






'''
Author: yang youzi
Date: 2023-12-27 11:31:00
LastEditors: yang youzi
LastEditTime: 2023-12-29 20:03:47
FilePath: \Product_planning_and_scheduling-master\GAtrial.py
Description: 1、首先生成邻接矩阵,2、然后生成初始化样本,3、接着选择精英样本,4、再选择可供交叉和变异的样本,5、然后进行交叉和变异重复该国程
'''
import numpy as np
import pandas as pd
import random
import matplotlib.pylab as plt
# 读取tsp坐标文档方法
def readfile():
file=pd.read_csv("./tsp/dj38.tsp",sep=" ",header=None,skiprows=10)
file[0]=file[0]-1
return file
# 计算各城市的邻接矩阵
def generate_distance_matrix(file):
city_num=len(file)
# 生成全为0的n*n矩阵
distance_matrix=np.zeros((city_num,city_num))
# 将矩阵的值都更新为点的距离,欧氏距离公式
for i in range(city_num):
for j in range(city_num):
x=np.power((file.iloc[i][1]-file.iloc[j][1]),2)
y=np.power((file.iloc[i][2]-file.iloc[j][2]),2)
distance_matrix[i][j]=np.sqrt(x+y)
return distance_matrix
# 初始化种群,生成可能的解
def init_population(file):
city_num=len(file)
species=200
population=[]
for i in range(species):
temp_dict=np.random.permutation(range(city_num)).tolist()
# 加入第一个元素到末尾形成闭环
temp_dict.append(temp_dict[0])
if temp_dict not in population:
population.append(temp_dict)
return population
# 定义适应度函数,计算单个个体适应度
def fitness(population,distance_matrix):
total_distance=0
for i in range(len(population)-1):
# 下一个地点位置
k=population[i+1] % len(population)
total_distance+=distance_matrix[population[i]][k]
return 1/total_distance
# 交叉方法
def cross(sample1,sample2):
city_num=len(sample1)
choice_sample=[i for i in range(city_num)]
cross_position=random.choice(choice_sample)
child1=sample1[0:cross_position]
child2=sample2[0:cross_position]
child1.extend(sample1[cross_position:city_num])
child2.extend(sample2[cross_position:city_num])
temp1=[]
temp2=[]
# 对交叉后重复值进行重新整理
for i in range(cross_position,city_num):
for j in range(cross_position):
if child1[i]==child1[j]:
temp1.append(j)
if child2[i]==child2[j]:
temp2.append(i)
cross_n=len(temp1)
for k in range(cross_n):
child1[temp1[k]],child2[temp2[k]]=child2[temp2[k]],child1[temp1[k]]
return child1,child2
#变异方法
def mutuate(sample):
sample_len=len(sample)
chioces=np.random.choice(sample_len,2)
if chioces[0]>chioces[1]:
mins=chioces[1]
maxs=chioces[0]
else:
mins=chioces[0]
maxs=chioces[1]
resultsample=sample[0:mins]
midsample=list(reversed(sample[mins:maxs]))
resultsample.extend(midsample)
resultsample.extend(sample[maxs:])
return resultsample
# 生成选择概率
def compute_choice_prob(populations,distance_matrix):
prob_list=[]
for i in range(len(populations)):
prob_list.append(fitness(populations[i],distance_matrix))
sig=sum(prob_list)
