






一:Hive
1.1: Hive的架构如下,分别包括了客户端,Driver,HiverServer2, 解析器,优化器,执行器;Mapreduce; Metastore, HDFS,如下所示:
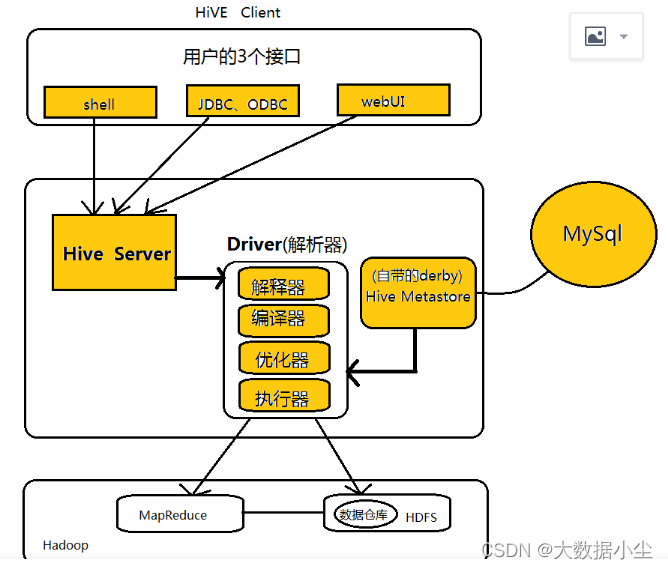
1.2: 一条hive 语句是如何转换成MapReduce 的程序的
1.2.1:当客户端的一条语句过来,解析器首先会结合Metastore 将这个sql 转换成一个抽象的语法树,期间查看表是否存在,是否有语法错误
1.2.2:接下来编译器会把这个抽象语法树转换成一个逻辑执行计划
1.2.3:逻辑执行计划估计不是最优的,这个时候优化器会进行优化,比如进行谓词下推等操作
1.2.4:执行器然后接着把这个优化后的计划转成Mapreduce 程序执行
1.3: Hive 和传统关系型数据库的区别
1.3.1:数据存储位置,hive 存放在HDFS,关系型数据库存储在磁盘
1.3.2: 数据更新,hive不支持更新,关系型数据库支持
1.3.3: 数据延迟,hive延迟比较高,关系型数据库毕竟较低
1.3.4:数据规模,前者大,后者小
1.4:4个by的区别
1.4.1:order by, 全局有序,性能不好
1.4.2:sort by ,分区内有序
1.4.3:distribute by,对数据进行一个分区,类似MR中的partition
1.4.4:cluster by,当distribute by 和 sort by 的字段相同时,就是cluster by,不过它是升序排列
1.4.5:生产环境中基本不用order by,都用sort by 以及cluster by
1.5: hive 中的UDF,UDTF,UDAF
UDTF实现的话(一对多),继承GenericUDTF,要实现三个方法,initialize(自定义输出的),process(结果返回),以及close
UDAF实现的话(多对一),继承UDAFEvaluator,要实现initialize,iterator(迭代处理每一行数据),terminatePartial(MapReduce 结果输出);merge(合并中间结果);termiate(输出最终结果)
1.6:hive的开窗函数
over中需要注意的几个点:
current row,当前行
n leading ,前面n行
n FOLLOWING, 后面n行
lag(col,n) 前面第n行
LEAD(col,n) 后面第n行
unbounded leading ,一直到前面第一行;unbounded following 一直到后面最后一行。
二:Hbase 随想:
2.1:Hbase的存储架构图如下
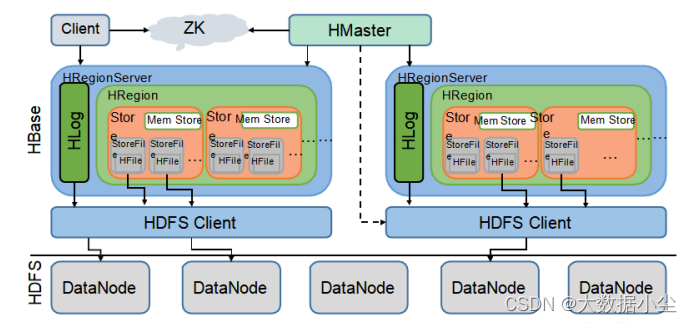
如图所示,Hbase 是由几部分组成的,Hmaster,RegionServer,HRegion,Hstore, memstore, storeFile;
那么这些东西分别是干什么用的呢?
