






在了解Flink CDC之前,我们先来了解下什么是cdc?兄弟们,回忆下,cdc 全称是Change Data Capture, 中文的意思就是变更记录获取。
所以兄弟们是不是立马就想到了mysql的binlog 日志,以及对应的canal, canal 就是专门获取对应的数据变更并同步变更数据给其他人的。没错,Flink cdc 也就是这个作用了,说白了就是做的一个数据集成的作用,实时把变动的数据同步给应用方呗。
然后兄弟们就会想,该不会Flink cdc 也是用的canal 去做的这个数据同步吧,那必然不是的,毕竟canal 是不支持数据的全量数据同步的。Flink cdc 用的是老外的数据同步工具,Debezium,取其精华,去其糟粕嘛,其实除了debezium ,还有些比如oracle Goldgenerate,也实现了全量和增量同步的,如下所示:
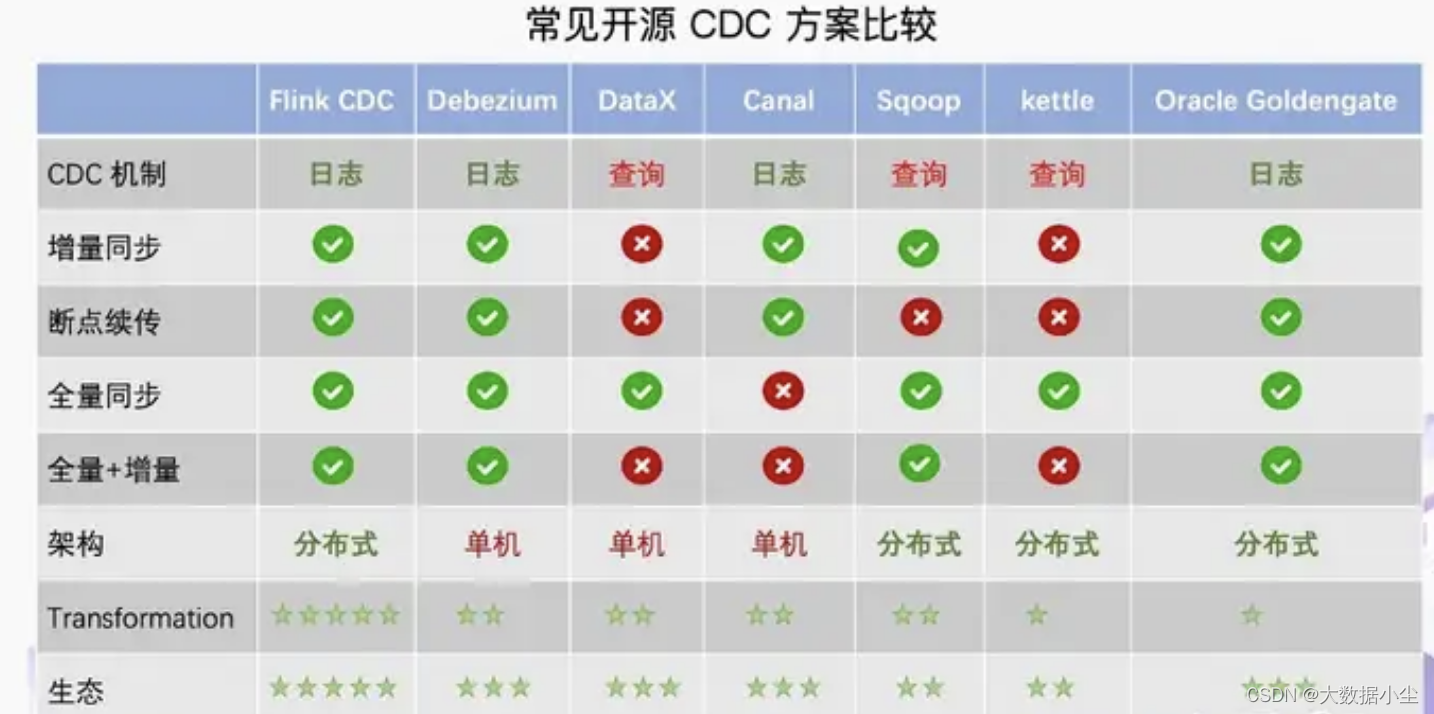
Flink 官方没有选择oracle 的可能就是Debezium 更加完善点了,关键是Debezium 里面的数据结构和Flink 里面的数据结构非常相似,更容易兼容
一:Flink cdc 1.x 的实现及问题
