







2.1 标量、向量、矩阵和张量
- 标量:一个标量就是一个数,一般用斜体表示标量,标量通常被赋予小写的变量名称。介绍标量的时候,通常会明确表示标量的类型。比如“令 s ∈ R s\in\mathbb R s∈R表示一条线的斜率。
- 向量:一个向量是有序排列的一列数,通过次序中的索引可以确定每个单独的数。通常向量的名称是粗体小写表示,比如
x
\bold{x}
x .可以把向量看作一个n维空间上的点,每个元素是不同坐标轴上的坐标。
x = [ x 1 x 2 x 3 . . . x n ] x − 1 = { x ∣ x ∈ x , x ≠ x 1 } S = 1 , 3 , 6 x − S = { x ∣ x ∈ x , x ∉ x S } x − S 表 示 除 了 x 1 , x 3 , x 6 外 所 有 元 素 组 成 的 向 量 。 x = \begin{bmatrix} x_1 \\ x_2 \\x_3\\...\\x_n\end{bmatrix} \\x_{-1} =\{x|x\in \bold{x},x \neq x_1\} \\ S = {1,3,6} \\x_{-S} = \{x|x\in \bold{x},x \notin x_S\} \\x_{-S}表示除了x_1,x_3,x_6外所有元素组成的向量。 x=⎣⎢⎢⎢⎢⎡x1x2x3...xn⎦⎥⎥⎥⎥⎤x−1={x∣x∈x,x=x1}S=1,3,6x−S={x∣x∈x,x∈/xS}x−S表示除了x1,x3,x6外所有元素组成的向量。 - 矩阵:一个二维数组,每个元素被两个索引所确定。通常会赋予矩阵粗体的大写变量名称,比如 A \bold{A} A.如果一个实数矩阵高度为m,宽度为n,那么说 A ∈ R m ∗ n \bold{A} \in \mathbb R^{m*n} A∈Rm∗n.
- 张量(tensor):坐标超过两维的数组。张量A中坐标为(i,j,k)的元素记为 A i , j , k A_{i,j,k} Ai,j,k.
- 转置:矩阵的重要操作。 ( A T ) i , j = A j , i (A^T)_{i,j} = A _{j,i} (AT)i,j=Aj,i.向量的转置可以看作是只有一行的矩阵,标量的转置等于它本身。
- 矩阵相加:两个矩阵的对应位置的元素相加。
- 标量和矩阵相乘或相加:将标量与矩阵的每个元素相乘或相加。
- 矩阵和向量相加:向量b和矩阵A的每一行相加。
2.2 矩阵和向量相乘
- 矩阵乘法:C = AB。 矩阵A的列数必须等于B的行数。
- 矩阵对应乘法: A ⨀ B A\bigodot B A⨀B称为元素对应乘积。
- 点积:两个维度相同的向量 x x x和 y y y的点积可以看作是矩阵乘积 x T y x^Ty xTy
- 矩阵乘积运算服从分配律和结合律,但并不满足交换律。
- 矩阵乘积的转置: ( A B ) T = B T A T (AB)^T = B^TA^T (AB)T=BTAT
2.3 单位矩阵和逆矩阵
- 单位矩阵:所有对角线的元素都是1,其余元素都是0。任意矩阵和单位矩阵相乘,都不会改变。(任何数和单位1相乘都是本身)。n维单位矩阵记为 I n \bold{I}_n In.形式上: I n ∈ R n ∗ n \bold{I}_n \in {\mathbb R}^{n*n} In∈Rn∗n
- 矩阵A的逆记为 A − 1 A^{-1} A−1,满足 A − 1 A = I n A^{-1}A = I_n A−1A=In
2.4 线性相关和生成子空间
- A x = b ( b ≠ 0 ) = > x = A − 1 b Ax = b(b\neq 0) => x = A^{-1}b Ax=b(b=0)=>x=A−1b
- 对于非齐次线性方程组 A x = b ( b ≠ 0 ) Ax = b(b\neq 0) Ax=b(b=0)的解,只有三种情况:无解、唯一解或者有无穷解。
- 一个列向量线性相关的方阵被称为奇异的。
- 一组向量的线性组合是指每个向量乘以对应标量系数之后的和。一组向量的生成子空间是原始向量线性组合后所能抵达的点的集合。
- 确定 A x = b ( b ≠ 0 ) Ax = b(b\neq 0) Ax=b(b=0)是否有解相当于确定向量b是否在A列向量的生成子空间中。
- 讲的好麻烦 感觉没有汤家凤讲的明白 但是我都忘没了
2.5 范数
-
范数用来衡量向量的大小。形式上,范数的定义如下:
∣ ∣ x ∣ ∣ p = ( Σ i ∣ x i ∣ p ) 1 p , 其 中 p ∈ R , p > = 1 ||x||_p =(\Sigma_i|x_i|^p)^{\frac{1}{p}},其中p\in\mathbb R,p>=1 ∣∣x∣∣p=(Σi∣xi∣p)p1,其中p∈R,p>=1 -