首先Hmaster就不用多说了,整个集群的话事人,它还有几个分身,所以可以有多个Hmaster,做备份支持工作;它控制着整个集群的运转;如何控制的呢,那就当然少不了zookeeper这个小狗腿了;regionServer向Hmaster 实时汇报数据;hmaster就会说,zookeeper, 我这边记一份;你要给我记者一份,或者他么等我挂了我分身来找你要的时候,你如果没有,你就该gg了;
RegionServer 那就是实际存储数据干活的人了;来了数据和它打一个招呼;它会先识别下,然后看是已有的数据么,不是的话看那个Hregion空闲,让他过去,还给他独立分配一个Hstore 供它住,奶奶的,待遇还挺高;如果是已有的某个columnFamily的数据,那么就会往那个columnFamily对应的Hstore 放;
所以Hstore和columnFamily一一对应的关系;数据进入到hstore,首先会进入memstore,如果memstore满了,一般是大于128m,则会落磁盘形成storeFile; memstore 其实就是个内存缓冲区;数据写进来的时候首先会进入wal,memstore如果没有溢写就写入memstore,如果有等一会;
4: Flink
4.1:FLink 是啥,一个分布式大数据处理框架,刚开始为了实时处理流式数据,后来就在搞流批一体;
支持大量数据的计算,容错管理,资源管理,诸多api 提供给用户编写分布式任务;
4.2: Flink 的分区策略
Flink 中的并行度有多大,那么对应的task就有多少个,这个task指的是subTask 的总量;
并行度并行度,不就是并行执行的任务数量嘛;所以我们假设设置整个任务的并行度为1200,slot为30,那么执行任务的时候每个算子可以达到的并行度可以达到1200;但是这个算子是分配在40个TaskManager 中执行的,每个TM里面的slot 有30;所以这个算子在这个TM中可以达到的并行度可以是最高30了;
所以分区也是基于刚刚的那个30出发的
4.3: flink 的重启策略
因为需要容错,所以任务有可能重启,有什么重启的方法呢?
4.3.1: 固定时间重启策略,fixed-delay-restart-strategy; 固定时间间隔和固定次数
4.3.2: 故障率重启策略,failure-rate-restart-strategy; 固定时间内超过多少次失败就失败了
4.3.3: 没有重启策略
4.3.4: 后备策略,支持检查点
4.4:Flink 的分布式缓存
缓存,说白了就是把一个东西存到某些地方,以方便快速取用,flink 的分布式缓存也是把所谓的一个文件啊注册放到taskMangager 上面,然后运行的时候用这个文件,减少了网络传输,提高了处理速度;一般使用如下代码实现,但是如果想要在算子中访问这个文件,这个算子就必须集成RichFunction, 因为需要获取运行的是上下文来获取这个缓存的文件
//1:注册一个文件,可以使用hdfs上的文件 也可以是本地文件进行测试
