










本来以为很简单的配置,没想到中途出现了很多意想不到的问题,于是总结一波。
基本流程:
ssh免密码登录配置。(如果不配置,在启动集群时会要求你输入各个服务器的密码。如果节点过多,就GG了。)
配置jdk环境 (本人使用的是jdk 1.8)
下载并且配置Hadoop-2.6.0-cdh5.15.0 (最重要的配置,因为spark是以其hdfs为基础的)
下载并且配置spark-2.3.1-bin-hadoop2.7
一、ssh免密登录
- 生成公钥、私钥对
- 进入.ssh文件夹中
cd /root/.ssh
- 查看是否有“authorized_keys”文件,如果有,直接将公钥追加到“authorized_keys”文件中,如果没有,创建“authorized_keys”文件,并修改权限为“600”
touch authorized_keys
chmod 600 authorized_keys
- 追加公钥到“authorized_keys”文件中
cat id_rsa.pub >> authorized_keys
此时,ssh密钥分配结束。
两个云服务器执行,相同的操作,并且注意,将两个密钥在每一个服务器的authorized_keys都复制上。
vim /etc/hosts #配置主机。将两台机器的名字+ip写入。

Note:注意,好像云服务器有限制,当访问自身的话,用内网ip。所以需要在各自的控制台找到对应的内网地址,阿里云服务器上本机放上阿里云的内网ip,同理,腾讯云放本机的内网。
接着测试是否ping通:
ping -c 3 bokepad(自己的主机名)
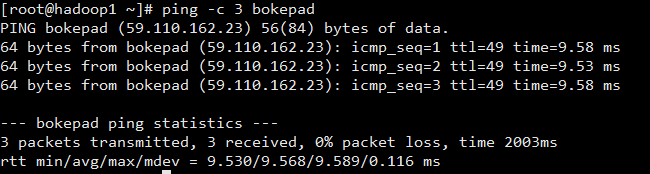
输入 ssh bokepad 即可不需要输入密码进入到bokepad为主机名的服务器。
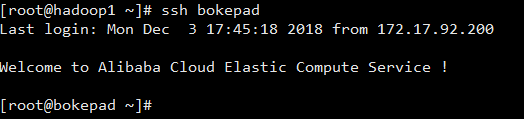
无密连接完成!和Git和码云上利用ssh上传下载是一样的原理。
二、搭建jdk环境
将jdk .tar文件放到/usr/local/java中,执行tar -zvxf jdk文件名,将其解压。

复制此路径。vim etc/profile 进行环境变量配置 JAVA_HOME JRE_HOME PATH这3个都配置

source /etc/profile 来使配置有效
java -version 看是否成功。

三、配置hadoop
本人将压缩文件放在 /usr/hadoop/ 下,执行解压指令 tar -zvxf hadoopxxxxxx.tar.gz

HADOOP_HOME 环境变量的配置见上文的截图。执行hadoop version判断是否成功。

配置集群/分布式环境
集群/分布式模式需要修改 /local/hadoop/etc/hadoop 中的5个配置文件,更多设置项可点击查看官方说明: slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
1、配置DataNode主机,这里默认把Namenode也作为数据节点
cd /usr/hadoop/hadoop-2.6.0-cdh5.15.0/etc/hadoop
vim slaves

2、基础配置(core-site.xml)

3、HDFS配置(hdfs-site.xml)

4、MapReduce配置(mapred-site.xml)没有此文件,就cp mapred-site.xml.template mapred-site.xml
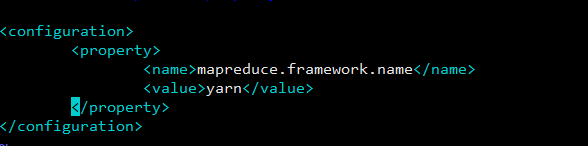
5、Yarn配置(yarn-site.xml)

格式化NameNode
hadoop namenode -format
成功的提示:

利用scp将hadoop复制到其他服务器。
scp -r /usr/hadoop hadoop1:/usr/hadoop -r是递归
接下来
cd /usr/hadoop/hadoop-2.6.0-cdh5.15.0/sbin
start-all.sh #打开集群
完成后,jps查看是否成功。
主节点:
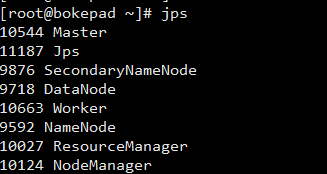 这里,如果安装完成,没有master和worker
这里,如果安装完成,没有master和worker
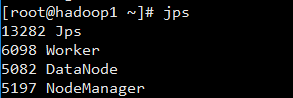
数据节点:
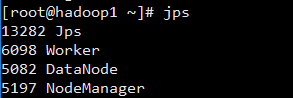 同样的,没有安装spark,所以没有worker
同样的,没有安装spark,所以没有worker
浏览器访问 bokepad:8088 和 bokepad:50070查看Yarn和HDFS相关信息


四、Spark搭建
spark使用scala语言写的,所以需要安装scala环境。这里不用多说了,下载解压,然后在etc/profile里面配置就行。上图中有。
解压spark安装包,需要修改spark-env.sh

接着在slaves添加两个ip的hostname
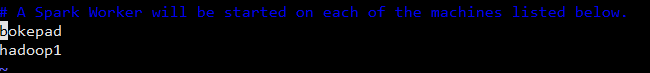
/usr/spark/spark-2.3.1-bin-hadoop2.7/sbin start-all.sh #运行spark,和前面一样,每个服务器都是这样配置。复制或者使用scp传输
jps结果
master
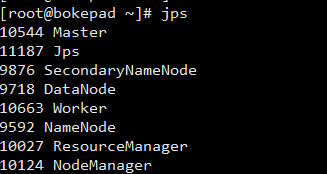
从节点
浏览器输入master节点ip:8080验证成功!
















 986
986











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









