需要一位即可,但由于最小的存储单位为字节,所以bool也占一个字节。
这也意味着,如果为了节约内存,可以通过一个字节的空间(也就是一个bool类型或char类型),存储8个bool值变量。
10. Debug模式下正常的除了void类型的函数都需要返回值,否则编译不过(Main函数除外),但Release模式下编译不会报错,会正常运行(但是可能运行会报错,或产生undefined behaviour)
11. #include<header.h>和#include"header.h"的区别
#include<header.h>特指包含在include文件夹里的头文件,可以在项目属性中进行添加
#include"header.h"则与当前项目的路径有关,甚至你可以写#include"../header.h", 其实所有用<>的地方,都可以用""来代替,就算你写#include "iostream"其实也是可以的
12. C++与C语言在头文件上的格式的区别
由11可以看到,我们平时用的#include<iostream>而不是#include<iostream.h>,而C语言的库用的是#include<stdlib.h>
说明,这些常用的库文件,为了区分C头文件和C++头文件,将C的头文件都加.h后缀,而C++的头文件则没有任何后缀
13. C++Debug需要知道的知识:
常用调试快捷键
F9 添加/去除 断点
F10(step over) 单步调试
F11(step into) 进入该行所在的函数进行调试
Shift + F11(step out) 跳出该函数
注意:黄色箭头代表走到了这一行,但是这一行还没被执行

添加监视,并不只有右键选择变量并Add Watch的方式
如下图所示,在红色地点直接输入a,按回车,就能监视a变量
如何在Debug时观察整个程序的内存
在菜单栏Debug->Windows->Memory->Memory1,可以打开当前运行的项目的Memory显示窗口
在Memory窗口查询变量的地址
如下图所示,对于变量a,输入&a再按回车,就可以在第一行最前面显示其地址
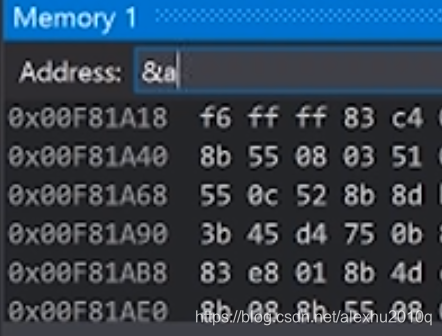
按回车后,&a会自动转为地址,如下图所示,值得注意的是,这地址里面,每一个数都是一个两位数,这里面的数都是16进制的(hexadecimal),每一个数代表了8位,所以代表一个字节的大小:(8个字节的cc,分别代表两个局部变量,第一个就是变量a)
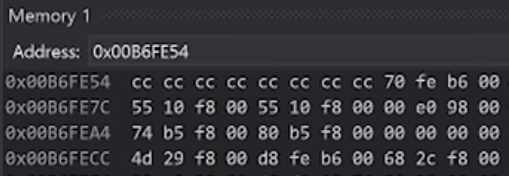
上述的cc是Debug模式下IDE特意设置的,cc告诉我们,这一块地区的值是未经初始化的,这样以后看到值为cc 的变量,我们直接就可以知道这个变量没有进行初始化,从而方便程序员进行Debug
当a的值进行初始化后,可以看到值产生了变化:
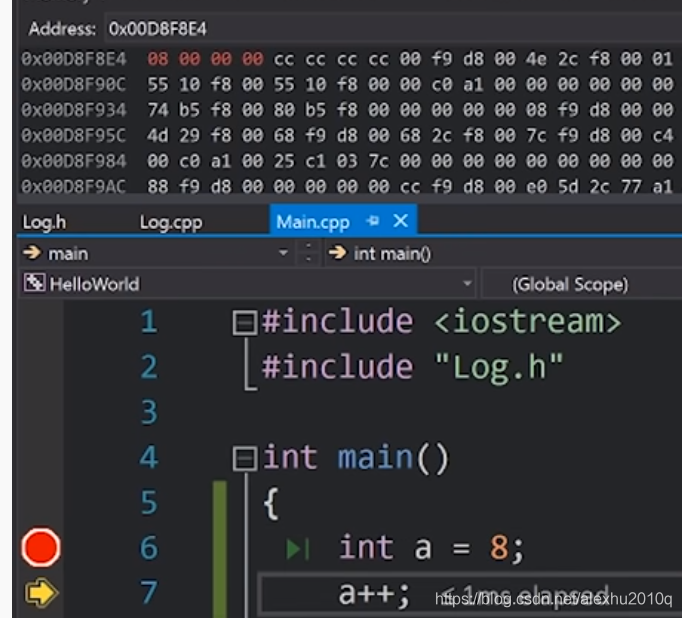
注意上图有个比较重要的地方,就是如何读取内存中对应的二进制的数,对于变量a,a的值为8,但我们在内存里看到的a对应的值的表示为:08 00 00 00,而不是我们想象的00 00 00 08,如果说它是逆序的,好像也不对,因为逆序的应该是80 00 00 00才对,那么正确的方法应该怎么读呢?