env.registerCachedFile("/Users/wangzhiwu/WorkSpace/quickstart/text","a.txt");
data.map(new RichMapFunction<String, String>() {
private ArrayList<String> dataList = new ArrayList<String>();
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
//2:获取运行时的上下文,然后获取对应的文件。
File myFile = getRuntimeContext().getDistributedCache().getFile("a.txt");
List<String> lines = FileUtils.readLines(myFile);
for (String line : lines) {
this.dataList.add(line);
System.err.println("分布式缓存为:" + line);
}
}
4.5: Flink 中的广播变量
广播变量,咋一听感觉和那个分布式缓存差不多啊,nonono,差的还是有不少的,广播变量说的是把多个任务会用到同一份数据集分发到不同的节点上,确保每个节点只有一份;就不用进行频繁的shuffle了,极大地提高了数据处理的速度;而分布式缓存是读文件,不是数据集;而且一个是基于内存,一个基于磁盘;广播变量也是通过运行时的上下文获取的。
4.6: Flink 中的窗口
时间窗口和计数窗口
时间窗口中的session window 类似于web中session,规定时间内没有数据就会退出,一次性的。
计数窗口就是count window,它是根据相同key的数量来触发计算的,如下所示:
.countWindow(10) 当相同的key的数量到了10 就开始触发窗口计算
.countWindow(10,2),每收到两个相同的key 就开始触发计算,计算的是10个key的元素
4.7: Flink 的状态存储
为什么要有这个状态存储呢?说白了就是怕流式计算任务中断,之前计算的数据丢掉了,所以要把之前计算的数据保存起来,这就是checkpoint 和 状态存储的意义所在,主打一个容错。
所以这些状态数据就要存储在一个地方,FLink 提供了三个地方可供存储,分别是memoryStateBackend , FsStateBackend, 还有个是RocksDBStateBackend;
第一个肯定是基于内存,把状态数据放入内存,第二个是把状态数据放到外部存储系统,比如hdfs;第三个是热数据放在内存,冷数据放到文件系统;
4.8: Flink 中的 WaterMark
flink 中的waterMark 是什么意思呢?说白了就是给数据流设置一个标准位了,允许一些数据迟到,在数据延迟和处理速度上做个平衡;一般是和flink 的timewindow 结合,当watermark>= windows 的闭区间时,就会触发窗口计算,数据才会算出来;那么watermark 一般是定义为eventTime +ts ,做个容错嘛,就是包容一些延迟数据。
