






本项目代码已开源,具体见:
后端工程:express-blog-backend
数据库初始化脚本:关注公众号程序员白彬,回复关键字“博客数据库脚本”,即可获取。
根据费曼学习法,把知识传递给别人并让ta懂,你才是真的学会了,好的,不偷懒,继续更新!
html or markdown ?
本节接着讲具体业务的实现。在我们搭建博客站点时,最核心的部分也就是文章内容。从用户视角看,文章内容就是图文甚至视频等元素的组合;从开发者角度看,文章内容的呈现形式就是一段渲染好的 DOM。
但是从数据存储的层面看,我们应该存储什么信息呢?一般来说,会考虑存储 html 文本或者 markdown 文本。
如果我们是在为公司做一个新闻公告类的功能,通常这个功能的使用者并不是程序员,而是运营等其他岗位的人,他们通常在编辑新闻时需要所见即所得的效果,因此我们在编辑器这块会优先选择富文本编辑器,存储的内容自然也就是 html 文本。
但是对程序员博客或者文档网站来说,通常会选择 markdown。对我个人来说,我比较在意以下几点:
- markdown 是更轻量的标记语言,源文本格式更清晰易阅读,通常不会携带样式信息产生干扰。
- 从写博客的体验上来说,markdown 的效率也更高,因为博客通常是图文,只要记住简单的标题、图片、链接、加粗等常用语法,写出来的内容就是结构化很清晰的。
- 渲染样式可以在呈现页或者组件中再去控制,非常容易自定义!
- 非常容易维护,各平台通用,这是核心!!!
那我们接下来就介绍一下如何基于 markdown 来实现文章的编辑、存储、查询、展示等功能。
markdown 编辑
markdown 的编辑功能是需要一个编辑器去支撑的,比如我们在掘金等平台上写文章用的编辑器,就支持 markdown 模式。
但是开发一个编辑器的成本比较高,我不推荐在自己的博客中去完整实现一套编辑器功能,这需要花费大量的时间去实现工具栏、交互、输入、渲染等功能。用 typora 或者 notion 它不香吗?
我更倾向于去使用市面上优秀的编辑器(无论是在线的或者是离线的)去编辑内容,写好了再复制或导入到我们自己的博客系统中,只在博客系统中加入预览功能即可,这样可以节约我们很多时间。