确实应该逆序读,但是这个逆序不能按位来逆序,而是应该按字节来逆序,因为字节是最小的存储单位,为什么要倒着读,这应该与变量a是在栈中存储有关,按照逆序的字节划分来读,依次为:00、00、00和08。
再举个例子,如下图所示,变量col类型为unsigned int,其真实值在监视列表中表示出来了,为1090502656
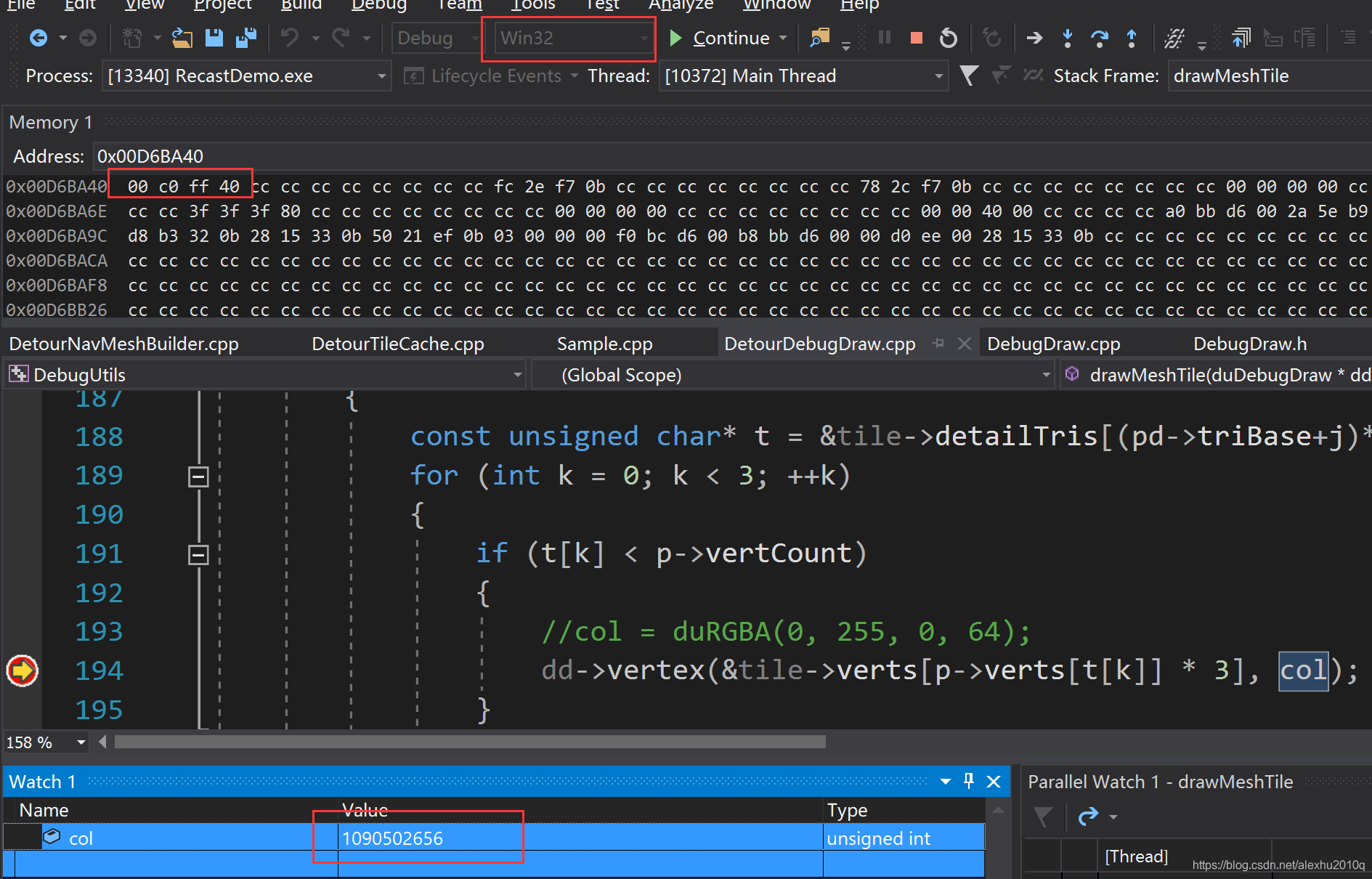
我们按照刚刚的计算的方法,按照40 ff c0 00的顺序,结果值为4 * 16 ^ 7 + 15 * 16 ^ 5 + 15 * 16 ^ 4 + 12 * 16 ^ 3 ,可以从计算器中得到验证,如下图所示:

14. 在断点后,查看程序运行的汇编语言