范数(包括 L p L^p Lp范数)是将向量映射到非负值的函数。直观上来说,向量x的范数衡量从原点到点x的距离。范数是满足以下性质的函数:
1. f ( x ) = 0 = > x = 0 2. f ( x + y ) < = f ( x ) + f ( y ) ( 三 角 不 等 式 ) 3. ∀ α ∈ R , f ( α x ) = ∣ α ∣ f ( x ) 1.f(x) = 0=>x = 0 \\2.f(x+y)<= f(x)+f(y) (三角不等式)\\ 3.\forall\alpha\in\mathbb R,f(\alpha x) =|\alpha|f(x) 1.f(x)=0=>x=02.f(x+y)<=f(x)+f(y)(三角不等式)3.∀α∈R,f(αx)=∣α∣f(x) -
当p=2的时候,L2称为欧几里得范数,经常简化为||x||。
-
平方L2范数也经常用于衡量向量的大小,通过点积 x T x x^Tx xTx计算。
-
L1范数: ∣ ∣ x ∣ ∣ 1 = Σ i ∣ x i ∣ ||x||_1 = \Sigma_i|x_i| ∣∣x∣∣1=Σi∣xi∣.当机器学习问题中0和非0元素之间的差异非常重要时,通常使用L1范数。
-
L ∞ L^{\infty} L∞范数:也称为最大范数。表示向量中具有最大幅值的元素的绝对值: ∣ ∣ x ∣ ∣ ∞ = max i ∣ x i ∣ ||x||_{\infty} = \displaystyle \max _{i}|x_i| ∣∣x∣∣∞=imax∣xi∣.(就是找到绝对值最大的数呗)
-
想要衡量矩阵的大小,使用Frobenius 范数。 ∣ ∣ A ∣ ∣ F = ∑ i , j A i , j 2 ||A||_F = \sqrt{\displaystyle \sum_{i,j}A_{i,j}^2} ∣∣A∣∣F=i,j∑Ai,j2
2.6 特殊类型的矩阵和向量
- 对角矩阵:只在对角线上含有非零元素,其他位置都是零的矩阵。记为diag(v),表示一个对角元素由向量v中元素给定的对角矩阵。
- 计算乘法 d i a g ( v ) x diag(v)x diag(v)x相当于把x中的每个元素 x i x_i xi放大 v i v_i vi倍。
- 对角矩阵的逆矩阵: d i a g ( v ) − 1 = d i a g ( [ 1 / v 1 ; . . . . . . ; 1 / v n ] ⊤ ) diag(v)^{−1} = diag([1/v1; ...... ; 1/vn]⊤) diag(v)−1=diag([1/v1;......;1/vn]⊤)
- 对称矩阵: A = A T A = A^T A=AT
- 单位向量:具有单位范数的向量。 ∣ ∣ x ∣ ∣ 2 = 1 ||x||_2 = 1 ∣∣x∣∣2=1
- 如果 x T y = 0 x^Ty = 0 xTy=0,那么x和y正交。在 R \mathbb R R中,至多有n个范数非零的向量互相正交。如果这些向量不仅互相正交,范数都为1,那么称为标准正交。
- 正交矩阵: A T A = A A T = I 也 就 意 味 着 A − 1 = A T A^TA = AA^T = I\quad 也就意味着\\A^{-1} = A^T ATA=AAT=I也就意味着A−1=AT.正交矩阵使得求逆计算代价小。正交矩阵的行向量不仅是正交的,还是标准正交的。
2.7 特征分解
-
许多数学对象可以通过分解成多个部分或者找到一些属性而更好理解,这些属性是通用的,而不是人为选择的。我们可以通过分解矩阵来发现矩阵表示成数组元素时不明显的函数特质。
-
特征分解时矩阵分解的一种方法,即将矩阵分解成一组特征值和特征向量。
-
方阵A的特征向量是指与A相乘后相当于对该向量进行缩放的非零向量v。即 A v = λ v . λ Av = \lambda v.\lambda Av=λv.λ被称为这个特征向量对应的特征值。
-
如果v是A的特征向量,那么任何缩放后的向量 s v ( s ∈ R , s ≠ 0 ) s\bold{v}(s\in\mathbb R,s\neq 0) sv(s∈R,s=0)也是A的特征向量,而且 s v 和 v sv和v sv和v有相同的特征值。
-