关于预览,本质上是通过 markdown 引擎将 markdown 文本解析为 html 文本,然后通过innerHTML等方式去渲染出来。有下面这样一个效果就足够了!
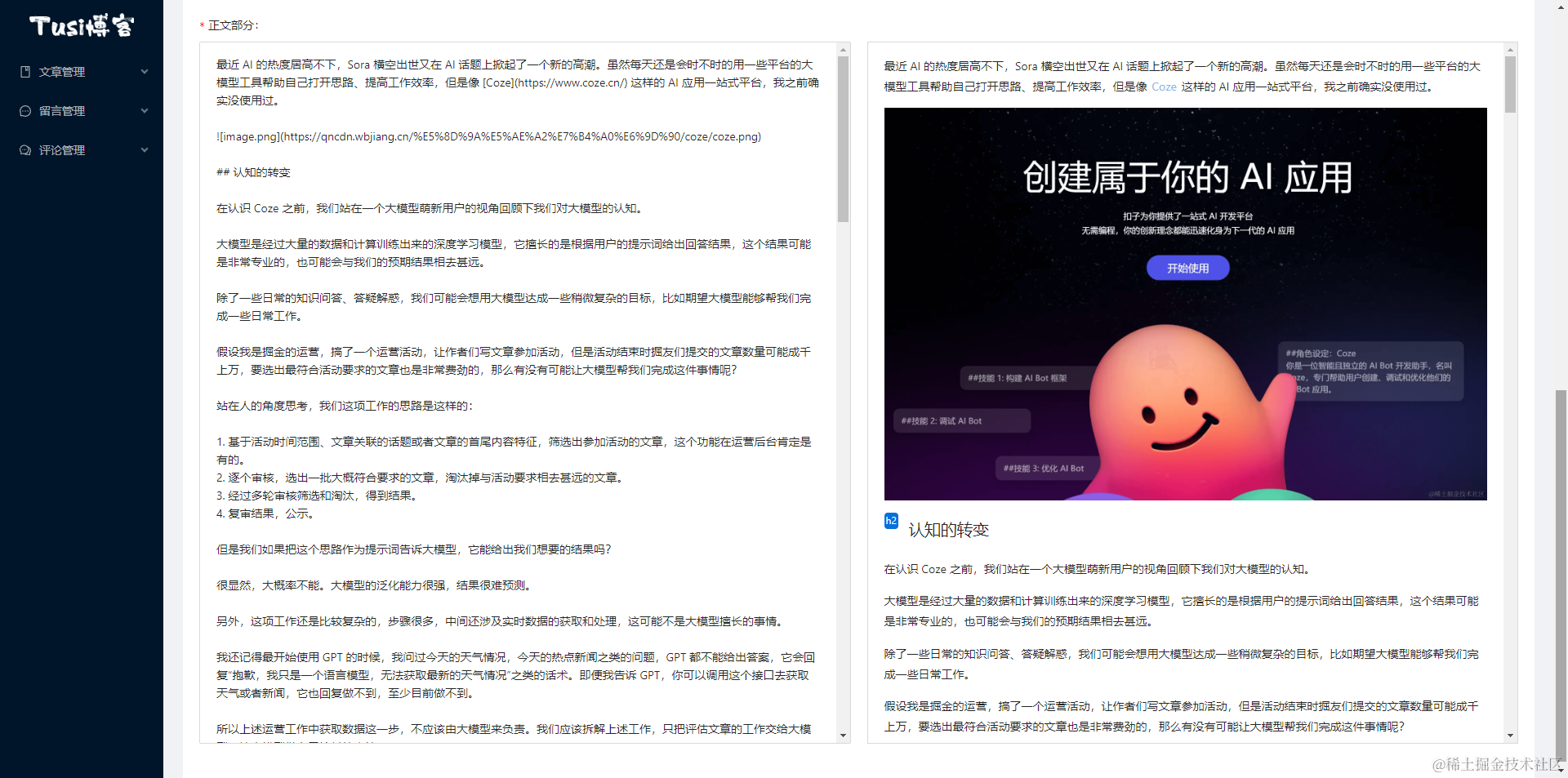
保存文章
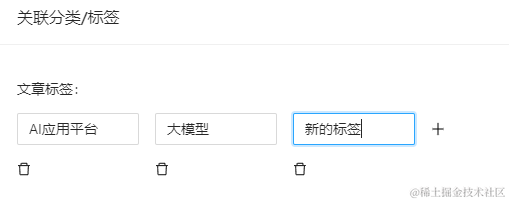
除了 markdown 之外呢,文章还有一些重要的信息需要保存,比如标题、封面图、作者、摘要、分类、标签等。
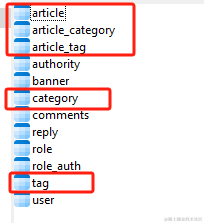
标题、封面图、作者、摘要这些信息都是附属于文章的,所以放在 article 表中即可。分类和标签这些都要靠关系表去维护。文章和分类是多对多的,标签同理。
所以我们大概会用到这些圈起来的表。
其中主表 article 设计这么一些字段即可,如果你 clone 下来认为有哪里不合适的,可以另外去修改或扩展。
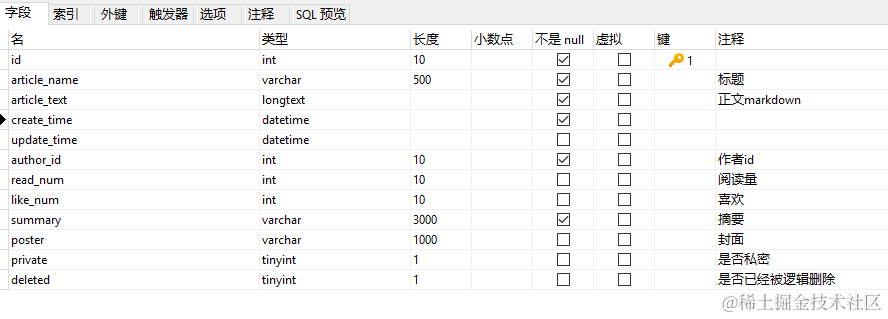
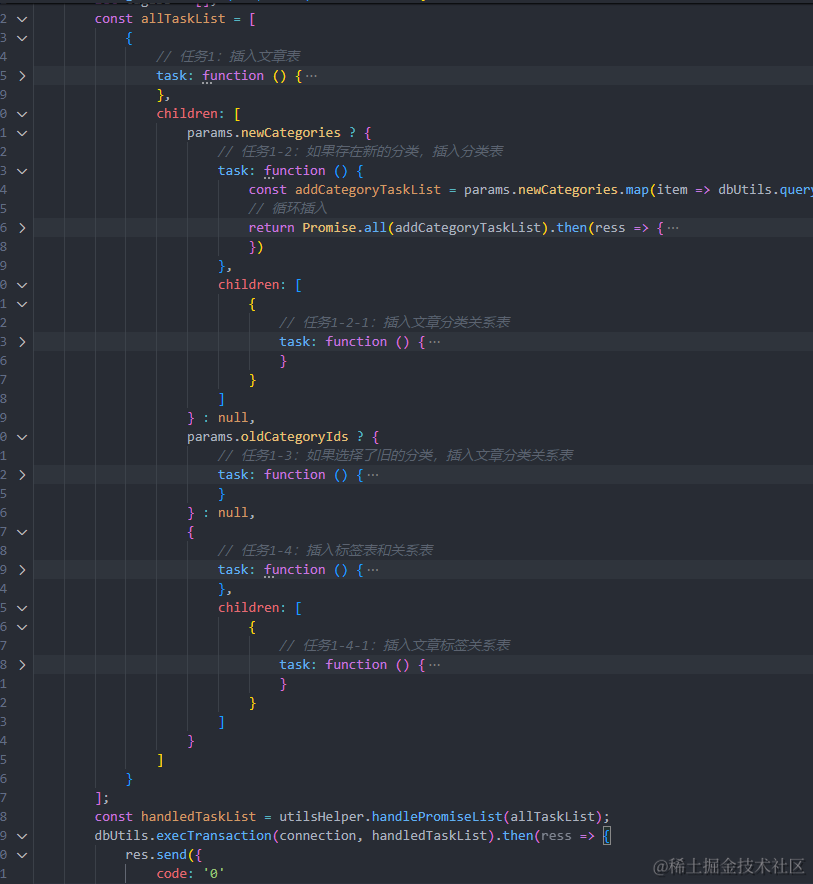
整个新建文章的过程其实涉及到关键几步:
- 插入文章表记录。
- 判断是否插入新的分类、新的标签。
- 关系表 article_category, article_tag 插入。
那么我们插入文章记录就是用到 INSERT INTO 语句。
INSERT INTO article (article_name, article_text, summary, author_id, poster) values (?, ?, ?, ?, ?)
可以看到我们只插入了 article_name, article_text, summary, author_id, poster 这些信息,其中 author_id 也是外键去关联的 user 表的主键。create_time 我们也不需要处理,MySQL 设置该字段 DEFAULT CURRENT_TIMESTAMP 即可。
剩余的分类标签信息就是用关系表去做的。
针对分类,我们要看这篇文章是否引入了新的分类,如果引入了新的分类,就先创建分类表的记录,再去插入关系记录。