4.9:Flink 的TableEnvironment 是用来干嘛的?
4.9.1: 第一点就是flink table 和flink sql的集成核心,注册用户函数;
4.9.2: 在内部catalog 中注册表
4.9.3: 注册外部的catalog;
4.9.4: 执行sql
4.9.5: 将datastream 或者dataset 转换成表
4.10: Flink sql 是如何被执行的呢?
首先,兄弟们要知道的是,Flink sql 的解析用的是Apache Calcite 这个框架,专门用来解析sql,然后变成可以实际运行的代码的,具体是怎么运行的让我们看看下面的图;
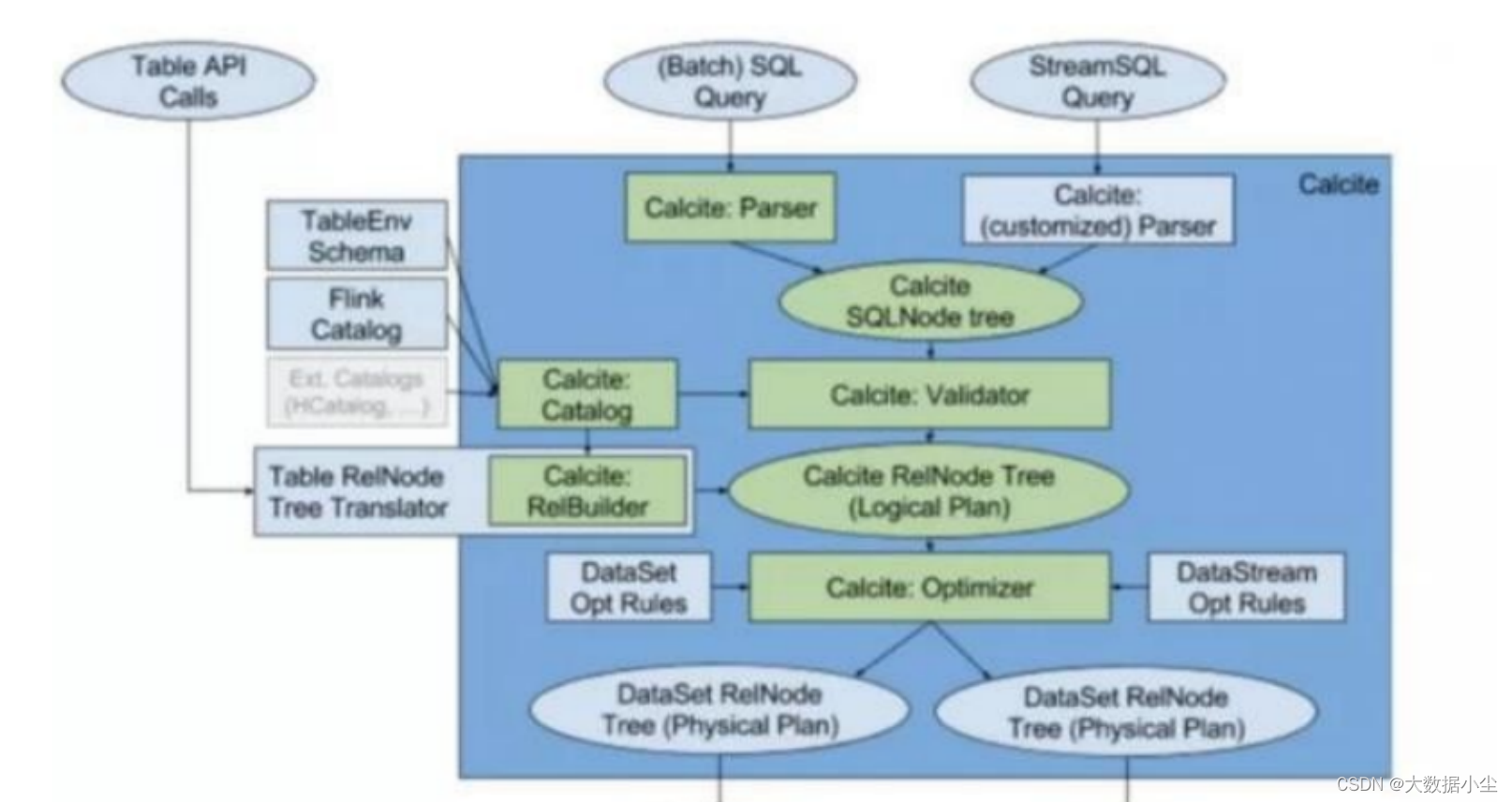
4.10.1: 用户提交了sql 之后,calcite 的parser 就会把这些sql 准换成语法树;
4.10.2: 紧接着calcite 的优化器就会对上面的语法树进行一个响应的剪枝啥的操作进行相响应的语法检验,生成一个逻辑计划;
4.10.3: 接着使用calcite的优化器和flink 的优化规则生成一个物理计划
4.10.4: 最后使用代码生成器和api 对物理计划变成可以执行的代码,提交运行。
4.11: Flink 是如何支持流批一体的?
Flink的开发者认为Flink 的批处理是流处理的一种特殊情况,批处理就是有限的流处理,说白了在一个窗口内汇集一些流数据不就成了批处理嘛;所以使用一个引擎统一了批处理和流处理。
4.12: Flink 是如何做到高效的数据交换的呢?
Flink 之间的task的数据交换是由taskManager 负责的,taskManager 的网络组件首先会从buffer中把一条条数据取出来,然后攒一批再发送,而不是一条条发;这样有效降低了网络负载,高效利用了网络资源
4.13: Flink 的分布式快照原理以及Exactly-only-once
4.13.1: 为什么要做快照呢?快照就像我们拍照片似的,记录下你之前的状态;同理,这个分布式快照把状态记录下来就是为了准备数据的恢复;
分布式快照参考的算法是Chandy-lamport的算法,其中最重要的一个机制就是checkpoint ,就是检查点,它就像一个守门员似的,当每批人经过它,它都会给大家插入一个编码,编码是递增的;然后这个编码就会跟着这批人流动吧,当到达下一个大门之前,要确保所有的同一批编码的人到了,这个守门大爷才会给大家照相,然后记录大家的状态,并把这个状态告诉给JobManager 老板,然后存入到状态管理的后段;
然后又有人会问,但是在到达下一个大门(某个算子) 之前并不是所有的人都会同时到达啊,这个时候怎么办呢,没有办法只有等,等所有人到达之后才开启快照
4.13.2: 那么Flink 又如何保证Exactly-once 呢?