假设矩阵A有n个线性无关的特征向量{ v ( 1 ) , . . . , v ( n ) \bold{v^{(1)},...,v^{(n)}} v(1),...,v(n)},对应着特征值{ λ 1 , . . . λ n \lambda_1,...\lambda_n λ1,...λn}.将特征向量连成一个矩阵,每一列是一个特征向量: V = [ v ( 1 ) , . . . , v ( n ) ] V = [v^(1),...,v^(n)] V=[v(1),...,v(n)].类似的,将特征值连接成一个向量 λ = [ λ 1 , . . . , λ n ] T \bold{\lambda} = [\lambda_1,...,\lambda_n]^T λ=[λ1,...,λn]T.因此A的特征分解可以记为:
A = V d i a g ( λ ) V − 1 A = Vdiag(\lambda)V^{-1} A=Vdiag(λ)V−1 -
但是不是每一个矩阵都可以分解为特征值和特征向量。某些情况下特征分解存在但会涉及复数。
-
每个实对称矩阵都可以分解为实特征向量和实特征值:
A = Q Λ Q T A = Q\Lambda Q^T A=QΛQT
其中 Q Q Q是A的特征向量组成的正交矩阵, Λ \Lambda Λ是对角矩阵。特征值 Λ i , i \Lambda_{i,i} Λi,i对应的特征向量是矩阵Q的第i列。
虽然任意一个实对称矩阵A都有特征分解,但是特征分解可能不唯一。特征分解唯一当且仅当所有的特征值都是唯一的。 -
矩阵是奇异的当且仅当有零特征值。
-
实对称矩阵的特征分解也可以用于优化二次方程 f ( x ) = x T A x f(x) = x^TAx f(x)=xTAx,其中限制 ∣ ∣ x ∣ ∣ 2 = 1 ||x||_2 = 1 ∣∣x∣∣2=1.当x等于A的某个特征向量时,f将返回对应的特征值。
-
所有的特征值都是正数的矩阵为正定矩阵,所有的特征值都是非负数的矩阵都是半正定,所有特征值都是负数称为负定,所有特征值都是非正数的矩阵称为半负定。
-
半正定矩阵保证 ∀ x , x T A x ≥ 0 \forall x,x^TAx\geq 0 ∀x,xTAx≥0.(因为 f ( x ) = x T A x , f ( x ) f(x) = x^TAx,f(x) f(x)=xTAx,f(x)是对应的特征值。)
-
正定矩阵保证 x T A x = 0 ⇒ x = 0 x^TAx = 0\Rightarrow x = 0 xTAx=0⇒x=0 因为 f ( x ) = x T A x , f ( x ) f(x) = x^TAx,f(x) f(x)=xTAx,f(x)是对应的特征值,而且正定矩阵的特征值全部大于0.)
2.8 奇异值分解
- 另一种分解矩阵的方法:奇异值分解,将矩阵分解为奇异值和奇异向量。
- 每个实数矩阵都有一个奇异值分解,但不一定有特征分解。比如非方阵的矩阵没有特征分解,这时只能使用奇异值分解。
- 奇异值分解将矩阵A分解为三个矩阵的乘积:
A = U D V T i f A 是 一 个 m ∗ n 的 矩 阵 , 那 么 U 是 一 个 m ∗ m 的 矩 阵 , D 是 一 个 m ∗ n 的 矩 阵 , V 是 一 个 n ∗ n 矩 阵 。 A = UDV^T\\if A是一个m*n的矩阵,那么U是一个m*m的矩阵,\\D是一个m*n的矩阵,V是一个n*n矩阵。 A=UDVTifA是一个m∗n的矩阵,那么U是一个m∗m的矩阵,D是一个m∗n的矩阵,V是一个n∗n矩阵。
这些矩阵中的每一个经定义后都拥有特殊的结构。矩阵U和V都定义为正交矩阵,而矩阵D定义为对角矩阵(D不一定为方阵)。
- 对角矩阵D对角线上的元素被称为矩阵A的奇异值。矩阵U的列向量被称为左奇异向量,矩阵V的列向量被称为右奇异向量。
- 可以用与A相关的特征分解去解释A的奇异值分解。A的左奇异向量是 A A T AA^T AAT的特征向量,A的右奇异向量是 A T A A^TA ATA的特征向量。A的非零奇异值是 A T A A^TA ATA特征值的平方根,同时也是 A A T AA^T AAT特征值的平方根。
2.9 Moore-Penrose伪逆
- 非方矩阵的逆矩阵没有定义。对于 A x = y Ax = y Ax=y,对于A的左逆记为B,则 x = B y x = By x=By.如果A的行数大于列数,那么可能没解,如果行数小于列数,那么这个矩阵可能有多个解。
- 矩阵A的伪逆定义为: A + = lim α → 0 ( A T A + α I ) − 1 A T . A^+ = \displaystyle \lim_{\alpha \rightarrow 0}(A^TA+\alpha I)^{-1}A^T. A+=α→0lim(ATA+αI)−1AT.