标签的处理也是同样的,但是在前端,我们并没有完全把所有标签都展示出来提供选择的能力,而是只提供了输入的能力,通过输入再去匹配数据库里有没有对应的标签,从而判断是否需要插入新的标签记录。
由于这里涉及多个步骤,我们需要用事务来处理,具体可以下载源码再去了解。
文章详情页的展示
由于分页在这一篇《Vue3+TS+Node打造个人博客(分页模型和滚动加载)》文章中已经讲过了,这里我们接着将文章详情页的实现。
在详情页中,主要就是取出 detail 数据来展示,也就是查询出 id 对应的文章记录来展示。
另外就是把上一篇下一篇这种导航式信息查询出来,方便读者继续浏览!
还有文章的评论,这一部分留到后面单独介绍!
我们先看怎么取出详情数据,主体就是一个入门的 SELECT 语句,但是要把分类等关联信息带出来,还会用到一点连接查询。语句大概是这样的:
SELECT a.*, u.nick_name AS author, GROUP_CONCAT(DISTINCT c.id SEPARATOR " ") AS categoryIDs, GROUP_CONCAT(DISTINCT c.category_name SEPARATOR " ") AS categoryNames, GROUP_CONCAT(DISTINCT t.id SEPARATOR " ") AS tagIDs, GROUP_CONCAT(DISTINCT t.tag_name SEPARATOR " ") AS tagNames FROM article a
LEFT JOIN user u ON a.author_id = u.id
LEFT JOIN article_category a_c ON a.id = a_c.article_id
LEFT JOIN category c ON a_c.category_id = c.id
LEFT JOIN article_tag a_t ON a.id = a_t.article_id
LEFT JOIN tag t ON a_t.tag_id = t.id
GROUP BY a.id
having a.id = ?