之前提到过,如果在项目属性,C++选项的输出文件中,可以选择输出.asm(Assembly)文件,但是还有一种方法,能在Debug断点时即时查看CPU运行的汇编指令。
如下图所示,在空白处点右键,选择Go to Assembly(也可以直接用快捷键)
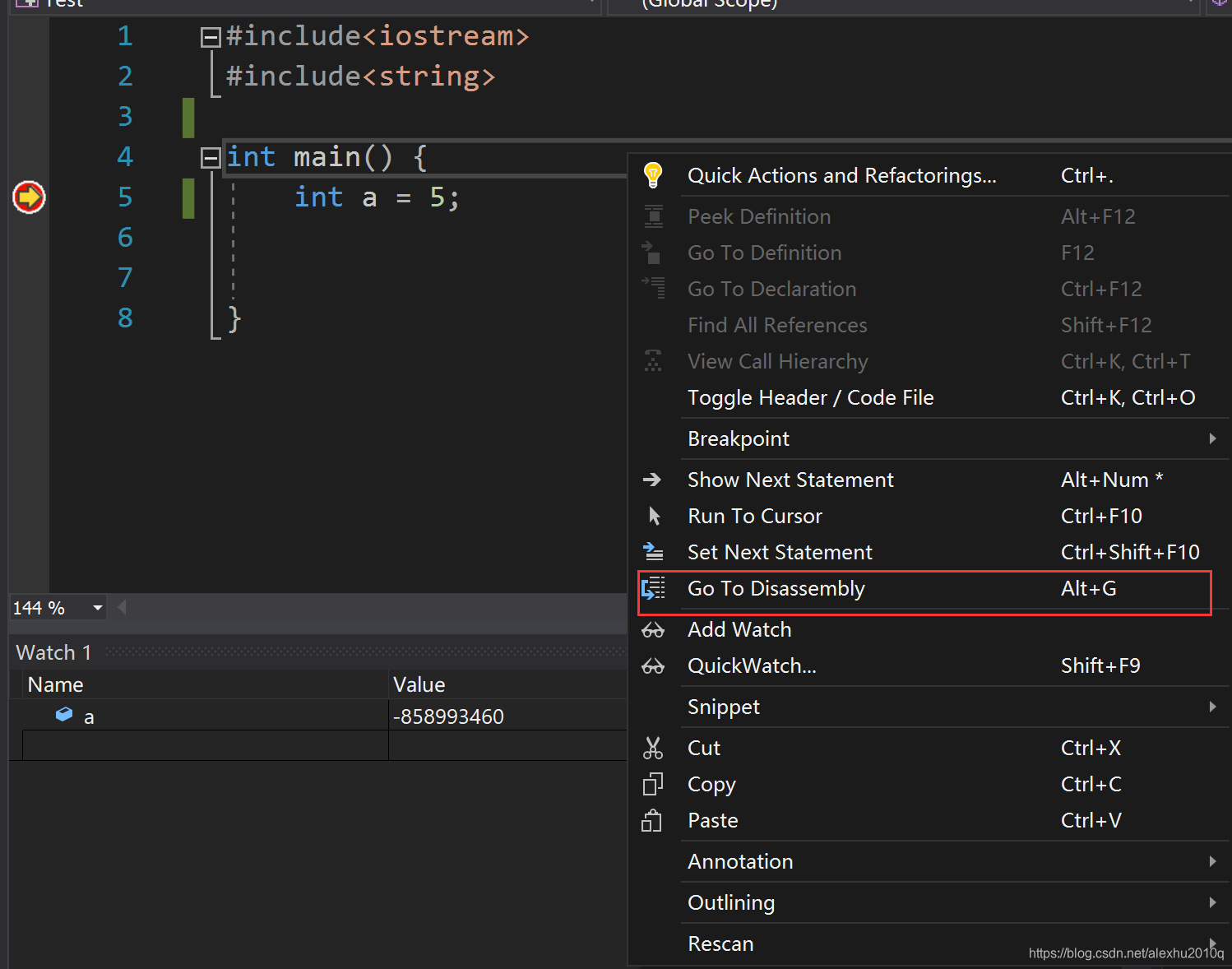
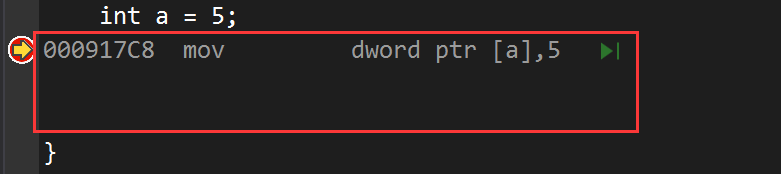
如下图所示,语句对应的汇编指令在该语句的下方:
15. 指针
//创建空指针的三种方式
void* p = 0;
void* p = NULL;
void* p = nullptr;
指针就是一个数字而已,这个数字记录的是某个点(并不是某个区域)的地址,所以说,其实指针并没有类型,只是指针指的东西有类型而已,再举个例子:
int a =8;
void *p = &a;
16. Class与Struct的区别
Struct是C++语言为了兼容C语言留下的关键词,实际上除了一个默认是private,一个默认是public以外,基本没任何区别:
//如果明确了成员的公私有类型,用哪个应该都行
struct Name
{
public:
int a;
private:
int b;
}
虽然实际上没啥区别,使用的时候最好还是有以下的规则:
- 单纯的数据结构可以用struct
struct Vec2
{
float x, y;
void Add(const Vec2& other)
{
x += other.x;
y += other.y;
}
}
- 需要被继承的类,就用class,用struct编译器可能会警告,但还是能运行
17. Visual Studio 生成的C++项目文件解析
如果在VS2017中生成一个空项目,那么对应的文件如下:
Project1文件夹里面存储内容如下:
其中**.filters**文件存储的是项目的filter,如下图所示的文件夹并不会在路径下存在真正的文件夹,而是通过filter形式存在,可以方便我们更好的调整项目的目录结构,可以通过项目右键ADD,添加filter。
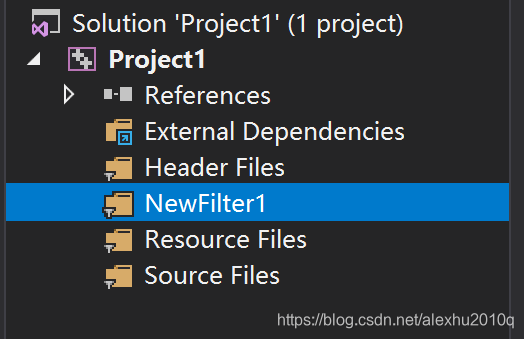
另外,由于这些Filter对应的文件都不存在,如果在这些Filter下创建各自的.h和.cpp文件,没有任何区别,它们都会被放在项目的文件夹里,如下所示:
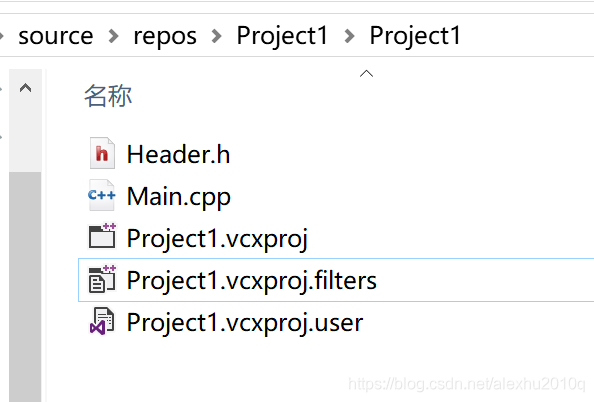