- 计算伪逆的实际算法没有基于这个定义,而是使用公式: A + = V D + U T A^+ = VD^+U^T A+=VD+UT(奇异值分解后得到的几个矩阵,D的伪逆 D + D^+ D+是其非零元素取倒数之后再转置之后得到的)。
- 当矩阵A的列数多于行数时,使用伪逆求解线性方程是一种解法。而且, x = A + y x=A^+y x=A+y是方程所有可行解中欧几里得范数 ∣ ∣ x ∣ ∣ 2 ||x||_2 ∣∣x∣∣2最小的一个。
- 当矩阵A的行数多于列数时,可能没有解。在这种情况下,通过伪逆得到的x使得 A x 和 y Ax和y Ax和y的欧几里得距离 ∣ ∣ A x − y ∣ ∣ 2 ||Ax-y||_2 ∣∣Ax−y∣∣2最小。
2.10 迹运算
- 迹运算返回的是矩阵对角元素的和: T r ( A ) = ∑ i A i , i Tr(A) = \displaystyle \sum_iA_{i,i} Tr(A)=i∑Ai,i
- 迹运算提供了另一种描述矩阵Frobenius范数的方式: ∣ ∣ A ∣ ∣ F = T r ( A A T ) ||A||_F = \sqrt{Tr(AA^T)} ∣∣A∣∣F=Tr(AAT)
- 迹运算在转置运算下是不变的: T r ( A ) = T r ( A T ) Tr(A) = Tr(A^T) Tr(A)=Tr(AT)
- 多个矩阵相乘得到的方阵的迹,和将这些矩阵的最后一个挪到最前面之后相乘的迹是相同的(当然必须使乘法成立)。
T r ( A B C ) = T r ( C A B ) = T r ( B C A ) Tr(ABC) = Tr(CAB)=Tr(BCA) Tr(ABC)=Tr(CAB)=Tr(BCA) - 标量在迹运算后仍然是本身: a = T r ( a ) a = Tr(a) a=Tr(a)
2.11 行列式
- 记作det(A),是一个将方阵A映射到实数的函数。
- 行列式等于矩阵特征值的乘积。
2.12 主成分分析
- PCA(主成分分析)是一个机器学习算法。
- 可以看作是一个降维的算法,进行有损的压缩。
- 在 R n \mathbb R^n Rn空间中有m个点 { x ( 1 ) , . . . , x ( n ) } , \{x^{(1)},...,x^{(n)}\}, {x(1),...,x(n)},对于每个点 x ( i ) ∈ R x^{(i)}\in\mathbb R x(i)∈R,会有一个对应的编码向量 c ( i ) ∈ R l c^{(i)}\in\mathbb R^l c(i)∈Rl.如果 l < n l<n l<n,就实现用更少的内存存储原数据。我们希望找到一个编码函数,根据输入返回编码, f ( x ) = c f(x)=c f(x)=c;也希望找到一个解码函数,给定编码重构输入, x ≈ g ( f ( x ) ) x\approx g(f(x)) x≈g(f(x))。
- 为了简化解码器,使用矩阵乘法将编码映射回 R n \mathbb R^n Rn,即 g ( c ) = D c , D ∈ R n ∗ l g(c) = Dc,D\in\mathbb R^{n*l} g(c)=Dc,D∈Rn∗l是定义解码的矩阵。
- 计算这个解码器的最优编码可能是困难的,为了使编码问题简单一点,PCA限制D的列向量彼此正交。
- 为了实现这个算法,首先需要明确如何根据一个输入
x
x
x得到一个最优编码
c
∗
。
c^*。
c∗。一种方法是最小化原始输入向量
x
x
x和重构向量
g
(
c
∗
)
g(c^*)
g(c∗)之间的距离。即(此处用平方范数替代范数):
c ∗ = arg min c ∣ ∣ x − g ( c ) ∣ ∣ 2 2 ⇒ x T x − x T g ( c ) − g ( c ) T x + g ( c ) T g ( c ) = x T x − 2 x T g ( c ) + g ( c ) T g ( c ) , ( ( g ( c ) T x ) T = ( ( g ( c ) T x ) c^* = \displaystyle \argmin_c||x-g(c)||_2^2\\ \Rightarrow x^Tx-x^Tg(c)-g(c)^Tx+g(c)^Tg(c)\\=x^Tx-2x^Tg(c)+g(c)^Tg(c),((g(c)^Tx)^T = ((g(c)^Tx) c∗=cargmin∣∣x−g(c)∣∣22⇒xTx−xTg(c)−g(c)Tx+g(c)Tg(c)=xTx−2xTg(c)+g(c)Tg(c),((g(c)Tx)T=((g(c)Tx)