choice_prob = (prob_list / sig).tolist()
return choice_prob
# 选择需要进行交叉和变异的样本
def choice_newsample(species,initx,choice_prob):
# 重新选择样本
newx=[]
index = [i for i in range(species)]
news = random.choices(index,weights=choice_prob,k=int(0.8*species))
newsnum = len(news)
for i in range(newsnum):
newx.append(initx[news[i]])
return newx
# 选择精英样本
def choice_elite(species,choice_prob,population):
topk=int(species*0.2)
num_dict = {}
for i in range(len(choice_prob)):
num_dict[i] = choice_prob[i]
res_list = sorted(num_dict.items(),key=lambda e:e[1]) #e[1]表示按值排序,e[0]表示按键排序
elite = [one[0] for one in res_list[::-1][:topk]]
elite_list=[]
for i in elite:
elite_list.append(population[i])
return elite_list
def main():
file=readfile()
distance_matrix=generate_distance_matrix(file)
init_populations=init_population(file)
species=200
inters=5000
populations=init_populations
result=[]
cts=[]
for inter in range(inters):
# 计算样本适应度值
choice_prob=compute_choice_prob(populations,distance_matrix)
# 计算选择的精英样本
elite_population=choice_elite(species,choice_prob,populations)
# 计算选择的变异样本
choice_newsamples=choice_newsample(species,populations,choice_prob)
# 对变异样本进行变异选择
num=int(len(choice_newsamples)/2)
for i in range(num):
j=i+num-1
if random.choice([1,2,3,4,5,6,7,8,9,10])<8:
sample1=choice_newsamples[i][0:len(populations[0])-1]
sample2=choice_newsamples[j][0:len(populations[0])-1]
sample1,sample2=cross(sample1,sample2)
if random.choice([1,2,3,4,5,6,7,8,9,10])<4:
sample1=mutuate(sample1)
sample2=mutuate(sample2)
sample1.append(sample1[0])
sample2.append(sample2[0])
choice_newsamples[i],choice_newsamples[j]=sample1,sample2
populations=[]
populations.extend(elite_population)
populations.extend(choice_newsamples)
res=[]
for k in range(len(populations)):
res.append(fitness(populations[k],distance_matrix))
result.append(1/max(res))
cts.append(inter)
return populations,result,cts
if __name__=='__main__':
file=readfile()
populations,result,cts=main()
graph1=[]
graph2=[]
for i in range(len(populations[0])):
graph1.append(file.iloc[populations[0][i],1])
graph2.append(file.iloc[populations[0][i],2])
plot=plt.plot(graph1,graph2,c='r')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
print(cts,result)
plot = plt.plot(cts, result)
plt.xlabel('inters')
plt.ylabel('distance')
plt.show()
1、题目内容:求解最短路径
2、 数据下载地址:http://www.math.uwaterloo.ca/tsp/world/countries.html#DJ
3、最短路径如下:
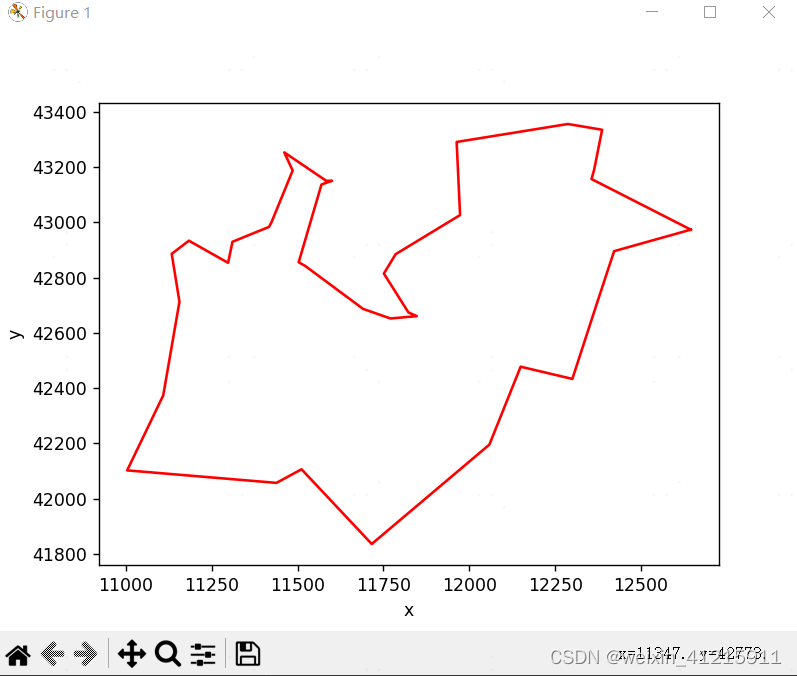
4、迭代效果如下:

















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