为了更好的摆放文件,可以勾选如下所示的图标,这样就能在VS里真实显示项目的文件路径:
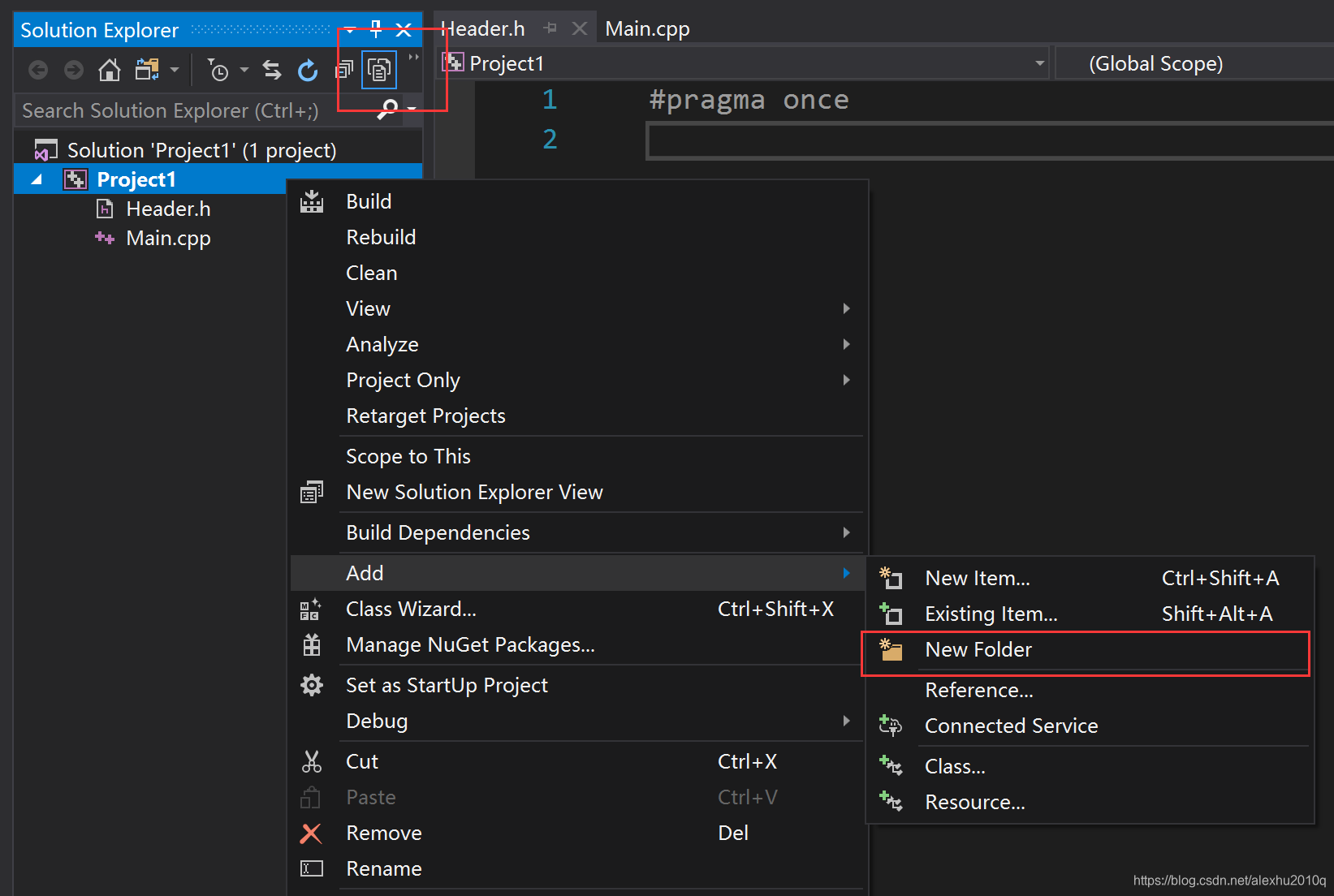
还可以创建真实的文件夹,而不是filter,如下图所示。
18 VS2017的intermediate路径和exe路径
VS2017在对应的Config(Debug或Release)模式下进行编译,都会产生两个文件夹,一个是intermediate文件夹,一个是最终结果(exe)存放的文件夹。
如下图所示,32位的Debug模式下,生成的是OutPut File,文件夹叫Debug
里面存放的是生成的exe等最终文件:
而还有一个文件夹,叫做intermediate文件夹,也叫做Debug,路径如下:
点进去可以看到存放的是一些中间文件,比如cpp编译生成的obj文件等

可以人为的在项目属性中设定OutPut路径和Intermediate路径,如下图所示
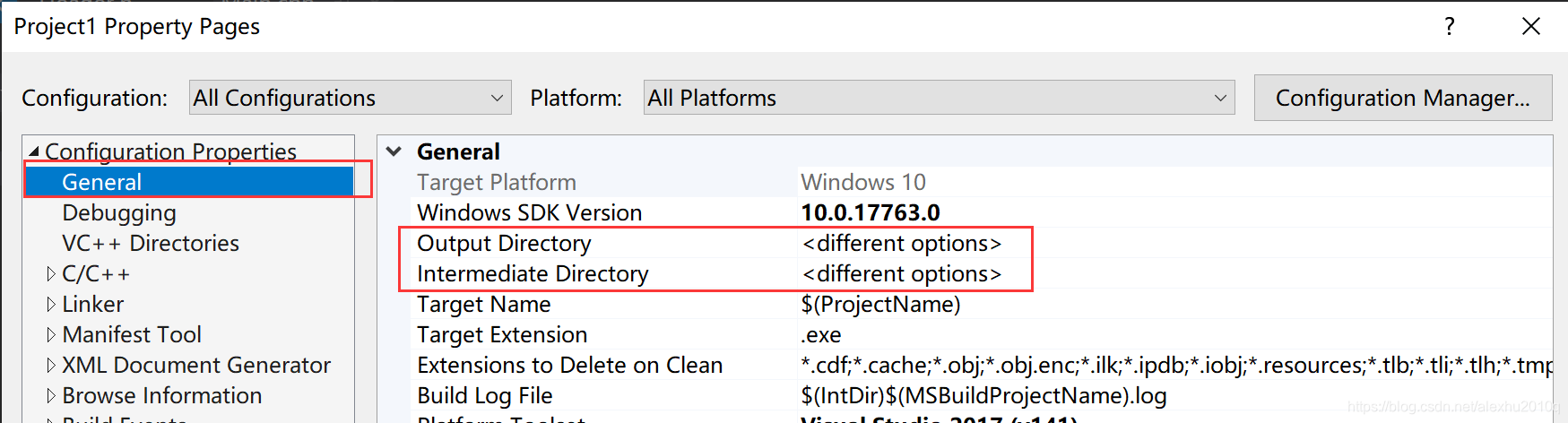
举个例子,可以这么写:
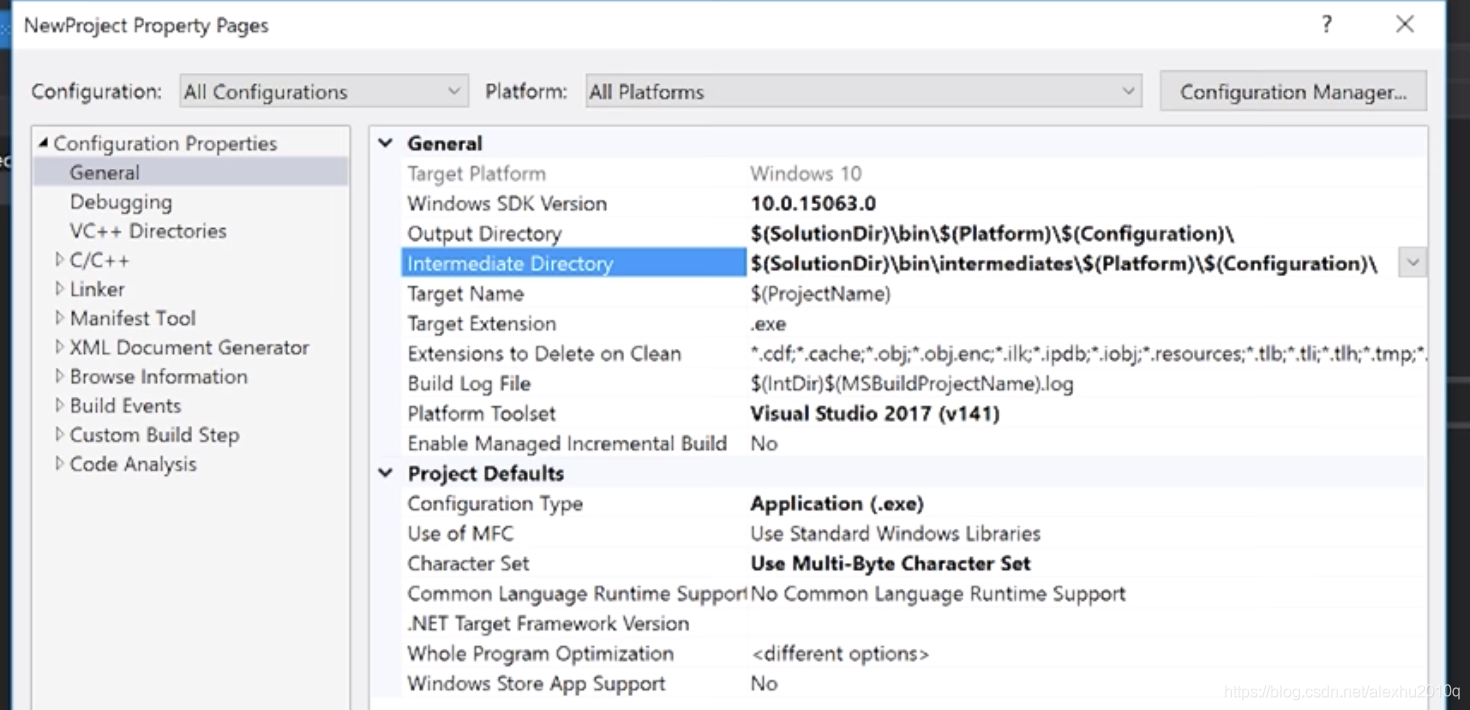
其中,$(SolutionDir),$(Platform)和$(Configuration)这些都是宏定义,分别代表了项目工程目录、编译平台和Debug或是Release的编译设置。
其实$(SolutionDir)后面带了Dir字样,意味着这是路径宏,所以结尾自带\号,所以其实这样写就行:
$(SolutionDir)bin\$.....