使用两阶段提交协议,分别是预提交和正式提交;
想要保证Exactly-once,Flink 把数据写入到下游那就需要支持事务了,对吧;那么这个两阶段提交协议也是这样,要么全部成功,要么全部失败;一般我理解的两个阶段就是,投票和提交;
首先,开启事务,创建一个临时的文件夹;
flink 问所有的算子,大家同意把所有的数据写入这个临时的文件夹嘛,大家说同意,一旦碰到那哥们网络不好没回答那就gg了,所有人都不会把数据写入,都同意那就写入;
正式提交阶段,Flink 问所有的兄弟们checkpoint 完成了没有,快照存储到后段了嘛,该准备提交了,areyouok?兄弟们说可以了,这个时候才把数据提交给sink端了
4.14: Flink 序列化
为什么单独讲到这个序列化呢?因为java 序列化额外占用的空间优点多,所以Flink 说那我就自己实现一个序列化的处理逻辑;它有一个基础的类型,叫做TypeInformation;所有要序列化的类都要继承这个类
BasicTypeInfo, 任意Java的基本类型或者String类
BasicArrayTypeInfo, 数组类的序列化类;
WritableTypeInfo, 任意HadoopWritable 接口的实现类;
TupleTypeInfo, 和Tuple相关的实现类
PojoTypeInfo,和Pojo相关的实现类
GenericTypeInfo,自定义实现的类
4.15: Flink 使用聚合函数出现热点问题该如何解决?
4.15.1: 业务上避免
4.15.2: key 重新设计
4.15.3: 微批处理
4.16: Flink 的反压是啥