因为 x T x x^Tx xTx不依赖于c,所以优化目标:
c ∗ = arg min c − 2 x T g ( c ) + g ( c ) T g ( c ) c^* = \displaystyle \argmin_c -2x^Tg(c)+g(c)^Tg(c) c∗=cargmin−2xTg(c)+g(c)Tg(c)
代入 g ( c ) g(c) g(c)的定义:
c ∗ = arg min c − 2 x T D c + c T D T D c = arg min c − 2 x T D c + c T I l c = arg min c − 2 x T D c + c T c c^* = \displaystyle \argmin_c-2x^TDc+c^TD^TDc \\=\displaystyle \argmin_c-2x^TDc+c^TI_lc\\ =\displaystyle \argmin_c-2x^TDc+c^Tc c∗=cargmin−2xTDc+cTDTDc=cargmin−2xTDc+cTIlc=cargmin−2xTDc+cTc
求导:(对c求导, c T c 可 以 看 作 是 c 2 c^Tc可以看作是c^2 cTc可以看作是c2)
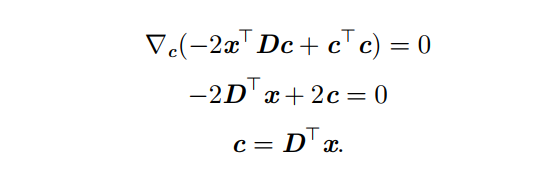

接下来挑选编码矩阵D,因为用相同的矩阵D对所有点进行编码,因此要最小化所有维数和所有点上的误差矩阵的Frobenius范数:
D ∗ = arg min D ∑ i , j ( x j ( i ) − r ( x ( i ) ) j ) 2 , s u b j e c t t o D T D = I l D^* = \displaystyle \argmin_D\sqrt{\sum_{i,j}(x_j^{(i)}-r(x^{(i)})_j)^2} ,subject \ to D^TD = I_l D∗=Dargmini,j∑(xj(i)−r(x(i))j)2,subject toDTD=Il
首先考虑 l = 1 l = 1 l=1,则D是一个单一向量d。即求
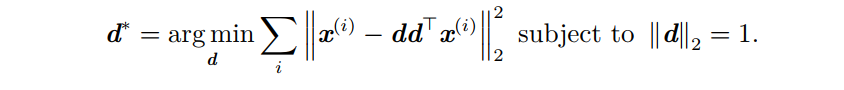
简化为:

再来考虑约束条件:
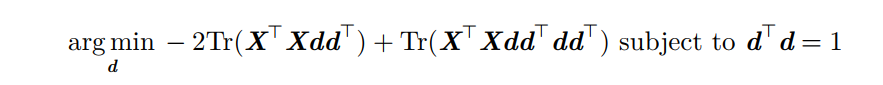
最后:
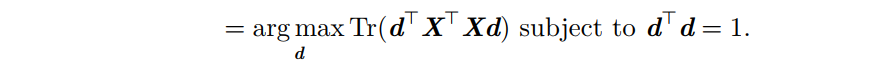
这个优化问题可以通过特征分解来解决。(这里我想的是,如果有幸被大神看到,希望帮我指正哈) X T X = Y d 是 特 征 向 量 , 那 么 Y d = λ d ⇒ d T λ d = λ d T d = λ 所 以 对 应 的 是 一 个 最 大 的 特 征 值 对 应 的 特 征 向 量 。 X^TX = Y\\d是特征向量,那么Yd = \lambda d\\\Rightarrow d^T\lambda d = \lambda d^Td = \lambda\\所以对应的是一个最大的特征值对应的特征向量。 XTX=Yd是特征向量,那么Yd=λd⇒dTλd=λdTd=λ所以对应的是一个最大的特征值对应的特征向量。
最优的d是 X T X X^TX XTX最大特征值对应的特征向量。
l = 1 l=1 l=1的情况仅得到了第一个主成分,为了得到主成分的基,矩阵D由前 l l l个最大的特征值对应的特征向量组成。
脑瓜子疼,果然一次看得多相当于白看,告辞!!!















 657
657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