想知道具体更多的宏,可以直接点开下拉箭头–> Edi t–> Macros,就可以看到很多具体的宏定义,如下图所示:
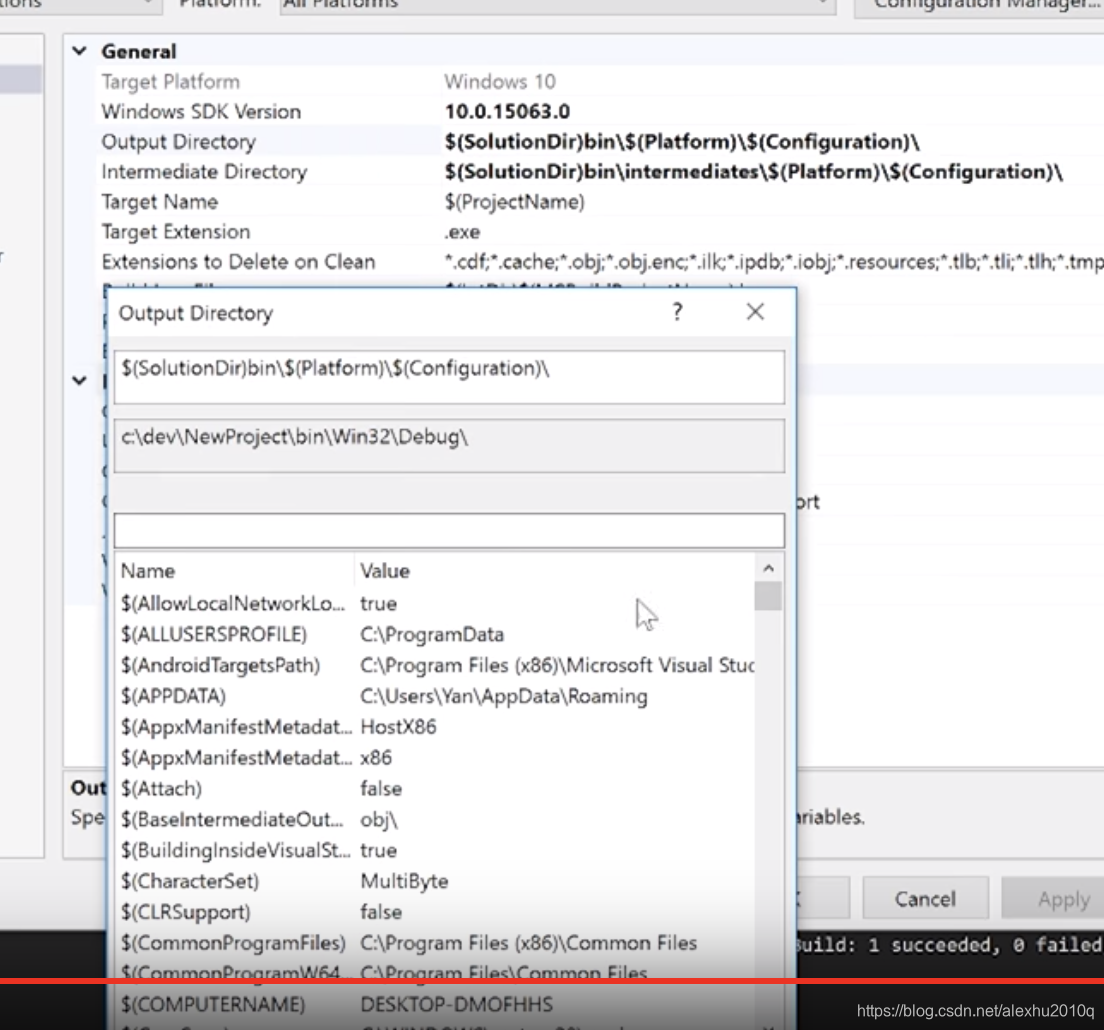














 234
234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