4.16.1: 反压说白了就是把压力传过来了,下游的压力传到上游来了,什么压力呢?就是消费处理数据的压力,上游发送的数据太多,一时间下游处理不完,然后告诉上游不要再发数据了,上游也被阻塞了,就是感受到了压力。那么Flink 是如何实现的呢?
Flink 1.5 之前是用的TCP Based 反压机制,说白了就是多个task服用一个socket传输数据,如果某个task的数据消费不过来,搞得socket就不能传输数据了,这样对大家都不好;
所以FLink 1.5 之后就弄了个Credit based 的反压机制,说白了就是上游先告诉下游我会发送多少条数据,然后经过buffer以及network 传输,下游这个时候也反馈说我有多少个buffer 可以提供,如果buffer够可以发送数据,如果不够就等着,这样也不用阻塞其他task;
模型如下所示:
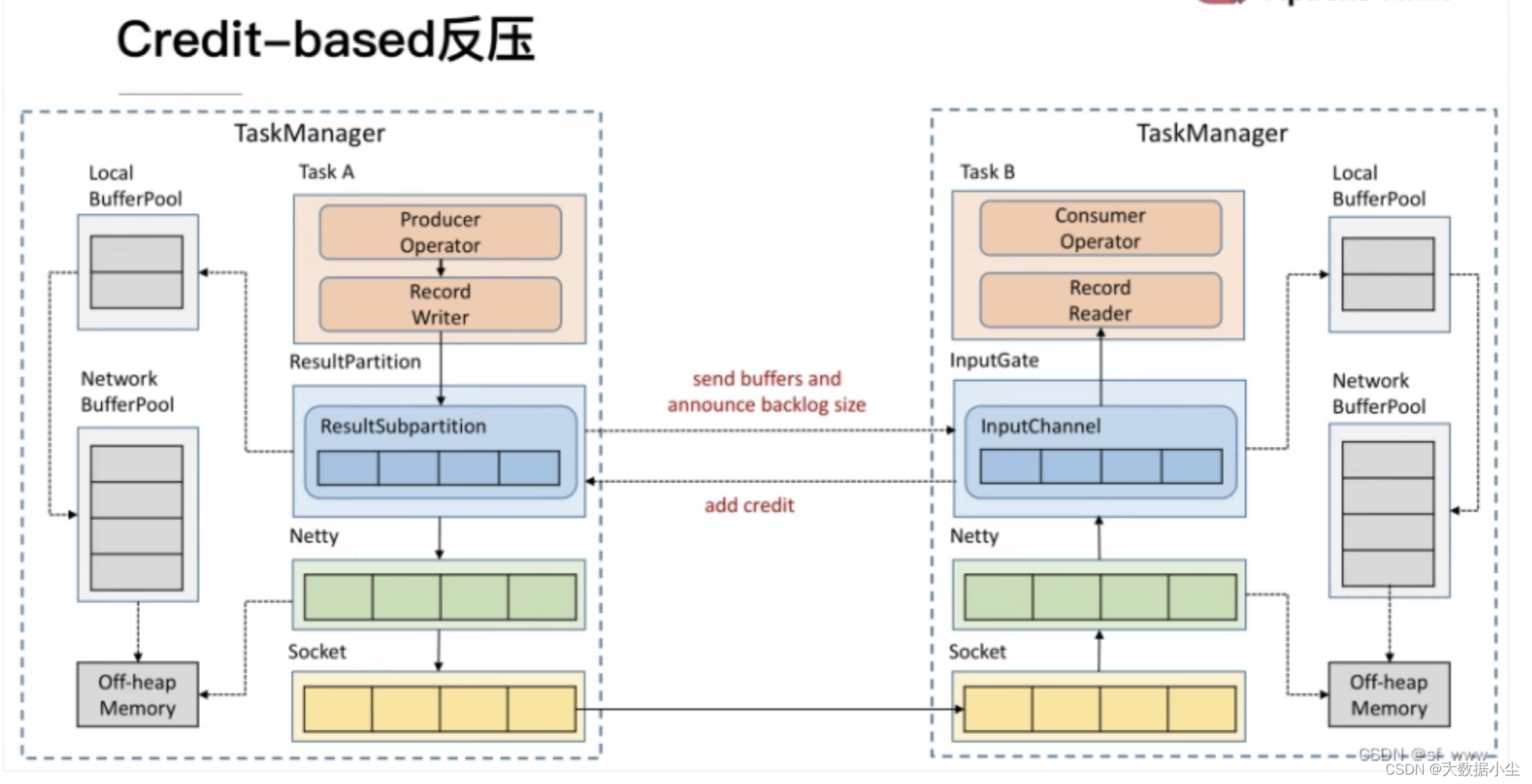
4.16.2: 如果出现了反压,说明数据处理延迟了,我们要找到对应的算子,看看到底具体是什么问题导致的,是数据倾斜了,还是内存给的太少了,或者是并行度设置的不合理呢,具体问题具体分析
4.17: Flink 中的算子链是什么样的?
4.17.1: 算子链算子链,说白了就是说算子串在一起形成一个链条,这样串在一起的好处是什么呢?最重要的一点是减少了线程之间的数据传输,因为算子和不同的算子之间如果不在同一个slotGroup 里面就是处于不同的线程,所以减少了数据传输和线程的切换,减少了消息的序列化和反序列化,提高了任务执行效率。
4.17.2: 那么什么样的算子可以形成算子链呢?
