







版权声明:本文为博主原创文章,未经博主允许不得转载
论文:YOLO9000:Better, Faster, Stronger
链接:https://arxiv.org/abs/1612.08242
2017CVPR的文章
论文详解:
这里分3个部分讲,Better, Faster, Stronger
Better:

作者先是谈到YOLO的两个缺点:
1.定位不准确
2.与基于region proposal的检测器相比,召回率低。。

作者接着谈到YOLO并不是通过加深或加宽网络来提高性能,反而简化了网络,作者从过去的工作中有了各种各样的想法,结合新颖理念来提高YOLO的表现。

1.Batch Normalization

每一层网络的输入都会因前一层网络参数的变化导致其分布发生改变,这要求我们必须使用一个很小的学习率和对参数很好的初始化,这回让训练过程变得慢而且复杂。简单来讲,BN对网络的每一层的输入做了归一化,数据分布是稳定的,收敛会快点。另外BN也可也规范模型,去掉了dropout.
2.High Resolution Classifier

作者提到detection的时候,分辨率从224*224提高到448*448,会导致模型学习目标检测的同时适应图像输入的分辨率。YOLOv2将预训练分成两步:先用224*224的输入从头开始训练网络,大概160个epoch(one epoch 所有数据跑了一次),然后输入调整到448*448,训练10个epoch,最后在检测的数据集上fine-tuning。
3.Convolutional With Anchor Boxes
YOLO predicts the coordinates of bounding boxes directly using fully connected layers on top of the convolutional feature extractor.Instead of predicting coordinates directly Faster R-CNN predicts bounding boxes using hand-picked priors.
原来的YOLO全连接层直接预测bounding box的坐标,而Faster RCNN引入anchor,YOLO V2借鉴了这个方法。

作者先将网络的全连接层和一个pooling层去掉(有更高的分辨率输出),接着缩减了网络,416*416代替了原来的448*448,原因嘛,我标注的那段说的挺明白的,作者期望特征图有着奇数的宽和高,因为这样只有一个center ceil,那为什么希望一个center ceil呢?因为大的object往往中心落在图像的中心位置,我们期望用一个位置去预测,而不是4个。
4.Dimension Clusters
作者在这里谈到了引入anchor box时遇到的第一个问题:以往的box dimensions的大小和比例是根据人工经验选择的,作者说到一开始就用好的anchor box会使得网络更好学习地去预测。作者采用了k-means聚类,接着又发现标准的k-means(欧几里得距离)会带来box尺寸大的比小的误差要大,而我们希望跟尺寸大小无关,所以文中定义了新的距离度量:
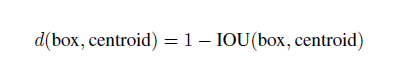
We choose k = 5 as a good tradeoff between model complexity and high recall.
作者选择了k=5来平衡模型复杂度度与recall值。
5.Direct Location prediction

作者在引入anchor box 的时候遇到的第二个问题:模型不稳定,尤其在早期训练时。作者认为这种不稳定来之x,y的预测。
,

作者继续沿用了YOLO算法预测相对于grid ceil的方式,


每个cell预测5个bounding box ,每个bounding box预测5个值:tx,ty,tw,th和to,tx和ty经过sigmoid范围落在0-1,cx和cy表示ceil的左上角与图像的原点的距离。pw,ph表示bounding box prior的宽和高。作者谈到对位置预测的约束,使得参数更容易学习,网络更加稳定,使用dimension clusters和direct Location prediction提高了5%的map。
6.Fine-Grained Features



作者谈到13*13的feature map 对于预测大的目标足够了,对于小的目标效果不好。Faster RCNN 和SSD网络利用了不同的feature maps来得到细粒度特性,提高对小目标的预测。作者这里加了passthrough layer,这个层就是把前面一层26*26的feature map与13*13的feature map相连接,有点像ResNet。
7.Multi-Scale Training

为了让YOLO V2更加robust,希望能够在不同大小的图片上运行,所以作者采用了Multi-Scale Training,输入图像的size是变化的,{320,352,....608}。网络在小size的时候训练较快,大size的时候训练较慢,因此速度与准确率取得了较好的平衡。检测结果如下图所示:

Faster:

作者简单比较了VGG-16和YOLO的GoogleNet,接着提出了新的分类网络,Darknet-19。

1.Training for classification.

2.Training for Detection

Stroner:
YOLO9000部分看的云里来雾里去的,简单地贴些原文,具体以后有机会看了代码再来说:

Joint classification and detection:简单讲就是融合分类和检测数据集,分类数据集学习预测坐标和一般的分类,检测数据集学习更多种类的分类。那么怎么训练呢,对于分类的数据集,backpropagate时,根据所有的loss,对于检测的数据集,根据特定的分类loss。
We traverse the tree down, taking the highest confidence path at every split until we reach some threshold and we predict that object class.
我们沿着树向下遍历,在每次分割时选择最高的置信度路径,直到达到某个阈值并预测对象类。
For example,if the network sees a picture of a dog but is uncertain what type of dog it is, it will still predict “dog” with high
confidence.
例如,如果网络看到一张狗的照片,但不确定是什么类型的狗,它仍然会预测“狗”的高度的信心。















 1152
1152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