我们来拆解下这个过程,首先查主表信息:
// id 取实际的 id 即可
SELECT * FROM article a WHERE id = 147
运行后我们发现文章的基本信息都有了,

接着我们引入比较简单的作者信息,作者来源于 user 表,做个左连接查一下。
SELECT a.*, u.nick_name
FROM article a
LEFT JOIN user u ON u.id = a.author_id
WHERE a.id = 147
此时作者名字信息已经有了,来源于 user 表的 nick_name。
感觉好像已经完成了一大半,实际上可能五分之一的工作量还没做完。在我之前的 UI 设计上,是在详情页加入了分类和标签的,虽然现在去掉了这部分,但是通常来说,后端还是要能返回这些信息。
我们试着通过左连接把分类信息加进来,考虑到文章和分类多对多的场景,我们换一篇关联了多个分类的文章试试。
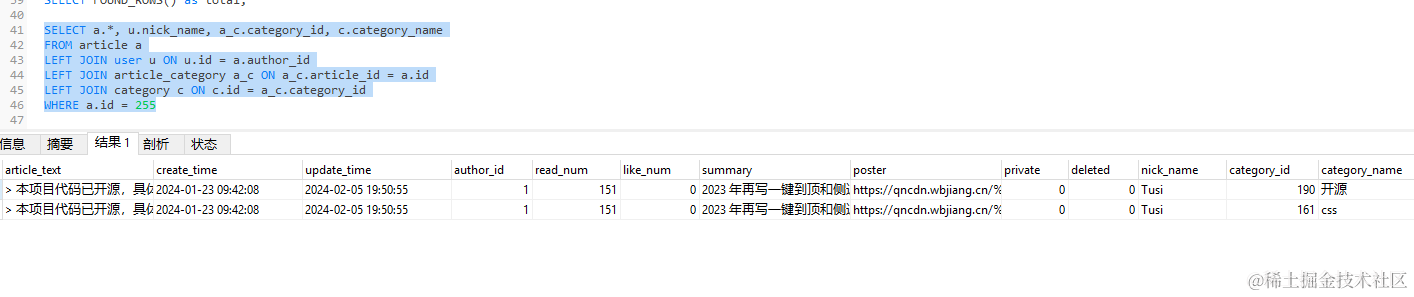
SELECT a.*, u.nick_name, a_c.category_id, c.category_name
FROM article a
LEFT JOIN user u ON u.id = a.author_id
LEFT JOIN article_category a_c ON a_c.article_id = a.id
LEFT JOIN category c ON c.id = a_c.category_id
WHERE a.id = 255
这里是先连接关系表,再去连接分类表。
我们发现结果有两行,这很正常,因为这篇文章关联了两个分类嘛。
但是我们肯定只想让结果以一行的形式出来,因为我们是查询一篇文章的详情嘛,所以我们做个分组再聚合,这用到了 GROUP BY 和 GROUP_CONCAT。
SELECT a.*, u.nick_name, GROUP_CONCAT(a_c.category_id) as categoryIds, GROUP_CONCAT(c.category_name) as categoryNames
FROM article a
LEFT JOIN user u ON u.id = a.author_id
LEFT JOIN article_category a_c ON a_c.article_id = a.id
LEFT JOIN category c ON c.id = a_c.category_id
WHERE a.id = 255
GROUP BY a.id
这大概拿到了我们期望的效果。

同理,我们把文章所属的标签信息也关联进来。
做了这些之后,文章详情数据就显得比较饱满了,基本能满足一个博客文章详情的展示了。
上一篇下一篇是怎么得到的?

那么上一篇和下一篇这种邻接关系是怎么查询出来的呢?
我们知道,相邻的文章,id 是有联系性的,以 id=10 为例的一篇文章来说,通常它的上一篇文章 id 应该是 9,下一篇文章 id 应该是 11。还有些情况要考虑:
- 上一篇或者下一篇不存在的情况,因为 id=10 也可能是第一篇文章,也可能是最后一篇文章。
- id 并不连续,可能 id=9 的文章已经被删除了。id=11 同理。
所以以 id=10 为例,我们的策略是:
- 找出比 10 小的 id,同时按 id 降序排列,用 LIMIT 1 限制只取出一条,这一条就是对应着上一篇文章的 id
- 找出比 10 大的 id,同时按 id 升序排列,用 LIMIT 1 限制只取出一条,这一条就是对应着下一篇文章的 id
有了 id,查询出文章标题之类的信息还不是手到擒来?相信难不倒大家了,更深一步了解不妨 clone 源码瞧瞧!
小结
本文主要分享了博客文章创作和渲染这部分内容,由于本系列文章主要受众是前端开发,剖析前端的实现细节也显得不合适(你们肯定比我厉害),因此本文重在分析整体功能实现的思路以及数据库层面的设计,希望对大家有用,早日进阶!
有问题可以私我。















 1261
1261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}