首先两个算子的并行度要一致
第二个是下游算子的入度为一
三一个是上下游算子要在一个SlotGroup里面
四一个是上下游算子的Chain 策略要兼容,比如上游的策略是ALWAYS 或者HEAD,那么下游的算子就要是ALWAYS;
五一个是上下游的分发策略是ForwardPartitioner
4.18: Flink 所谓的三层图是哪几层图:
StreamGraph, 最贴近代码的逻辑图,是代码层面的逻辑拓扑结构
JobGraph 则是经过StreamGraph,增加了些slot,代码所需的文件,进行了一些任务的合并
executionGraph,则是最贴近底层的拓扑结构图,包含了任务具体执行所需的内容。
4.19: Flink job的提交执行流程
一个taskManger 对应一个JVM, 一个slot 对应一个线程
4.20: Flink 数据抽象以及数据交换过程
因为JVM的内存管理不太行,java 对象存储密度低,FUll GC等,所以Flink 走上来自主管理内存的道路。
Flink 最底层的内存管理是基于byte[] 数组,然后它上面的抽象就是一个memorySegment,大小为32kb,可以看作是一个内存块的抽象,既可以是byte[], 也可以directMemeory ,那么从算子之间传输对象的还是Buffer 或者StreamRecord, 它们还是建立在Buffer 的基础之上的抽象。
4.21: Flink CEP
全称是Flink Complexible Event Processing, 就是复杂事件处理,它的流程就是设定一个源源不断的规则,对进来的事件流做个判断,如果有符合相关判断的事件就收集起来,然后做个告警,分别有patter,event等关键概念,
Flink CEP内部是用NFA(非确定有限自动机)来实现的,由点和边组成的一个状态图,以一个初始状态作为起点,经过一系列的中间状态,达到终态。点分为起始状态、中间状态、最终状态三种,边分为take、ignore、proceed三种。
如下所示:

take:必须存在一个条件判断,当到来的消息满足take边条件判断时,把这个消息放入结果集,将状态转移到下一状态。
ignore:当消息到来时,可以忽略这个消息,将状态自旋在当前不变,是一个自己到自己的状态转移。
proceed:又叫做状态的空转移,当前状态可以不依赖于消息到来而直接转移到下一状态。
样例代码如下:
public class CepExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream<LoginEvent> stream = env
.fromElements(
new LoginEvent("user_1", "0.0.0.0", "fail", 2000L),
new LoginEvent("user_1", "0.0.0.1", "fail", 3000L),
new LoginEvent("user_1", "0.0.0.2", "fail", 4000L)
)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<LoginEvent>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<LoginEvent>() {
@Override
public long extractTimestamp(LoginEvent loginEvent, long l) {
return loginEvent.eventTime;
}
})
)
.keyBy(r -> r.userId);
Pattern<LoginEvent, LoginEvent> pattern = Pattern
.<LoginEvent>begin("first")
.where(new SimpleCondition<LoginEvent>() {
@Override
public boolean filter(LoginEvent loginEvent) throws Exception {
return loginEvent.eventType.equals("fail");
}
})
.next("second")
.where(new SimpleCondition<LoginEvent>() {
@Override
public boolean filter(LoginEvent loginEvent) throws Exception {
return loginEvent.eventType.equals("fail");
}
})
.next("third")
.where(new SimpleCondition<LoginEvent>() {
@Override
public boolean filter(LoginEvent loginEvent) throws Exception {
return loginEvent.eventType.equals("fail");
}
})
.within(Time.seconds(5));
PatternStream<LoginEvent> patternedStream = CEP.pattern(stream, pattern);
patternedStream
.select(new PatternSelectFunction<LoginEvent, Tuple4<String, String, String, String>>() {
@Override
public Tuple4<String, String, String, String> select(Map<String, List<LoginEvent>> map) throws Exception {
LoginEvent first = map.get("first").iterator().next();
LoginEvent second = map.get("second").iterator().next();
LoginEvent third = map.get("third").iterator().next();
return Tuple4.of(first.userId, first.ipAddress, second.ipAddress, third.ipAddress);
}
})
.print();
env.execute();
}
}















 9541
9541











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









