






语义分割中的损失
Lov´asz-Softmaxloss
Submodularity and the Lovász extension
推荐阅读:https://sudeepraja.github.io/Submodular/
- submodularity
submodular实际上就对“边际效用递减”这个说法的形式化。
[ n ] = { 1 , 2 , . . , n } [n]=\left\{1,2,..,n \right\} [n]={1,2,..,n}, [ n ] [n] [n]所有的子集为 2 [ n ] 2^{[n]} 2[n], 定义一个 f : 2 [ n ] → R f: 2^{[n]}\rightarrow R f:2[n]→R, 如果它满足对于所有的集合 S S S, T ⊂ [ n ] T\subset \left[ n\right] T⊂[n], 则对于所有的元素 T ⊂ [ n ] T\subset \left[ n\right] T⊂[n],都有
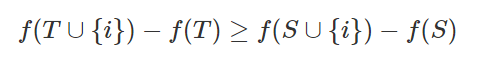
也等价于定义一个 f : 2 [ n ] → R f: 2^{[n]}\rightarrow R f:2[n]→R, 如果它满足对于所有的集合 S S S, T ⊂ [ n ] T\subset \left[ n\right] T⊂[n]
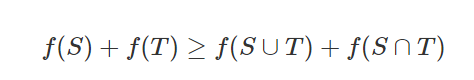
- Lovász extension
Lovász extension是一种非常有用的构造,可用于submodularity最小化。 次模函数的Lovász extension始终是凸的,可以有效地使其最小化。 Lovász extension的最小值可用于查找子模函数的最小值。
给一个次模函数 f : H n → R f: H_{n}\rightarrow R f:Hn→R, 它的 Lovász extension是 f ^ : K n → R \widehat {f}:K_{n}\rightarrow \mathbb{R} f :Kn→R定义为
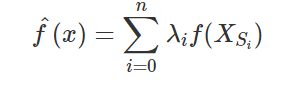
S i : ϕ = S 0 ⊂ S 1 ⊂ S 2 . . . ⊂ S n = [ n ] S_i: \phi = S_0\subset S_1\subset S_2...\subset S_n = [n] Si:ϕ=S0⊂S1⊂S2...⊂Sn=[n] 是这样的一个链, 其中 ∑ i = 0 n λ i X i = x \sum ^{n}_{i=0}\lambda _{i}X_i=x ∑i=0nλiXi=x, ∑ i = 0 n λ i = 1 \sum^{n}_{i=0}\lambda_{i}=1 ∑i=0nλi=1。
这样的定义并没有告诉我们怎么确定这一个链。也没有告诉我们怎么求 λ i \lambda_i λi。
在 H n H_n Hn这样一个超立方体中,有 n ! n! n!个不同的最短路径,从 0 n → 1 n 0_n\rightarrow 1_n 0n→1n, 0 n 0_n 0n代表全为0的向量 , 1 n 1_n 1n为全为1的向量。令 P = [ 0 n = X 0 , X 1 , X 2 , . . . , X n = 1 n ] P=[0_n=X_0,X_1,X_2,...,X_n=1_n] P=[0n=X0,X1,X2,...,Xn=1n]代表一个路径, C p C_p Cp是 P P P中凸包部分的点。对于每一条路径中都存在 n ! n! n!个这个的凸包。这些凸包划分 K n K_n Kn为 n ! n! n!个等价的部分。


- Lov´asz-Softmaxloss
jaccard loss可以写成这样的形式:

因为Jaccard loss 只适用于离散空间,即输入都为0或者是1的情况,对于连续空间中会造成无法求导的问题,所以说对Jaccard loss进行了lovasz extension,将离散空间拓展到整个R,之前的定义也讲了对于输入 x x x,必须满足 ∑ i = 0 n λ i X i = x \sum ^{n}_{i=0}\lambda _{i}X_i=x ∑i=0nλiXi=x,这就类似于用原本的 X i X_i Xi作为基向量,用这一系列离散的向量去表示 x x x,这个 x x x有点类似于经过插值之后的结果。这样就把定义域空间从离散拓展到了 R R R中,我们也就可以进行梯度的计算了。

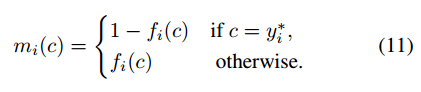
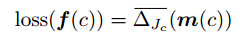

以上是论文中的整个从Jaccard loss进行lovasz extension,再进行求导的整个流程。
下面结合代码整体解释一下怎么计算的:


- 计算出所有像素点的error值,并进行降序排序。
- 调整gt的顺序使得最大error的像素值在前,最小的在后,计算相应位置像素值的梯度。
- 在第二幅图中计算梯度。计算之后的jaccard值之和为1,也对应着上面的 ∑ λ i = 1 \sum \lambda_{i}=1 ∑λi=1。对应位置的梯度(贡献度)就算出来了,这个时候进行梯度计算的时候也能进行求导下去了。
对应着次模函数,我们每次加入error值最高的像素值进去,用贪心算法的方式达到最后的目的地,也就是排序过后gt的状态(离散的形式0和1组成的向量),因为是经过排序的,前面的gt值比后面的值errors的系数大,用jaccard loss计算加入一个gt值之后的“贡献”,所以说这里才会有减去前n个"贡献"和的操作。而这里的“贡献”也就对应着梯度。这个地方的梯度计算至于排序的序列有关,与具体的值无关。具体的数学推导还是有点难懂,我也想得不是太明白。若说错了,请指正!















 6383
6383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