如上所示,Flink cdc 1.x 使用Debezium实现了异构数据源之间的同步,但是还是出现了一些问题,主要是Debezium 是会对表加锁的,debezium 也是单线程的,所以大家在使用的时候就产生了如下问题,比如mysql hang 住了,不支持多并发,容错性不高;
想要弄明白前面的几个问题,我们先来了解下Flink cdc 下面Debezium 是如何加锁同步数据的呢?请看下图:
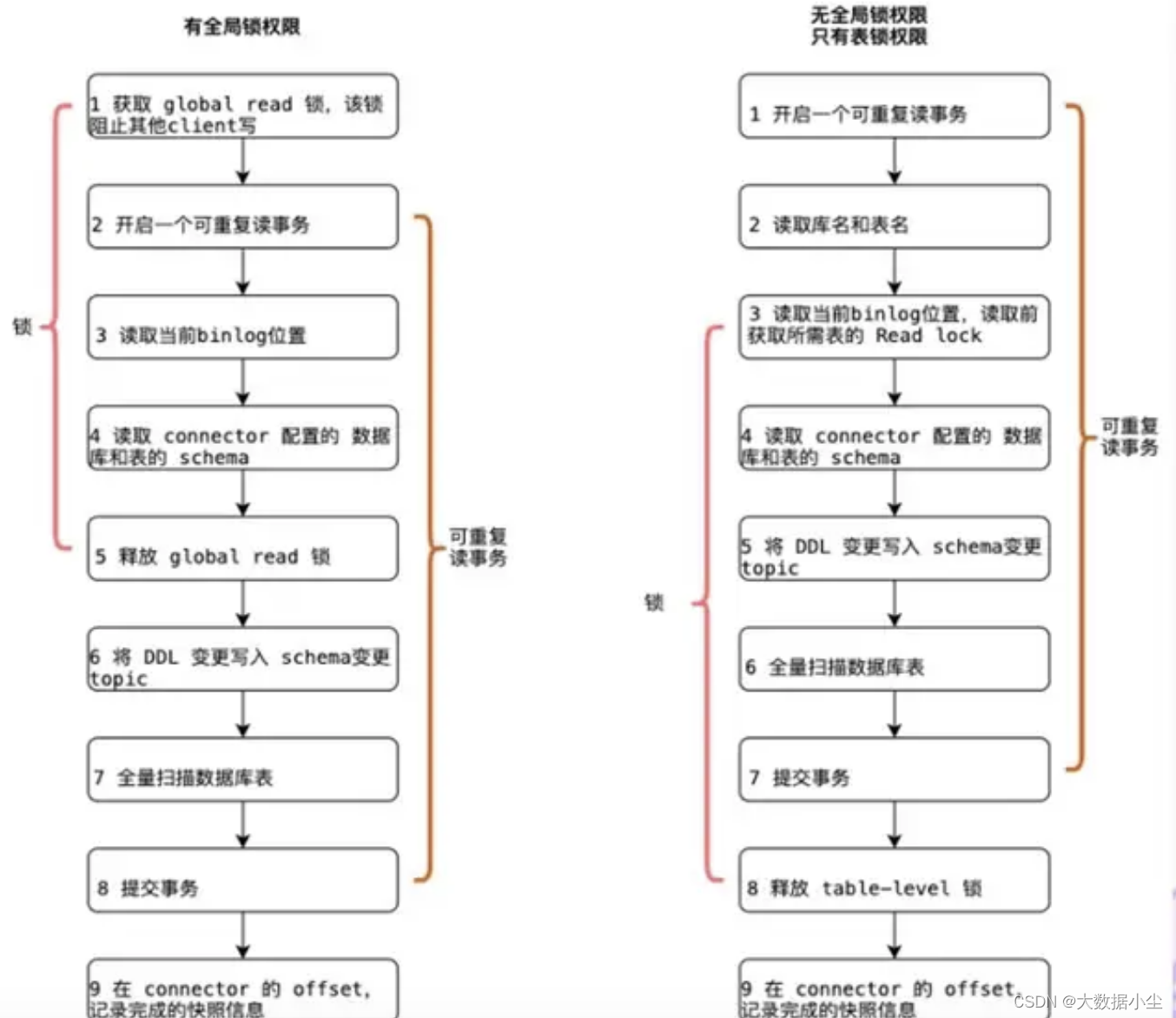
简单点来说,就是一旦开启同步数据的事务了,Debezium 就会对全局加锁,先把当前加锁的这个时间点的全部数据select 出来,这需要一点时间的,然后这个时间节点的select 事务啊,update 事务啊,都会被阻塞,严重的时候会导致mysql 的整个进程都被hang 住了,提供不了服务了,所以我们Flink 就要进入2.x 时代。
二:Flink 2.x 时代
Flink 2.x 时代就是说既然大家都觉得这个锁没有必要了,那就把Debezium的锁踢开,哈哈哈,与时俱进嘛;踢开之后我们就引用了Netfix 的DBlog paper 的思想;
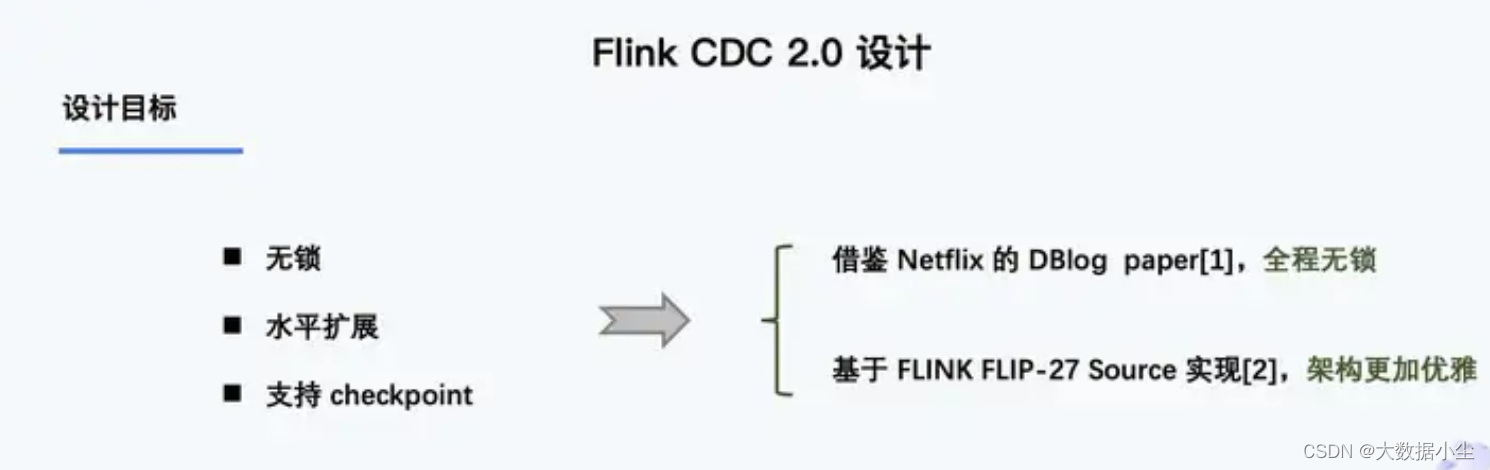
DBlog paper的思想说白了也是分而治之的思想,既然我对全局表加锁会有比较大的影响,那么我把数据做切分,每一段数据做大数据一致,那是不是就可以保证数据的整体一致呢?怎么说呢
假如mysql的表里面有100万条数据,那么我把这些数据切分成1万个chunk(chunk 本意是树干,在这里就是一段数据集合的意思);每个chunk 里面有100条数据,先记录这个chunk里面的最低位和最高位;比如是101和200;读完之后把这个数据存入一个缓冲区,我们叫做buffer;如果后期有个binlog的chunk 过来,比如是105,150和160的数据发生了变化,那么我们就会针对相应的值改动,并不会改动全部的值,改动效率就比较高了;这就是无锁的大致思想了;
水平扩展说白了就是把原来的这个单线程换成多线程的处理嘛,由Flink的source 去实现的;做个checkpoint 也是对最新的那些buffer和chunk 做个checkpoint ,实现了容错;
三:Flink 3.x 的实现
Flink 2.x 实现了性能的优化,Flink 3.x 更多的是实现了业务的优化,比如支持分库分表,整库同步等等,可以参考 Flink CDC 3.0 正式发布,详细解读新一代实时数据集成框架















 1075
1075

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









